
working_helen
[ Week 7-1 ] Classifier combination 본문
Lecture : Machine Learning
Date : week 7, 2024/04/15
Topic : Classifier combination
1. Classifier combination
2. Voting
3. Bagging
4. Boosting
5. Stacking
1. Classifier combination
1) Ensemble learning (앙상블 학습)
- 좋은 성능을 얻기 위해 다수의 모델을 종합적으로 사용하는 것
- 약한 예측모형 weak learner : 랜덤하게 예측하는 것보다 약간 좋은 예측력을 지닌 모형
- 여러개의 약한 기본모형(week base model, base learner)을 결합하여 강한 모형(strong learner)을 생성
- strong leaner를 이용하여 최종적으로 예측함으로써 단일모형의 불안정성을 극복하고 예측력을 향상
2) Ensemble learning 기법
- Voting (투표) : 다수결 투표를 통해 예측 결과를 결정하는 방법, 하드 보팅(Hard Voting)/소프트 보팅(Soft Voting)
- Bagging (Bootstrap Aggregating, 배깅) : 부트스트랩 샘플링을 사용하여 여러 개의 부분 데이터셋을 만든 후 각 데이터셋 부분에 대해 병렬적으로 학습한 모델들의 예측 결과를 voting하는 방법, 대표적으로 랜덤포레스트
- Boosting (부스팅) : 이전 학습 결과를 바탕으로 데이터 가중치를 설정함으로써 약한 모델들을 순차적으로 학습시켜 강력한 모델을 만드는 방법, 대표적으로 AdaBoost, Gradient Boosting, XGBoost
- Stacking (스태킹) : 서로 다른 모델들의 예측 결과를 새로운 학습 데이터로 사용하는 최종 메타 모델을 만드는 방법
3) Bias & Variance
① Bias (편향) : 모델의 예측값과 실제값과의 차이의 평균

- 예측값이 실제 정답값과 평균적으로 얼마나 떨어져 있는지를 나타내는 지표
- Bias가 높으면 예측값과 실제값의 차이가 크다는 의미
= 모델이 데이터를 제대로 학습되지 못하는 underfitting 문제가 발생
② Variance (분산) : 모델 예측값의 분산
- 모델의 예측값이 얼마나 퍼져있는지, 변화할 수 있는지 나타내는 지표
