
working_helen
[CNN] Convolution Layer / Pooling layer 본문
CNN의 구성 요소
- Convolution Layer
- Pooling Layers
- Fully-Connected Layer
- Activation Function
- Normalization


CNN의 구성 요소 중 'Convolution Layer'와 'Pooling layer'에 대해 공부해본다.
1. Convolutional Neural Networks
2. Convolution layer 구조
3. convolution layer 계산
4. Pooling layer
1. Convolutional Neural Networks (CNN)
1) CNN의 등장 배경

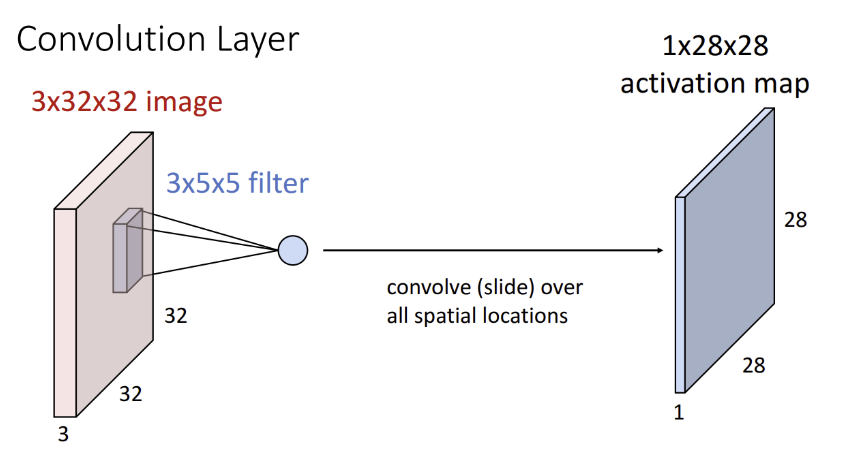
- Fully-Connected Layer만으로 구성된 Neural Networks는 1차원 벡터 형태의 input만 받을 수 있다.
- 위 그림과 같이 이미지 데이터를 input으로 사용하는 경우, 3차원 데이터를 1차원으로 평면화시키는 과정이 필요
- 이로 인해 변환 전에 가지고 있던, 이미지의 공간적인 구조(spatial structure)에 관한 정보가 손상
- 모델의 성능이 저하되는 문제가 발
==> 이미지의 공간 정보를 반영한 학습을 가능하게 만든 CNN
convolution layer = 더 좋은 이미지 feature extraction을 위해 사용
- 이미지를 바로 fully-connected layer의 input으로 사용하지 않고,
- convolution layer를 통해 feature extraction을 진행한 후 input으로 사용함으로써 정보 손실을 줄인 모델
2) CNN의 특징
- convolution filter를 통해 인접한 pixcel의 특징 반영함으로써 이미지의 공간 정보를 유지한 채로 학습 가능
- 여러개의 convolution filter를 사용해 이미지의 feature 추출
- 수백개의 convolution layer을 가질 수 있으며, 각 layer에선 이미지의 서로 다른 특징을 검출
- 그럼에도 모든 layer가 동일한 filter 파라미터를 사용하기 때문에 학습 파라미터가 매우 적음
3) CNN 구조
[ Feature Extraction : 이미지의 특징을 추출하는 부분 ]
① Convolution layer + Activation function
- input 이미지를 convolution fiter에 통과 → activation function 적용
- convolution fiter에서 이미지의 특정한 feature 추출
- 활성화 함수는 convolution layer 결과 임계치를 넘긴 픽셀의 값만 다음 계층에 전달
② Pooling layer
- 비선형 downsampling으로 다음 계층의 input 및 파라미터 차원을 감소시켜주는 역할
- convolution layer 뒤에 선택적으로 사용
[ Classification : 이미지 클래스를 분류하는 부분 ]
