
목록교내 수업/Machine Learning (11)
working_helen
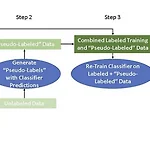 [ Week 11-2 ] with Insufficient Data / Semi-supervised learning, Active learning
[ Week 11-2 ] with Insufficient Data / Semi-supervised learning, Active learning
Lecture : Machine LearningDate : week 11, 2024/05/16Topic : With Insufficient Data 1. data augmentation2. Self training3. Active learning 1. data augmentation (데이터 증강)- expand labeled train data- 기존 데이터셋을 활용해 추가 합성 데이터를 인위로 생성하는 기법 - 데이터 셋의 규모를 키워 모델을 훈련에 필요한 충분한 수의 데이터를 확보하기 위해 사용 - 데이터 증강은 사용하는 데이터의 종류에 따라 특성이 달라지며, 다양한 기법이 존재한다. 2024.01.06 - [deep daiv./추천시스템 프로젝트] - [text 감정 추출 모델] Data A..
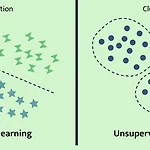 [ Week 11-1 ] Unsupervised learning / clustering, GMM, KDE
[ Week 11-1 ] Unsupervised learning / clustering, GMM, KDE
Lecture : Machine LearningDate : week 11, 2024/05/13 Topic : Unsupervised learning 1. Unsupervised learning 2. Clustering 3. k-means4. GMM5. KDE 1. Unsupervised learning Supervised learningUnsupervised learningtraining datausing labeled datasetusing unlabeled datasettrainmodel learns a function to relatebetween attributes and labels pairsmodel learns a function that producesuseful labels for..
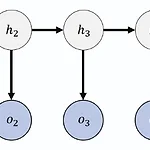 [ Week 9-1 ] Structured Classification
[ Week 9-1 ] Structured Classification
Lecture : Machine LearningDate : week 9, 2024/04/29Topic : Structured Classification 1. Markov chain & Markov model 2. Hidden Markov Model 3. Probability evaluation4. Optimal state sequence 1. Markov chain & Markov model 1) Markov chain(위키백과) 마르코프 연쇄(Markov chain)는 이산 시간 확률 과정이다. 마르코프 성질은 과거와 현재 상태가 주어졌을 때의 미래 상태의 조건부 확률 분포가 과거 상태와는 독립적으로 현재 상태에 의해서만 결정된다는 것을 뜻한다. 과거의 상태가 알려져 있더라도, 이는 미래 상태의..
 [ Week 7-2 ] Feature Selection
[ Week 7-2 ] Feature Selection
Lecture : Machine Learning Date : week 7, 2024/04/18 Topic : Feature Selection 1. Feature selection 2. Wrapper method 3. Filter method 4. Embedded method 1. Feature selection - 모델 학습에 불필요하고 관계없는 feautre는 제거하고 중요한 feature만을 사용하여 학습시키는 것 - 기존 데이터에서 최적의 모델의 성능을 보여주는 일부 feature subset을 찾아내 학습시키는 것 - 모델 성능을 높일 수 있을 뿐만 아니라 학습에 필요한 메모리와 시간을 줄일 수 있다는 점에서 중요함 - 변수 선택 기법 Wrappers method : 모델이 가장 좋은 성능을 보이..
 [ Week 7-1 ] Classifier combination
[ Week 7-1 ] Classifier combination
Lecture : Machine LearningDate : week 7, 2024/04/15Topic : Classifier combination 1. Classifier combination 2. Voting3. Bagging4. Boosting5. Stacking 1. Classifier combination 1) Ensemble learning (앙상블 학습)- 좋은 성능을 얻기 위해 다수의 모델을 종합적으로 사용하는 것 - 약한 예측모형 weak learner : 랜덤하게 예측하는 것보다 약간 좋은 예측력을 지닌 모형 - 여러개의 약한 기본모형(week base model, base learner)을 결합하여 강한 모형(strong learner)을 생성- strong leaner를 이..
 [ Week 4-2 ] Decision Tree, ID3 algorithm
[ Week 4-2 ] Decision Tree, ID3 algorithm
Lecture : Machine LearningDate : week 4, 2024/03/21Topic : Decision Tree 1. Decision Tree 2. ID3 1) ID3 algorithm 2) Entropy와 Information Gain 3) ID3 Decision Tree 예제 4) Information Gain Ratio 1. Decision tree 의사결정 나무 - 특정 변수와 변수값을 기준으로 분기 > 데이터의 영역을 나누어 결과를 구분하는 모델 - 분기 이후 불순도(Impurity) 값이 가장 많이 감소하는(정확도가 증가하는) 방향으로 분기 - 불순도 지표 : 엔트로피(entropy), 지니계수(Gini Index) 등 Why? 왜 불순도가 감소하는 ..
 [ Week 3-2 ] Discretisation, Naive Bayes with continuous variable
[ Week 3-2 ] Discretisation, Naive Bayes with continuous variable
Lecture : Machine LearningDate : week 3, 2024/03/14Topic : Naive Bayes with continuous variable 1. Discretisation 1) Discretisation 이산화 2) 이산화의 장단점 3) 이산화 방법2. Naive Bayes with continuous variable 1. Discretisation1) Discretisation 이산화continuous numeric attributes → discrete nominal attributes연속형(수치형) 변수를 이산형(범주형) 변수로 변환하는 과정 - nominal valeu(interval)의 개수를 정하고, 그 개수만큼 boundaries를 선정한다...
 [ Week 3-1 ] Instance-based Learning KNN
[ Week 3-1 ] Instance-based Learning KNN
Lecture : Machine LearningDate : week 3, 2024/03/11Topic : Instance-based Learning 1. Instance-based Learning 2. KNN 1) KNN 2) Tie breaking 방법 3) weighted KNN 4) 장단점 1. Instance-based Learning (사례 기반 학습) - 모델이 훈련 데이터를 기억한 상태에서, 새로운 input을 기존의 훈련 데이터와 비교해 가장 유사한 instance를 찾아내는 방식으로 일반화- labeled data가 필요한 지도학습의 한 방법으로, instance 간 유사도를 측정하기 위해 유사도 함수를 선택해야한다. - KNN을 비롯한 Nearest Neighbo..
 [ Week 2-2 ] Naive Bayes Model
[ Week 2-2 ] Naive Bayes Model
Lecture : Machine LearningDate : week 2, 2024/03/07Topic : Naive Bayes Model 1. Bayes' Rule2. Naive Bayes Model 1) Model's Assumption 2) Model's Prediction 3) Smoothing 4) 장단점3. Naive Bayes Model 예제 1. Bayes' Rule (베이즈 정리): 주어진 데이터로부터 Posterior Probability를 계산하기 위한 식 X : Observation, 가지고 있는 instance 데이터Θ : Hypothesis, 데이터로 예측하려는 값 P(X) : Marginal probability, likelihood of observing ..
 [ Week 2-1 ] types of attribute / probability / Entropy
[ Week 2-1 ] types of attribute / probability / Entropy
Lecture : Machine Learning Date : week 2-1, 2024/03/04 Topic : Probability 1. types of Attribute 2. Probability Model 3. Entropy 1. types of Attribute Categorical (Normal) variable : discrete + no ordering, boolean type도 포함 Ordinal variable : discrete value + natural ordering, mathematical operations 적용 X Continous (Numerical) variable : real-valued, mathematical operations 적용 O - Oridinal 변수는 수..