
working_helen
[NLP] Language Model / n-gram, NNLM, RNNLM 본문

1. Language Model
2. n-gram Language Models
3. NNLM
4. RNN
1. Language Model (LM)
- 가능한 모든 word sequence에 대하여 확률을 계산하는 모델
- 이전 단어들이 주어졌을 때 특정 단어가 그 다음으로 올 확률을 계산하는 모델
- 이전 단어들로부터 다음 단어를 예측하는 모델
- 2가지 접근방식
- 통계적 언어 모델(Statistical Language Model, SLM) : n-gram
- 인공 신경망 언어 모델(Neural Network Based Language Model) : RNN
- w : 각각의 단어
- W : n개의 단어가 등장하는 word sequence = text
- n-1개의 word sequence 뒤에 n번째 단어의 확률

- text W가 등장할 확률

2. n-gram Language Models
1) n-gram
- n-gram : n개의 연속적인 word sequence, n개의 단어로 이루어진 text가 하나의 토큰
- n-gram LM은 Markov Assumption을 기반으로 text의 확률값을 계산
- Markov Assumption : n번째 단어는 오직 앞선 n-1개의 단어에만 영향을 받는다는 가정
- SLM의 일종으로, 갖고있는 데이터에서 각각의 n-gram이 등장하는 횟수 count를 이용해 확률 계산

2) n-gram trade-off
- n이 커지면, 현재 데이터에서 각각의 n-gram이 등장하는 count 값이 적어지므로 Sparsity 문제가 심각해지며, 모델 사이즈가 커져 Storage 문제도 발생한다.
- n이 작아지면, 각 n-gram의 count 값은 증가하지만 지나치게 적은 정보를 가지고 다음 단어를 예측하게 되면서 정확도가 떨어질 수 있다.
① Sparsity Problem
: 현재 데이터에 'boy is spreading w' 혹은 'boy is spreading' word sequence가 존재하지 않는 경우 count 값이 0이 되는 문제
② Storage Problem
: 가능한 모든 n-gram에 대하여 count 값을 계산하고 저장해야하기 때문에, n이 커지거나 corpus가 증가하면, 모델 사이즈가 커진다는 문제
③ incoherent
: n-1개의 단어만을 고려해 다음 단어를 예측하기 때문에, 전체 문장을 고려한 언어 모델에 비해 문맥을 잘 반영하지 못하면서 정확도가 떨어지는 문제
3. NNLM
1) NNLM (Feed Forward Neural Network Language Model, 피드 포워드 신경망 언어 모델)
- 인공 신경망 언어 모델의 시초
- 단어의 의미적 유사성을 사용함으로써 Sparity 문제를 해소한 언어 모델
- 단어의 의미를 포함하는 Word Embedding vector를 이용해 다음에 올 단어의 확률분포 예측
- n-gram에선 기존 데이터에 없던 word sequence는 count가 0이 되는 문제가 발생했었지만, NNLM의 경우 모델의 학습 데이터에 유의어가 있었다면 Word Embedding vector의 유사성에 의해 기존 데이터에 없던 sequence여도 다음 단어를 예측할 수 있다. Sparsity problem를 해소할 수 있다.
- 하지만 n-gram과 유사하게 고정된 개수(window)의 이전 단어만 사용하여 다음 단어 예측한다는 문제가 남아있다.
2) NNLM 구조

- x : 입력 단어의 one-hot vector
- e : 입력 단어의 embedding vector
- h : hidden layer

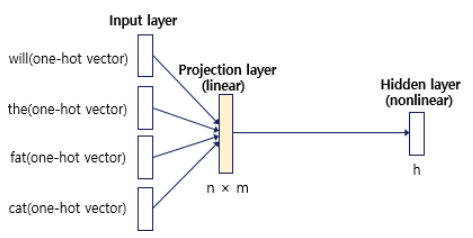
- window가 5일 때 'sit' 앞의 단어는 what, will, the, fat, cat
- 5개 단어를 이용해 다음 단어 'sit'을 잘 예측하는 가중치 W를 학습한다!
① input layer : 5개 단어들의 one-hot vector
② projection layer

- 각 one-hot vector를 word embedding vector로 전환 = look-up table
- 이때 Word2Vec과 같은 word embedding 방법 사용
- 모든 vector를 한 줄로 이어붙히는 연결 연산으로 concatenated vector 생성
- 활성화 함수를 사용하지 않는 linear layer
③ hidden layer
- concatenated vector를 입력으로 받음
- 은닉층 가중치 W를 곱하고 편향 b를 더함
- tanh 활성화 함수에 입력 (nonlinear layer)