③ Flatten layer
- 3차원 이미지 데이터를 1차원 벡터 형태로 변환해주는 역할
- convolution layer의 output이 fully-connected layer의 input으로 사용될 수 있도록 차원 조정
④ Fully-connected layer
- feature extraction이 반영된 1차원 벡터 input을 받아
- 이미지 classification 결과값 계산
==> [ Image classfication 문제에서 CNN 모델 ]
Convolution layer에서 feature 추출
- input image → convolution + pooling → image feature matrix
- 각각의 pixcel을 중심으로, 주변 pixcel의 정보도 반영하여 이미지의 feature 추출
Neural Network Classification model로 분류
- image feature matrix → flatten → image feature vector
- image feature vector → fully-connected layer → 각 label에 속할 probability vector
- 정답값과 loss 구하면서 SGD with backpropagate로 optimization
각 layer의 중간 과정에서 activation function + batch normalization 적절히 활용
2. Convolution layer 구조
1) channel 채널
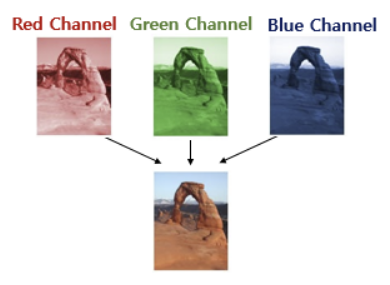
- 이미지 = '높이x너비x채널'로 구성된 3차원 tensor
- 이미지의 채널이란 색 성분을 의미
- 흑백 이미지는 1가지 채널, 컬러 이미지는 Red/Blue/Green 3가지 채널로 구성
- 각 pixcel마다 0~225 사이의 컬러값을 가짐
2) 필터(filter) / 커널(kernel)
- convolution layer에서 이미지의 feature를 찾아내기 위해 사용되는 공통 파라미터
- CNN에서 학습 대상은 필터 파라미터
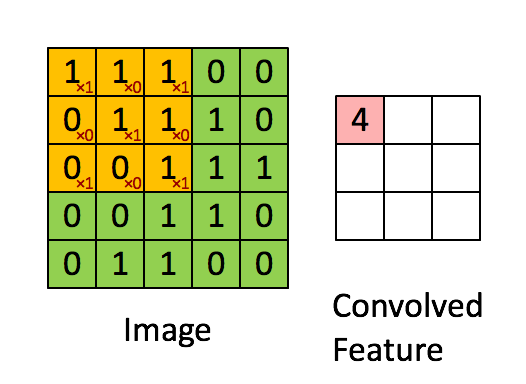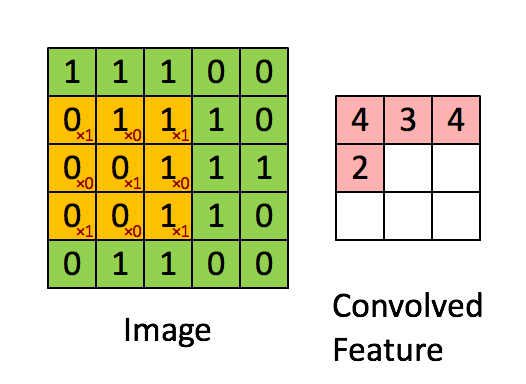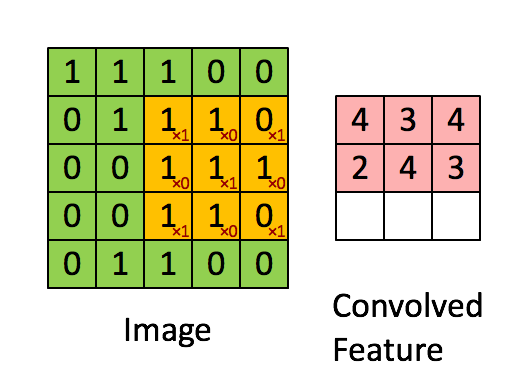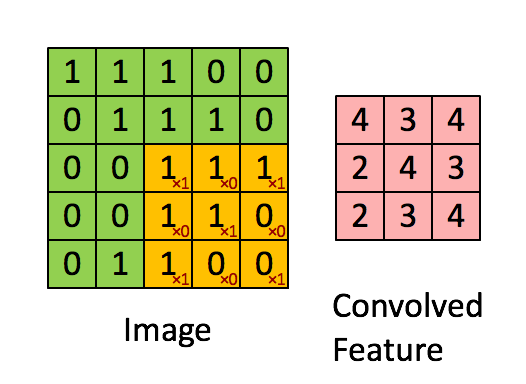
3) 합성곱 연산(Convolution operation)
- 필터를 이용해 높이x너비 크기의 input 이미지를 시작점부터 끝까지 훑으면서
(필터의 각 원소) x (필터와 겹쳐지는 위치의 이미지 원소) 값을 계산하고 모두 더한 값을
ouput 이미지의 해당 위치의 출력값으로 계산하는 과정
- input 이미지의 채널과 같은 크기의 채널을 가지는 filter를 사용
- Feautre map = 필터로 입력 데이터를 합성곱 한 결과
4) Stride와 Padding
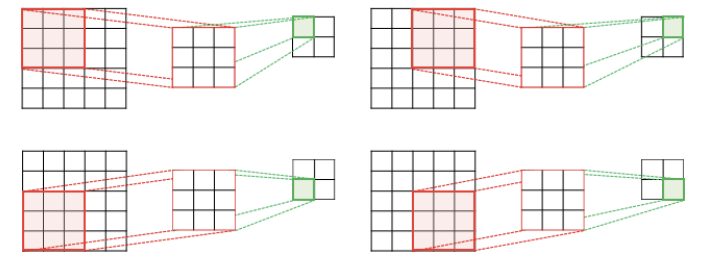
① Stride