- Variance가 높으면 모델이 학습 데이터에 지나치게 맞춰져 있다는 의미
= 모델이 새로운 데이터를 일반화하지 못하는 overfitting 문제가 발생
- bias가 높을수록 정확도가 떨어지고, variance가 높을수록 예측값의 분산이 커진다.
- bias와 variance는 trade-off 관계이며, 두 값이 모두 낮아야 좋은 모델이 된다.
- ML 모델의 학습 error를 평가하기 위해 bias와 variance 값을 사용한다.
2. Voting
- 다수결 투표를 통해 예측 결과를 결정하는 방법
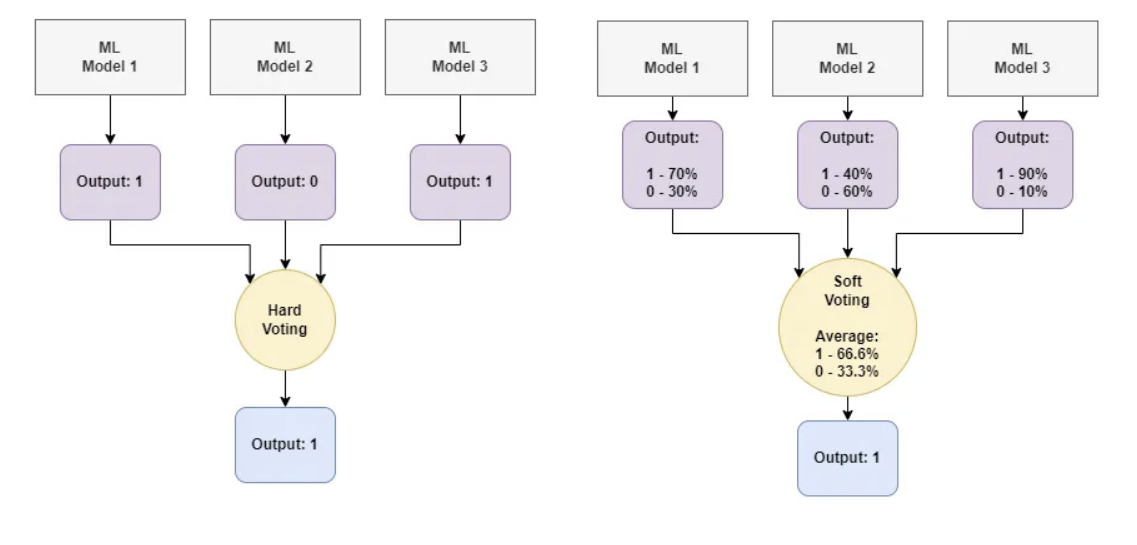
- 하드 보팅(Hard Voting) : 다수의 Classifier가 예측한 label을 선택
- 소프트 보팅(Soft Voting) : 각 Classifier들의 label별 예측 확률의 평균값을 계산하여 확률이 가장 높은 label을 선택
3. Bagging
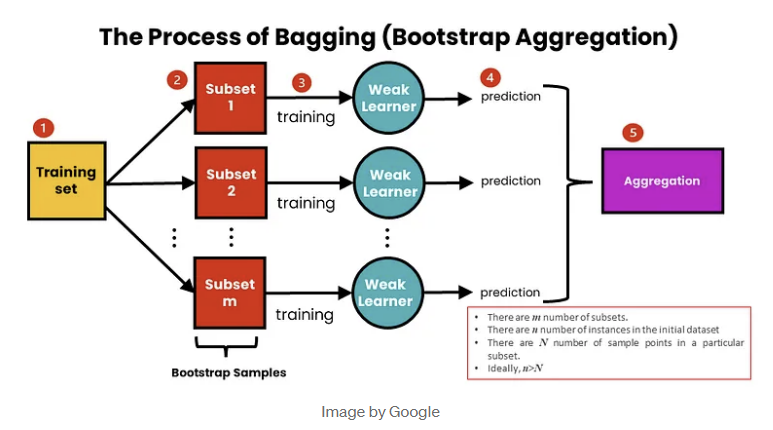
- 훈련 데이터셋에서 여러개의 랜덤 복원 추출한 데이터셋를 생성
→ 각 데이터셋마다 base classifier를 학습
→ 여러 Classifier의 voting을 이용해 최종 예측 결과를 결정하는 방식
- Voting에서는 base classifier로 여러 종류의 분류 모델을 사용하나, Bagging에서는 한 종류의 분류 모형만 사용
- Random Forest는 의사결정나무를 base classifier로 하는 배깅 기법의 앙상블 모델
서로 다른 bagged train dataset으로 학습한 의사결정나무들의 voting을 통해 최종 예측 결과를 결정
4. Boosting
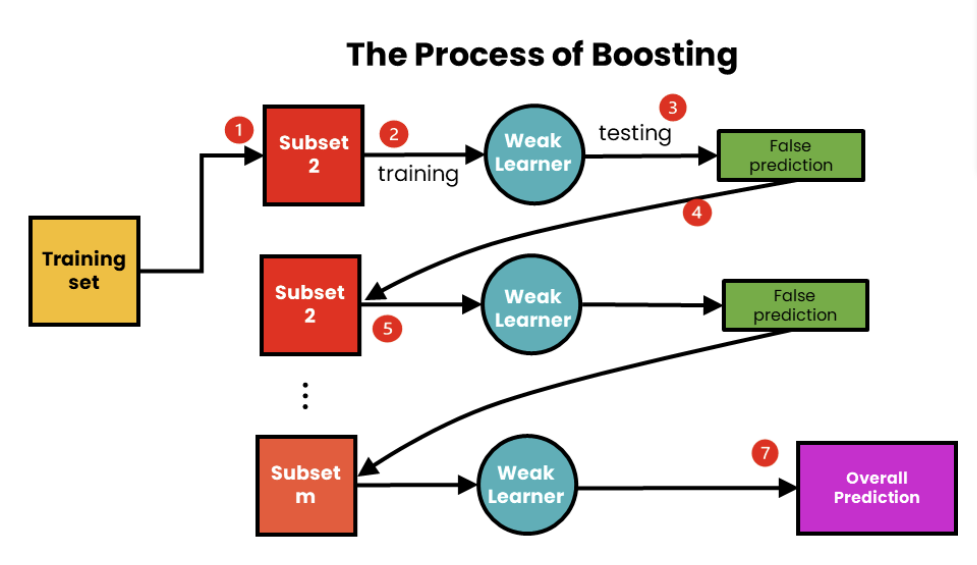
- 이전 학습 결과를 바탕으로 데이터 가중치를 설정함으로써 base classifier를 순차적으로 학습시키는 방법
- 이전 base classifier가 오분류한 데이터에 가중치를 더 주어 샘플링한 학습 데이터로 학습시킨 다음 모델을 생성
→ 전체 base classifier들을 결합하여 오분류되었던 데이터도 잘 분류하는 strong model을 생성하는
- 부스팅의 일반적인 과정
> y를 예측하는 learner(=model=hypothesis) H1을 만든다.
