
working_helen
[NLP] Word2Vec / Skip-gram, CBOW 본문

1. Word Embedding
2. Word2Vec
3. Word2Vecd의 학습
4. Skip-gram
5. CBOW
1. Word Embedding
1) one-hot encoding
- encoding : 입력 데이터를 컴퓨터가 처리할 수 있는 특정한 형식으로 변환해주는 과정
- NLP 초기엔 특정 단어의 등장 여부를 1과 0으로 표현하는 one-hot encoding 방식을 사용해
각각의 words를 단어 벡터로 수치화
- 단어의 의미가 전혀 반영되지 않으므로 단어 벡터 간 유사성, 단어 벡터 간 수치 계산 등을 고려하지 못함
- sparse vector를 생성하기 때문에 단어 수가 많아지면 과도하게 많은 파라미터를 사용하는 고차원 벡터가 됨
2) Embedding
- embedding : 데이터의 의미를 유지하면서 고차원 데이터를 저차원의 연속적인 실수 벡터로 변환하는 과정, 컴퓨터의 데이터 처리가 더 쉬워지도록 만들며 주로 words나 items와 같은 범주형 데이터를 실수 벡터로 변환하는데 이용
3) Word Embedding
- 각각의 단어를 embedding을 통해 실수 벡터화
- Word Embedding 종류
- Static Embedding 정적 임베딩
- 각각의 단어를 항상 동일한 벡터 표현으로 변환하는 임베딩
- 다의어의 경우 문맥에 따라 다른 의미로 사용될 수 있지만 항상 같은 벡터 표현을 가지는 단점
예) "Tom left bank and played on the bank of river"
2가지 'bank'는 서로 다른 의미를 가지고 있지만 같은 임베딩 벡터가 할당됨
- Word2vec(Skip-gram, CBOW), Glove 등 - Contextualized Embedding 문맥화된 임베딩
- 단어 임베딩 시 전체 문장에서의 문맥적 정보도 반영
- 같은 단어라도 문맥에 따라 서로 다른 벡터 표현으로 변환될 수 있는 임베딩
- 다층 신경망 구조를 사용해 각 단어가 문장 내 다른 단어와 어떻게 상호작용하는지 학습
- ELMo, Bert, GPT 등
- Word Embedding 특징
- dense vector : 임베딩은 벡터의 모든 칼럼이 실수값을 포함하는 밀집 벡터로 변환
- Shared Features : vocabulary size에 해당하는 고차원 데이터를 저차원 벡터로 변환하기 때문에 벡터의 모든 칼럼이 각 단어의 의미에 관여하게 됨
- Semantic Similarity : 각 칼럼마다 특정한 의미에 관여하므로 단어 벡터 간 유사성, 단어 벡터 간 수치 계산 등이 가능해짐