④ output layer
- hidden layer의 output을 입력으로 받음
- 출력층 가중치 W를 곱하고 편향 b를 더함
- Softmax를 사용해 총합이 1이 되는 확률 벡터로 전환
- y_pred = 모델이 예측한 다음에 올 단어의 확률 분포
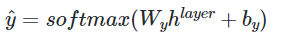
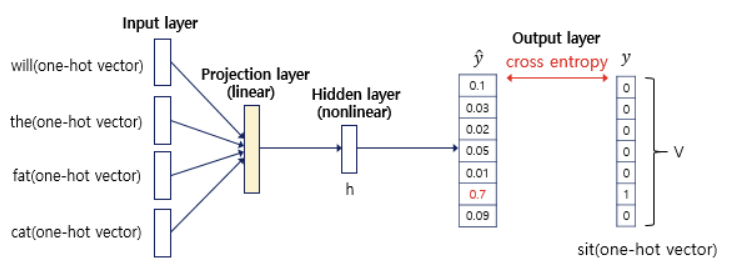
⑤ loss function & optimization
- E : 임베딩 행렬
- W_h : 은닉층 가중치
- W_y : 출력층 가중치
- cross-entropy loss 사용해 y_pred와 y_true를 비교하여 W_h, W_y, E를 업데이트
- y_pred를 가장 잘 예측하는 가중치 W를 학습
4. RNNLM
1) RNNLM (Recurrent Neural Network Language Model, RNN 언어 모델)
- RNN 구조를 언어 모델에 활용한 모델
- RNN의 teacher forcing 훈련 기법 : t step의 출력이 t+1 step의 입력으로 사용
- t step 시점의 hidden state는 이전 state의 모든 history를 저장 (capsulate all previous information)
- RNNLM 입력의 길이만큼 teacher forcing 과정을 계속 반복하여 학습할 수 있다.
- n-gram LM과 NNLM은 고정된 개수의 단어만 이용해 다음 단어를 예측한다는 단점이 있다. 하지만 RNN 언어 모델은 입력의 길이를 고정하지 않아도 되며, 입력의 길이가 길어져도 모델 크기는 W_e와 W_h로 고정되어 있기 때문에 크기가 커지지 않는다.
- 하지만 순차적인 계산을 반복해야 하므로 계산 속도가 매우 느리다는 단점이 있다.
2) RNNLM 구조

- x_t : t step 입력 단어의 one-hot vector
- e_t : t step 입력 단어의 embedding vector
- h_t : t step에서 hidden state, 이전 state의 모든 history를 저장
- h_0 : hidden state의 초기값, 일반적으로 0으로 초기화
① hidden state
- 현재 step t에서의 입력 e_t, 이전 state의 정보 h_(t-1)을 입력으로 받음
- 은닉층 가중치 W_e, W_h를 곱하고 편향 b_1이 더함
- tanh나 ReLU 활성화 함수에 입력 (nonlinear layer)

② output state
- 마지막 hidden layer의 output을 입력으로 받음
- 출력층 가중치 W_y를 곱하고 편향 b를 더함
- Softmax를 사용해 총합이 1이 되는 확률 벡터로 전환
- y_pred = 모델이 예측한 다음에 올 단어의 확률 분포

③ loss function & optimization
- W_e : 새로운 입력이 영향을 미치는 정도 가중치
- W_h : 현재까지 입력 history가 영향을 미치는 정도 가중치
- W_y : 출력층 가중치
- RNNLM은 모든 time step에서 동일한 가중치를 사용
- 모든 time step에서 cross-entropy loss 사용해 y_pred와 y_true 간 loss 계산
- T개 step에서의 loss 평균값으로 W_e와 W_h, W_y, E를 업데이트
- y_pred를 가장 잘 예측하는 가중치 W를 학습

Reference
https://wikidocs.net/21668
https://wikidocs.net/21692
https://velog.io/@hm1lee/lecture-6-Language-Models-and-RNNs
'교내 수업 > 인공지능' 카테고리의 다른 글
| [NLP] Word2Vec / Skip-gram, CBOW (0) | 2024.01.29 |
|---|---|
| [CNN] CNN 모델의 발전 (1) | 2024.01.21 |
| [CNN] Convolution Layer / Pooling layer (1) | 2024.01.21 |
| [CNN] Fully-Connected Layer (0) | 2024.01.19 |
| [Linear Algebra] SVD를 이용한 image compression (1) | 2024.01.19 |