> H1의 성능을 판단한다
> H1의 성능을 보강할 수 있는 새로운 weak learner H2를 만들고 성능을 판단한다.
> 모든 weak learner의 weighted sum을 strong learner H로 정의한다.
H에 반영되는 각 Hx의 가중치는 Hx의 성능이 높을수록 높아진다.
> H의 성능이 만족스러울 때까지 Step 2~4를 반복한다.
- 부스팅의 두가지 접근 방식
- 이전 모델에서 틀린 데이터에 대해 weight를 주는 방식 => Adaboosting
- loss function 등을 이용해 정답과 오답 간 차이를 반복적으로 학습하는 방식 (gradient를 이용해 모델을 개선)
=> Gradient Boost, XGBoost, LightGBM 등
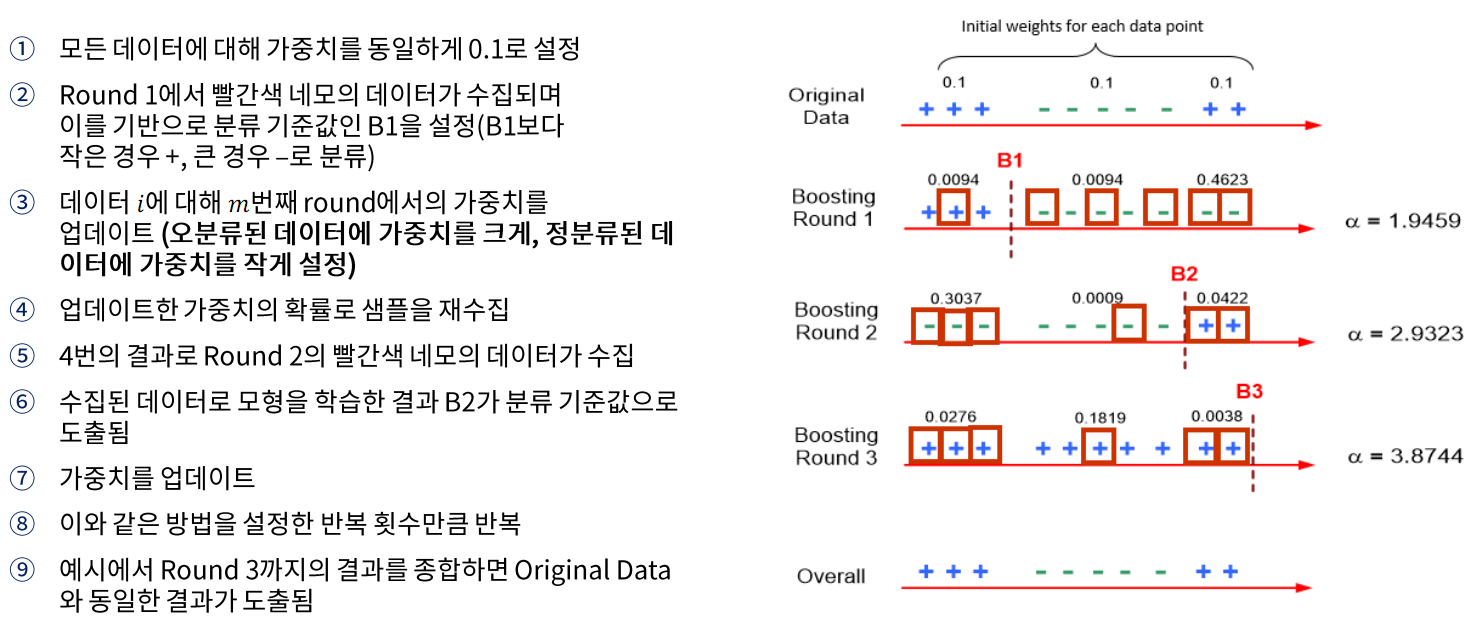
1) Adaboosting
- 이전 모델이 정답을 맞췄는지 여부에 따라 각 instance마다 서로 다른 weight를 부여
→ 다음 모델에게 오분류된 데이터를 더 학습시키는 기법
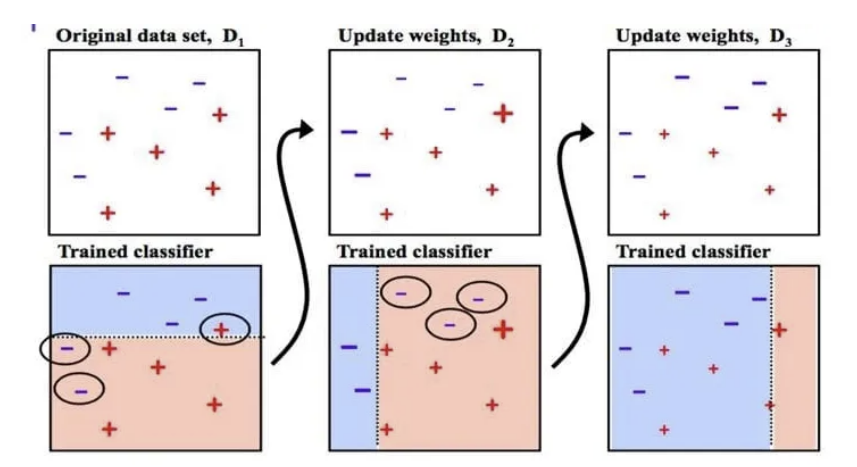
- 초기 가중치
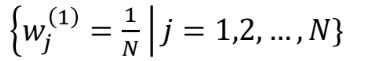
- i번째 week learner의 error rate
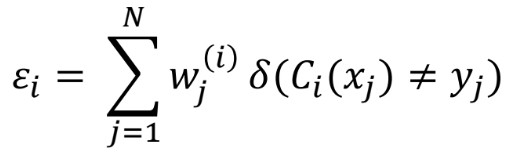
- i번째 week learner의 가중치
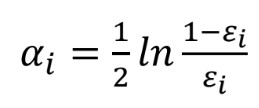
- i+1번째 학습 데이터에서 j번째 데이터의 가중치
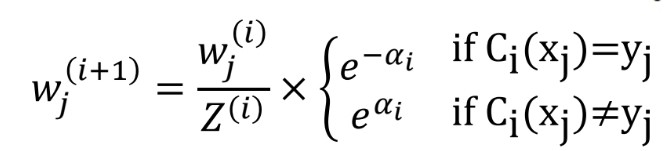
- 최종 strong learner
: 각 week learner마다 (모델의 가중치)*(예측 결과) 합을 계산하여 가장 확률이 높은 label을 선택
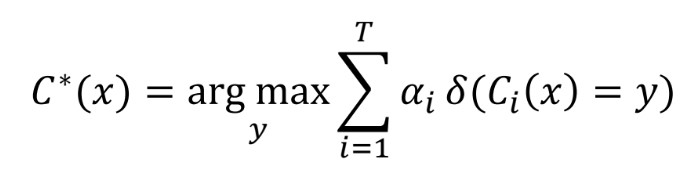
2) Gradient Boosting
- 그라디언트 부스팅(Gradient Boosting) = 경사하강법(Gradient Descent) + 부스팅(Boosting)
- 정답값 y가 아닌 잔차를 label로 설정해서 학습하는 기법
- 기존 모델의 잔차를 예측하는 새로운 weak learner를 재귀적으로 생성
→ 이들을 종합하여 원래 데이터를 예측하는 최종 분류기 strong learner를 생성
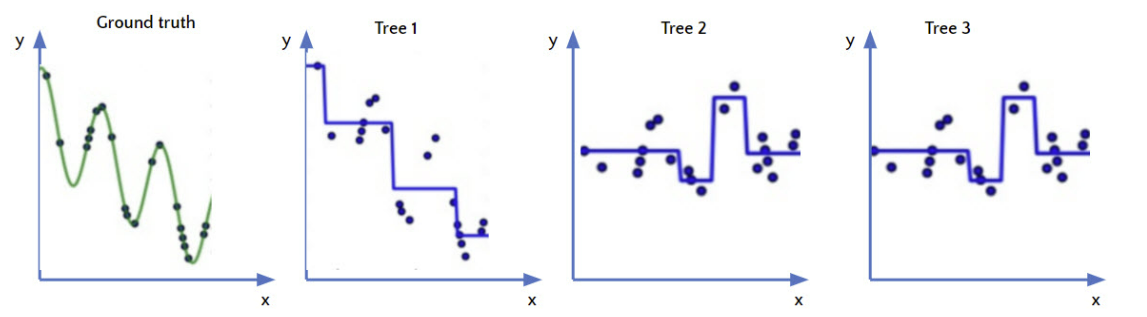
- week learner A를 통해 y를 예측하고 남은 잔차(residual)를 다음 week learner B로 예측하고, A+B 모델을 통해 y를 예측하여 A보다 잔차가 줄어든 더 나은 모델을 생성
- LightGBM, CatBoost, XGBoost 같은 파이썬 패키지들이 모두 Gradient Boosting Algorithm을 구현한 패키지
- Gradient Boosting 알고리즘은 속도가 느리고 과적합이 일어날 수 있는 단점 => XGBoost => LightGBM으로 발전
5. Stacking
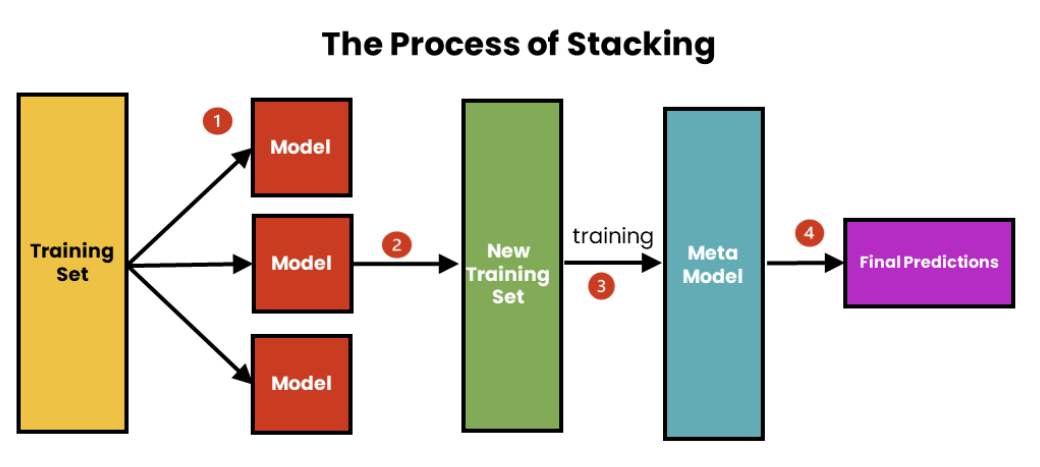
- 주어진 학습 데이터를 다양한 알고리즘으로 학습시킨 level-0 classifiers들을 생성
→ 모델들의 예측 결과를 새로운 메타 학습 데이터로 사용해 최종 예측을 수행하는 level-1 classifier 학습
- level-1 classifier의 메타 학습 데이터는 level-0 classifiers의 예측값을 기반으로 한 새로운 attribute를 가짐
- base classifier로 여러 종류의 분류 알고리즘을 사용함으로써 알고리즘의 다양성으로 error를 줄이려는 접근 방식
※ Bagging vs Boosting
| Bagging | Boosting |