- 합성곱 연산에서 필터는 일정한 간격으로 이미지 상에서 이동하며 계산을 진행
- Stride = 필터가 이동하는 일정한 간격
- 이미지 크기를 줄이는 일종의 Downsampling 기능
예시 : 5 × 5 이미지에 Stride가 2이고, 크기가 3 × 3인 필터로 합성곱 연산한 경우
2 × 2의 크기의 feature map을 output으로 생성
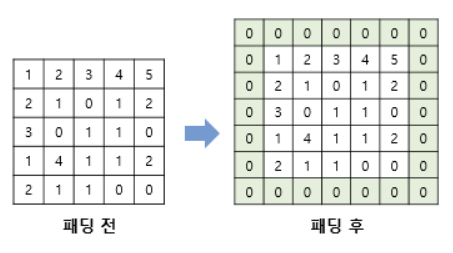
② Padding
- 합성곱 연산 결과, input 이미지보다 feature map의 크기가 더 작아지는 특성이 존재
- Padding = 합성곱 연산 이후에도 이미지 크기가 동일하게 유지되도록, 합성곱 연산 전 input 이미지의 가장자리 외각에 지정된 크기와 값(주로 0)을 가지는 pixcel을 추가해주는 과정
3. convolution layer 계산
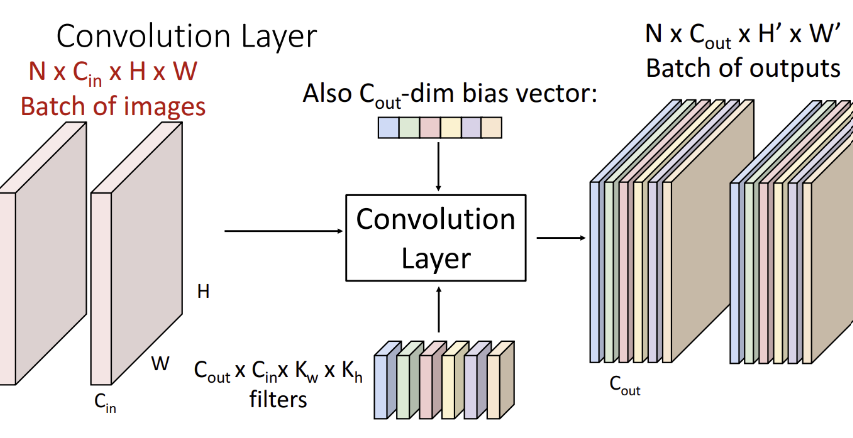
- H : input 이미지 높이
- W : input 이미지 너비
- S : Strid 크기
- P : padding 크기
- FH : filter 높이
- FW : filter 너비
- C_in : input 이미지의 채널
- C_out : 사용하는 filter 개수
- OH : output 이미지의 높이
- OW : output 이미지의 너비
- N : 이미지 데이터 batch 크기
1) shape of filter
- 하나의 convolution layer에 여러개의 필터 → C_out개 사용
- 각 필터마다 feature map 1개씩 생성 → 사용한 filter 개수 = output 이미지의 채널 = C_out
- 각 채널마다 filter 1개씩 적용 → filter의 채널 = input 이미지의 채널 = C_in
==> filter의 크기 = (C_out) x (C_in) x FH x FW
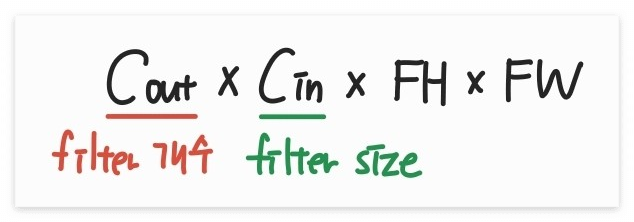
2) output volume size
- H x W 크기의 이미지에, P 만큼 padding이 추가되고, S 크기의 stride로 필터링 했을때
- output 이미지 1개의 높이와 너비
==> OH = (H+2P-FH)/S +1
OW = (W+2P-FW)/S +1
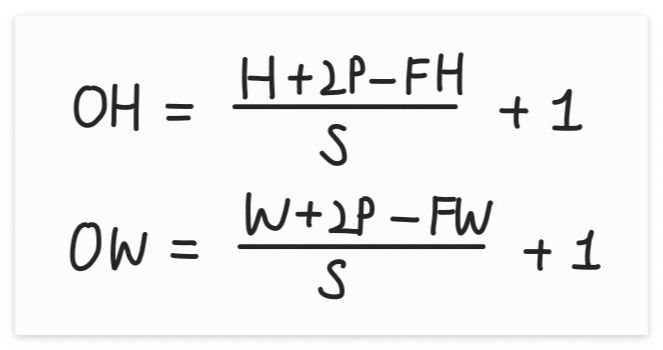
3) convolution layer 계산 예제

① output volume size
OH = (H+2P-FH)/S +1 = (32+2*2-5)/1 +1 = 32
OW = (W+2P-FW)/S +1 = (32+2*2-5)/1 +1 = 32
C_out = 10
==> ouput volume size = C_out x OH x OW = 10 x 32 x 32
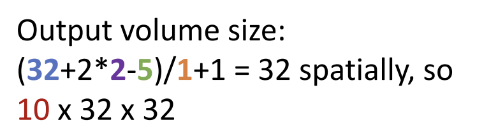
② number of parameter
= filter 개수 x (shape of filter + bias 1개)
= C_out x (C_in x FH x FW + 1)