* sparse vector (희소 벡터) : 벡터의 원소 대부분이 0으로 표현되는 임베딩 방법, 전체 단어 집합(vocabulary) 개수에 해당하는 길이의 벡터로 표현해야하므로 단어 수가 늘어나면 벡터의 차원이 한없이 커진다는 단점, one-hot encoding
* dense vector (밀집 벡터) : 벡터의 원소가 0과 1만이 아닌 실수값으로 표현되는 임베딩 방법, 단어의 개수가 아닌 사용자가 설정한 값을 벡터의 차원으로 사용, Word Embedding
2. Word2Vec
1) 분포 가설 (Distributional Hypothesis)
- "비슷한 분포를 가진 단어들은 비슷한 의미를 가진다"
- 단어의 분포 = 단어가 등장하는 문맥 = 다른 단어가 해당 단어의 근처에 사용될 조건부 확률분포
- 비슷한 의미를 가지는 단어들은 비슷한 문맥에서 등장한다는 가설
2) Word2Vec
- 단어의 의미를 벡터화하는 Word Embedding 방식
- 단어의 의미를 반영할 수 있는 Embedding vector를 학습
- 분포 가설을 기반으로 자연어 수치화 과정에서 문맥을 반영
(one-hot encoding 방식의 한계 극복)
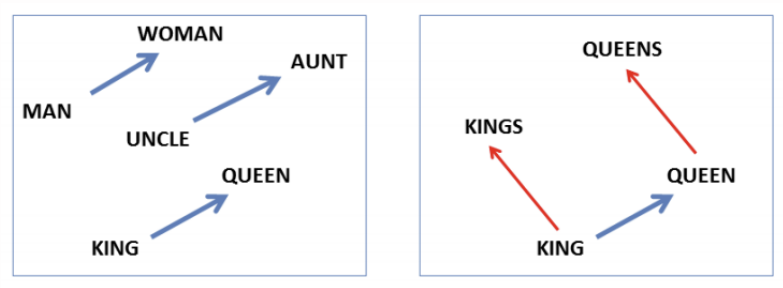
- 벡터 간 연산으로 단어 간 유사성 및 의미관계를 계산할 수 있게 됨
- 단어가 실수 공간 상의 벡터로 표현되므로 다양한 벡터 수치 연산을 적용할 수 있음
- 필요한 크기에 맞춰 단어의 의미를 저차원 상에서 표현할 수 있음
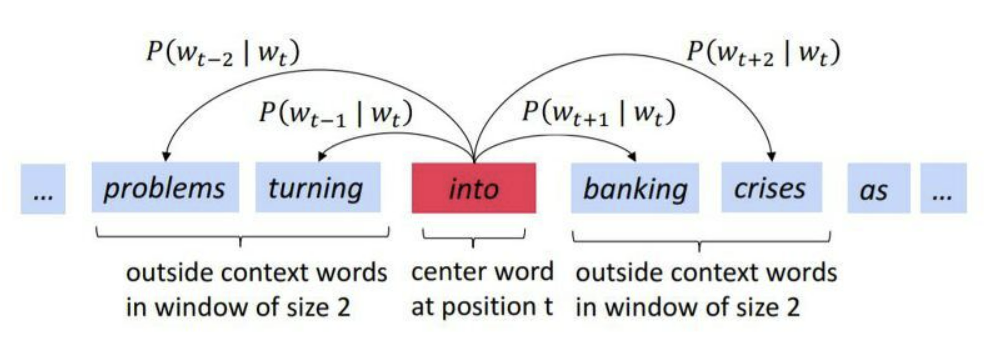
- t : 각 단어의 위치 index
- w_t : t index 위치의 단어
- T : 전체 단어의 개수
- m : window size
- c : center word
- o : context(outside) word
- w 근처에 나타나는 단어 : w의 문맥
- P(o|c) : c 기준 window size 범위 내에 o가 존재할 조건부 확률
- Word2Vec space = 주어진 c에 대하여, vocabulary 내 모든 단어들의 P(o|c)값 벡터 space
- 의미가 유사한 단어 = P(o|c) 값의 분포가 유사 = P(o|c) 벡터가 유사
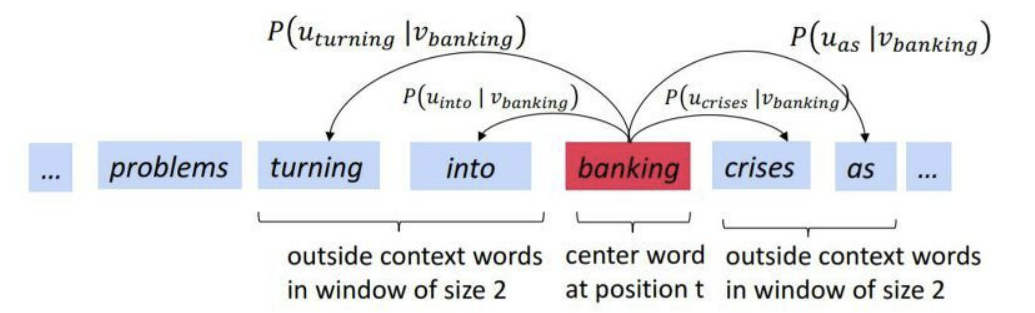
3. Word2Vec 학습
Word2Vec 학습 = word embedding vector 학습 = 각 단어들의 P(o|c) 학습
Word2Vec에서 학습이란, 단어들의 벡터화 방법을 학습하는 것
단어의 문맥을 가장 잘 반영하는 확률 벡터 임베딩 결과를 학습하는 것
랜덤값으로 주어진 가중치 W, W'
→ Skip-gram 혹은 CBOW 방식으로 W와 W' 학습