| multiple base model을 aggregate | sequential base model에 서로 다른 weight 부여 |
| Parallel Sampling 랜덤 복원 샘플링한 여러개의 데이터셋을 동시에 생성 |
Iterative sampling 다음 week learner을 학습시킬 때마다 반복적으로 샘플링 |
| Simple Voting | Weighted Voting, 각 week learner마다 가중치 존재 |
| 학습 데이터에 randomness 부여 --> Minimise variance --> overfitting 방지 |
모델 예측의 정확성을 높임 --> Minimise instance bias --> underfitting 방지 |
- bagging : overfitting reduce 역할
- boosting : underfitting reduce 역할
- stacking : model error를 감소시키는 역할
Jupyter notebook
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, f1_score
from sklearn.metrics import classification_report, confusion_matrix, precision_recall_curve, roc_curve
from sklearn.preprocessing import StandardScaler, Binarizer
from sklearn.linear_model import LogisticRegressionfrom sklearn.dummy import DummyClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB, MultinomialNBdata 불러오기
car = pd.read_csv('car.data')
car.head()
| vhigh | vhigh.1 | 2 | 2.1 | small | low | unacc | |
|---|---|---|---|---|---|---|---|
| 0 | vhigh | vhigh | 2 | 2 | small | med | unacc |
| 1 | vhigh | vhigh | 2 | 2 | small | high | unacc |
| 2 | vhigh | vhigh | 2 | 2 | med | low | unacc |
| 3 | vhigh | vhigh | 2 | 2 | med | med | unacc |
| 4 | vhigh | vhigh | 2 | 2 | med | high | unacc |
for col in car.columns:
print(car[col].unique())['vhigh' 'high' 'med' 'low']
['vhigh' 'high' 'med' 'low']
['2' '3' '4' '5more']
['2' '4' 'more']
['small' 'med' 'big']
['med' 'high' 'low']
['unacc' 'acc' 'vgood' 'good']- data 불러와서 범주형 column들을 one-hot encoding 하는 함수 정의
- X = instance 1728개, one-hot encoding 결과 열이 4*3 + 3*3= 21개로 변환된 학습 데이터
from sklearn.preprocessing import OneHotEncoder
def load_data(i_file):
X = []
y = []
with open(i_file, mode='r') as fin:
for line in fin:
atts = line.strip().split(",")
X.append(atts[:-1])
y.append(atts[-1])
onehot = OneHotEncoder()
X = onehot.fit_transform(X).toarray()
return X, y
X, y = load_data('car.data')