= 10 x (3 x 5 x 5 +1)

③ number of operations
= (output volume size) x (shape of filter)
= (10 x 32 x 32) x (3 x 5 x 5)

4. Pooling layer
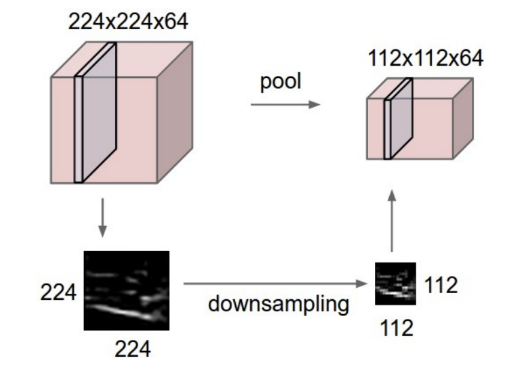
1) Pooling의 역할
- 이미지 크기를 줄이는 Downsampling 기능을 수행하는 layer
- convolution layer의 output 이미지에 사용됨
2) 하이퍼 파라미터
- Kernel size : Pooling filter의 크기
- Stride : Pooling filter의 이동 간격
- Pooling function : Pooling하는 방법
- Max Pooling : filter에 해당되는 범위 내 pixcel의 최댓값을 결과값으로
- Average Pooling : filter에 해당되는 범위 내 pixcel들의 평균값을 결과값으로
3) Pooling layer 계산
- C : input 이미지 채널 = output 이미지 채널
- H / W : input 이미지 높이 / 너비
- K : Kernel Size
- S : Stride 크기
- OH / OW : output 이미지 높이 / 너비
① output volume size
OH = (H-K)/S +1
OW = (W-K)S +1
채널 수 C는 input의 값이 그대로 유지
==> output volume size = C x OH x OW
② number of parameter
NONE!! Pooling에는 학습에 필요한 파라미터가 사용되지 않음!
③ number of computation
= (output volume size) x (shape of filter)
= (C x OH x OW) x (K x K)
Pooling에서는 filter의 채널 수가 1개!
Reference
https://kr.mathworks.com/discovery/convolutional-neural-network.html
https://wikidocs.net/64066
http://taewan.kim/post/cnn/
https://velog.io/@kbm970709/%EC%8B%A0%EC%9E%85%EC%83%9D-%EC%84%B8%EB%AF%B8%EB%82%98-Lecture-7-Convolutional-Networks-DL-for-CV
'교내 수업 > 인공지능' 카테고리의 다른 글
| [NLP] Language Model / n-gram, NNLM, RNNLM (1) | 2024.01.30 |
|---|---|
| [NLP] Word2Vec / Skip-gram, CBOW (0) | 2024.01.29 |
| [CNN] CNN 모델의 발전 (1) | 2024.01.21 |
| [CNN] Fully-Connected Layer (0) | 2024.01.19 |
| [Linear Algebra] SVD를 이용한 image compression (1) | 2024.01.19 |