predict → loss fucntion → W, W' optimization 형태
→ 학습한 W = word embedding vector
1) P(o|c) = Softmax
- w : 어떤 단어 w
- v_w : w가 c일때 embedding vector
- u_w : w가 o일때 embedding vector
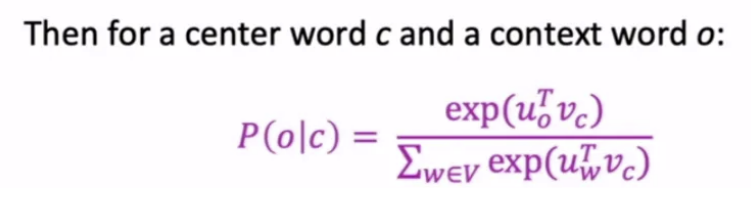
2) Objective Function
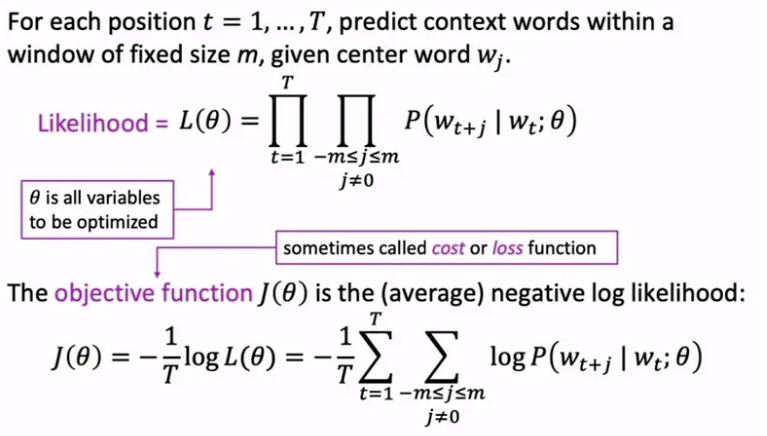
- 전체 T개의 단어들에 대하여, window size가 m일 때
- Likelihood L = 모든 P(o|c) 조건부 확률값을 곱한 결과
- Objective Funtion J = negative log likelihood
- L을 최대화하는 방향으로 = J를 최소화하는 방향으로 Optimization
4. Skip-gram
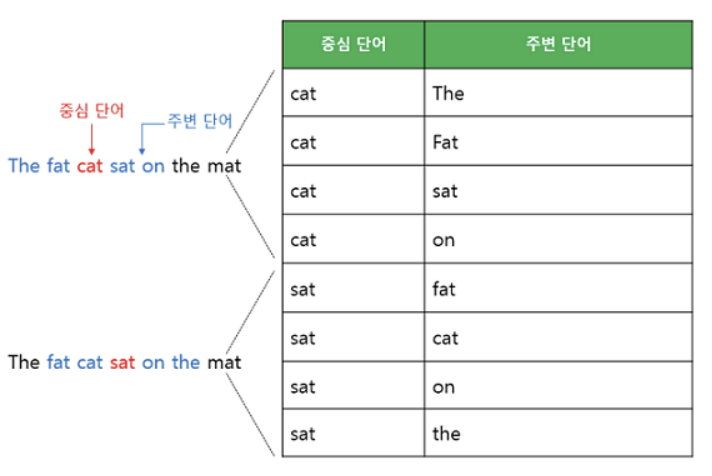
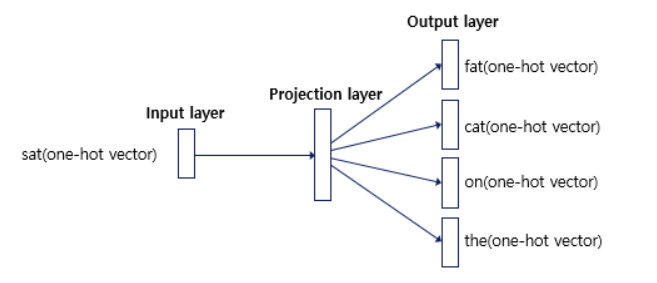
- 1개의 hidden layer를 사용하는 shallow neural network
- 중심 단어 c에서 주변 단어 o를 예측하는 방식으로 P(o|c) 학습
center word의 one-hot vector input
→ 주어진 W_input과 W_output으로 P(o|c) 계산
→ loss 계산 : predicted P(o|c) vector - 정답 context word의 one-hot vector
→ W_input, W_output optimization
→ 중심 단어로부터 주변 단어를 잘 예측하는 word embedding vector 학습
- x : center word의 one-hot encoding 벡터
- W_input : center word embedding vector matrix, 전체 단어의 v_c matrix
- h : v_c, center word c의 embedding vector
- W_output : context word embedding vector matrix, 전체 단어의 u_o matrix
- Softmax : score 값 → 전체 합이 1인 확률값으로 변환
- y_pred : 모델이 예측한 center word의 P(o|c) 벡터
- 중심 단어가 'passes'이고 window가 1이면, 주변 단어는 'who' 와 'the'
- 'passes'가 c일 때 'who' 와 'the'를 o로 잘 예측하는 = 'who' 와 'the'의 P(o|c) 값을 가장 높게 만드는
- word embedding W_input와 W_output를 학습한다!