# instance 1728개, feature 21개
X.shape
(1728, 21)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
print(X_train.shape, X_test.shape)
(1157, 21) (571, 21)
Stacking 방법 1
level-0 ML 모델 학습
classifiers = [DummyClassifier(strategy='most_frequent'),
LogisticRegression(),
KNeighborsClassifier(),
GaussianNB(),
MultinomialNB()]
titles = ['Zero_R',
'Logistic Regression',
'KNN',
'Gaussian NB',
'Multinomial NB']
zero_clf = DummyClassifier(strategy='most_frequent')
lg_clf = LogisticRegression()
knn_clf = KNeighborsClassifier()
gnn_clf = KNeighborsClassifier()
mnn_clf = MultinomialNB()
zero_clf.fit(X_train, y_train)
lg_clf.fit(X_train, y_train)
knn_clf.fit(X_train, y_train)
gnn_clf.fit(X_train, y_train)
mnn_clf.fit(X_train, y_train)
level-0 모델 예측, meta data 생성
- 5가지 level-0 모델은 각 instande가
['unacc' 'acc' 'vgood' 'good']4가지 label에 속할 확률을 예측 - 5가지 모델 * 4가지 label = 20가지 예측 확률을 새로운 feauture로 사용
- 예측 결과가 columns에 오도록 5가지 모델의 predict_pred 결과를 수평 결합
zero_pred_tr = zero_clf.predict_proba(X_train)
lg_pred_tr = lg_clf.predict_proba(X_train)
knn_pred_tr = knn_clf.predict_proba(X_train)
gnn_pred_tr = gnn_clf.predict_proba(X_train)
mnn_pred_tr = mnn_clf.predict_proba(X_train)
meta_data_tr = []
meta_data_tr.append(zero_pred_tr)
meta_data_tr.append(lg_pred_tr)
meta_data_tr.append(knn_pred_tr)
meta_data_tr.append(gnn_pred_tr)
meta_data_tr.append(mnn_pred_tr)
# 5개의 2차원 배열을 수평으로 연결하여 하나의 2차원 배열로
meta_data_tr = np.concatenate(meta_data_tr, axis=1)
print(zero_pred.shape)
print(meta_data.shape)
(1157, 4)
(1157, 20)
zero_pred_test = zero_clf.predict_proba(X_test)
lg_pred_test = lg_clf.predict_proba(X_test)
knn_pred_test = knn_clf.predict_proba(X_test)
gnn_pred_test = gnn_clf.predict_proba(X_test)
mnn_pred_test = mnn_clf.predict_proba(X_test)
meta_data_test = []
meta_data_test.append(zero_pred_test)
meta_data_test.append(lg_pred_test)
meta_data_test.append(knn_pred_test)
meta_data_test.append(gnn_pred_test)
meta_data_test.append(mnn_pred_test)
# 5개의 2차원 배열을 수평으로 연결하여 하나의 2차원 배열로
meta_data_test = np.concatenate(meta_data_test, axis=1)
print(zero_pred_test.shape)
print(meta_data_test.shape)
(571, 4)
(571, 20)
level-1 모델 학습
lr_meta = LogisticRegression()
lr_meta.fit(meta_data_tr, y_train)
LogisticRegression()On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()level-1 모델 예측 & Stacking 전 level-0 모델과 정확성 비교
final_pred = lr_meta.predict(meta_data_test)
print(classification_report(y_test, final_pred))
precision recall f1-score support
acc 0.80 0.89 0.84 122
good 0.77 0.40 0.53 25
unacc 0.98 0.97 0.97 403
vgood 1.00 0.90 0.95 21
accuracy 0.93 571
macro avg 0.88 0.79 0.82 571
weighted avg 0.93 0.93 0.93 571
print("Zero_R 정확도 :\n", classification_report(y_test, zero_clf.predict(X_test)))
print("Logistic 정확도 :\n", classification_report(y_test, lg_clf.predict(X_test)))
print("KNN 정확도 :\n", classification_report(y_test, knn_clf.predict(X_test)))
print("Gausian NB 정확도 :\n", classification_report(y_test, gnn_clf.predict(X_test)))
print("Multinomial NB 정확도 :\n", classification_report(y_test, mnn_clf.predict(X_test)))
Zero_R 정확도 :
precision recall f1-score support
acc 0.00 0.00 0.00 122
good 0.00 0.00 0.00 25
unacc 0.71 1.00 0.83 403
vgood 0.00 0.00 0.00 21
accuracy 0.71 571
macro avg 0.18 0.25 0.21 571
weighted avg 0.50 0.71 0.58 571
Logistic 정확도 :
precision recall f1-score support
acc 0.77 0.84 0.80 122
good 0.75 0.36 0.49 25
unacc 0.96 0.97 0.97 403
vgood 1.00 0.86 0.92 21
accuracy 0.91 571
macro avg 0.87 0.76 0.79 571
weighted avg 0.91 0.91 0.91 571
KNN 정확도 :
precision recall f1-score support
acc 0.66 0.80 0.72 122
good 0.67 0.08 0.14 25
unacc 0.94 0.96 0.95 403
vgood 1.00 0.43 0.60 21
accuracy 0.87 571
macro avg 0.82 0.57 0.60 571
weighted avg 0.87 0.87 0.85 571
Gausian NB 정확도 :
precision recall f1-score support
acc 0.66 0.80 0.72 122
good 0.67 0.08 0.14 25
unacc 0.94 0.96 0.95 403
vgood 1.00 0.43 0.60 21
accuracy 0.87 571
macro avg 0.82 0.57 0.60 571
weighted avg 0.87 0.87 0.85 571
Multinomial NB 정확도 :
precision recall f1-score support
acc 0.66 0.75 0.70 122
good 0.50 0.12 0.19 25
unacc 0.94 0.97 0.95 403
vgood 1.00 0.38 0.55 21
accuracy 0.87 571
macro avg 0.77 0.56 0.60 571
weighted avg 0.86 0.87 0.85 571
Stacking 방법 2
classifiers: level-0 classifier로 사용할 base model 목록_predict_base: level-0 classifiers의 예측 결과를 모아서 meta train data를 생성하는 methodfit,predict,score: meta model을 학습, 예측, 평가하는 method- 참고) DummyClassifier
주어진 데이터셋에서 설정한 전략에 따라 무작위 예측을 수행함. most_frequent: 가장 빈도가 높은 클래스로 예측 stratified: 훈련 데이터의 클래스 비율과 동일한 비율로 예측 uniform: 모든 클래스를 동일한 확률로 무작위로 선택하여 예측 constant: 사용자가 지정한 상수 값으로 예측
np.random.seed(30027)
class StackingClassifier():
def __init__(self, classifiers, metaclassifier):
# level-0 classifiers
self.classifiers = classifiers
# level-1 classifier
self.metaclassifier = metaclassifier
## meta X data 생성하기
def _predict_base(self, X):
# level-0 classifiers 예측결과 모으기
yhats = []
for clf in self.classifiers:
yhat = clf.predict_proba(X)
yhats.append(yhat)
# yhats 안에 있는 배열들을 수평으로 결합해서 2차원 배열로
yhats = np.concatenate(yhats, axis=1)
assert yhats.shape[0] == X.shape[0]
return yhats
## meta model 학습하기
def fit(self, X, y):
# level-0 classifiers 학습
for clf in self.classifiers:
clf.fit(X, y)
# 학습한 level-0 classifiers 예측 -> meta train data 생성
X_meta = self._predict_base(X)
# 생성된 meta train data로 level-1 model 학습
self.metaclassifier.fit(X_meta, y)
## meta model 예측하기
def predict(self, X):
X_meta = self._predict_base(X)
yhat = self.metaclassifier.predict(X_meta)
return yhat
## meta model 평가하기
def score(self, X, y):
yhat = self.predict(X)
return accuracy_score(y, yhat)
classifiers = [DummyClassifier(strategy='most_frequent'),
LogisticRegression(),
KNeighborsClassifier(),
GaussianNB(),
MultinomialNB()]
titles = ['Zero_R',
'Logistic Regression',
'KNN',
'Gaussian NB',
'Multinomial NB']
## level-1 model로 Logistic Regression 이용
meta_classifier_lr = LogisticRegression()
stacker_lr = StackingClassifier(classifiers, meta_classifier_lr)
## level-1 model로 DecisionTree 이용
meta_classifier_dt = DecisionTreeClassifier()
stacker_dt = StackingClassifier(classifiers, meta_classifier_dt)
for title,clf in zip(titles, classifiers):
clf.fit(X_train,y_train)
print(title, "Accuracy:",clf.score(X_test,y_test))
stacker_lr.fit(X_train, y_train)
print('\nStacker Accuracy (Logistic Regression):', stacker_lr.score(X_test, y_test))
stacker_dt.fit(X_train, y_train)
print('Stacker Accuracy (Decision Tree):', stacker_dt.score(X_test, y_test))
Zero_R Accuracy: 0.7057793345008757
Logistic Regression Accuracy: 0.9124343257443083
KNN Accuracy: 0.8686514886164624
Gaussian NB Accuracy: 0.8248686514886164
Multinomial NB Accuracy: 0.8651488616462347
Stacker Accuracy (Logistic Regression): 0.9246935201401051
Stacker Accuracy (Decision Tree): 0.9422066549912435
Reference
https://velog.io/@heyggun/ML-Bias%EC%99%80-Variance#2-variance
https://ilyasbinsalih.medium.com/what-is-hard-and-soft-voting-in-machine-learning-2652676b6a32
https://www.analyticsvidhya.com/blog/2023/01/ensemble-learning-methods-bagging-boosting-and-stacking/
https://helpingstar.github.io/ml/ensemble/#adaboost-%EC%97%90%EC%9D%B4%EB%8B%A4-%EB%B6%80%EC%8A%A4%ED%8A%B8
http://bigdata.dongguk.ac.kr/lectures/datascience/_book/%EC%95%99%EC%83%81%EB%B8%94-%EB%B0%A9%EB%B2%95.html#%EB%B0%B0%EA%B9%85-bagging
'교내 수업 > Machine Learning' 카테고리의 다른 글
| [ Week 9-1 ] Structured Classification (0) | 2024.05.06 |
|---|---|
| [ Week 7-2 ] Feature Selection (0) | 2024.04.21 |
| [ Week 4-2 ] Decision Tree, ID3 algorithm (0) | 2024.03.25 |
| [ Week 3-2 ] Discretisation, Naive Bayes with continuous variable (0) | 2024.03.22 |
| [ Week 3-1 ] Instance-based Learning KNN (0) | 2024.03.18 |