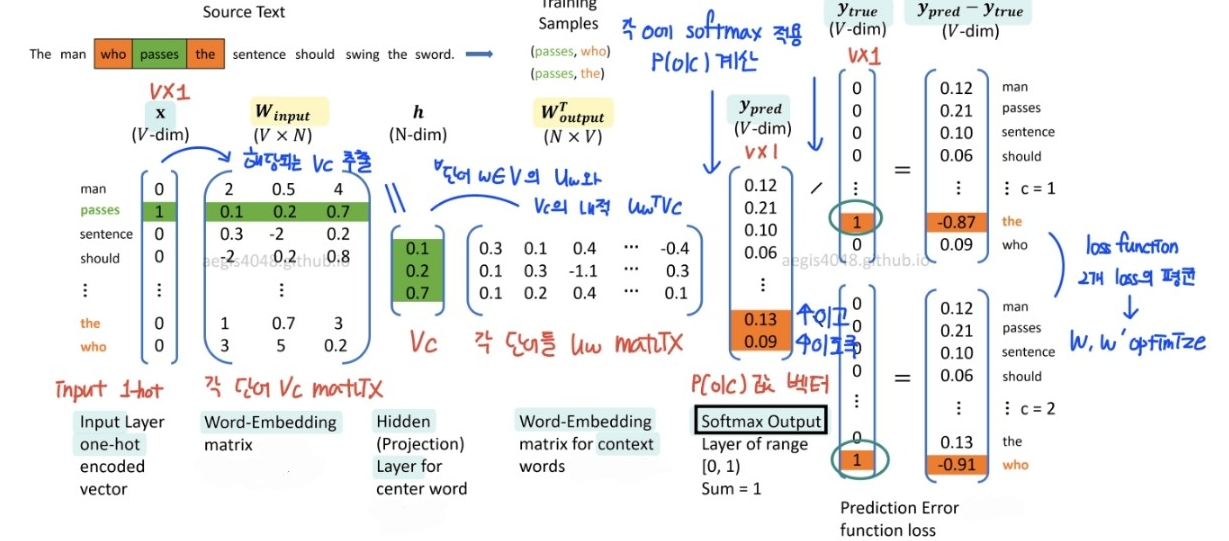
5. CBOW
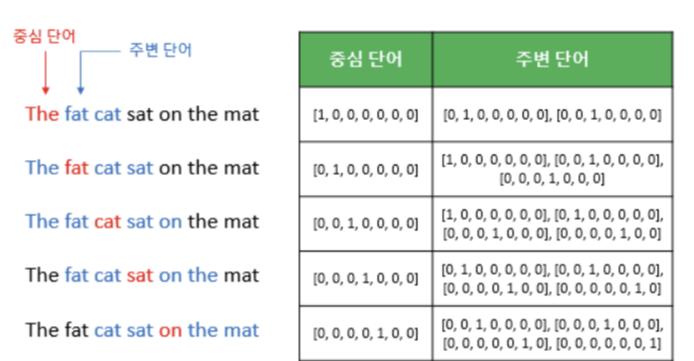
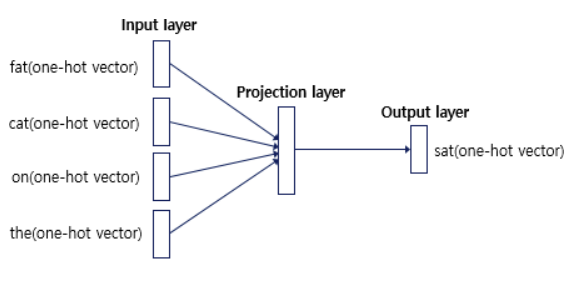
- 1개의 hidden layer를 사용하는 shallow neural network
- 주변 단어 o들을 이용해 중심 단어 c를 예측하는 방식으로 P(o|c) 학습
window size 내 context word의 one-hot vector input
→ 주어진 W_input과 W_output으로 P(o|c) 계산
→ loss 계산 : predicted center word vector - 정답 center word의 one-hot vector
→ W_input, W_output optimization
→ 주변 단어로부터 중심 단어를 잘 예측하는 word embedding vector 학습
- x : N개 context word의 one-hot encoding 벡터
- W_input : word embedding vector matrix
- h : N개 context word의 embedding vector 평균
- W_output : N차원 벡터를 V차원으로 변환, score 계산
- Softmax : score 값 -> 전체 합이 1인 확률값으로 변환
- y_pred : 모델이 예측한 center word 확률 벡터
- 중심 단어가 'sat'이고 window가 2이면, 주변 단어는 'fat', 'cat', 'on', 'the'
- 'fat', 'cat', 'on', 'the'가 o일 때 'sat'을 c로 잘 예측하는 = 'sat'의 확률값을 가장 높게 만드는
- word embedding W_input와 W_output를 학습한다!
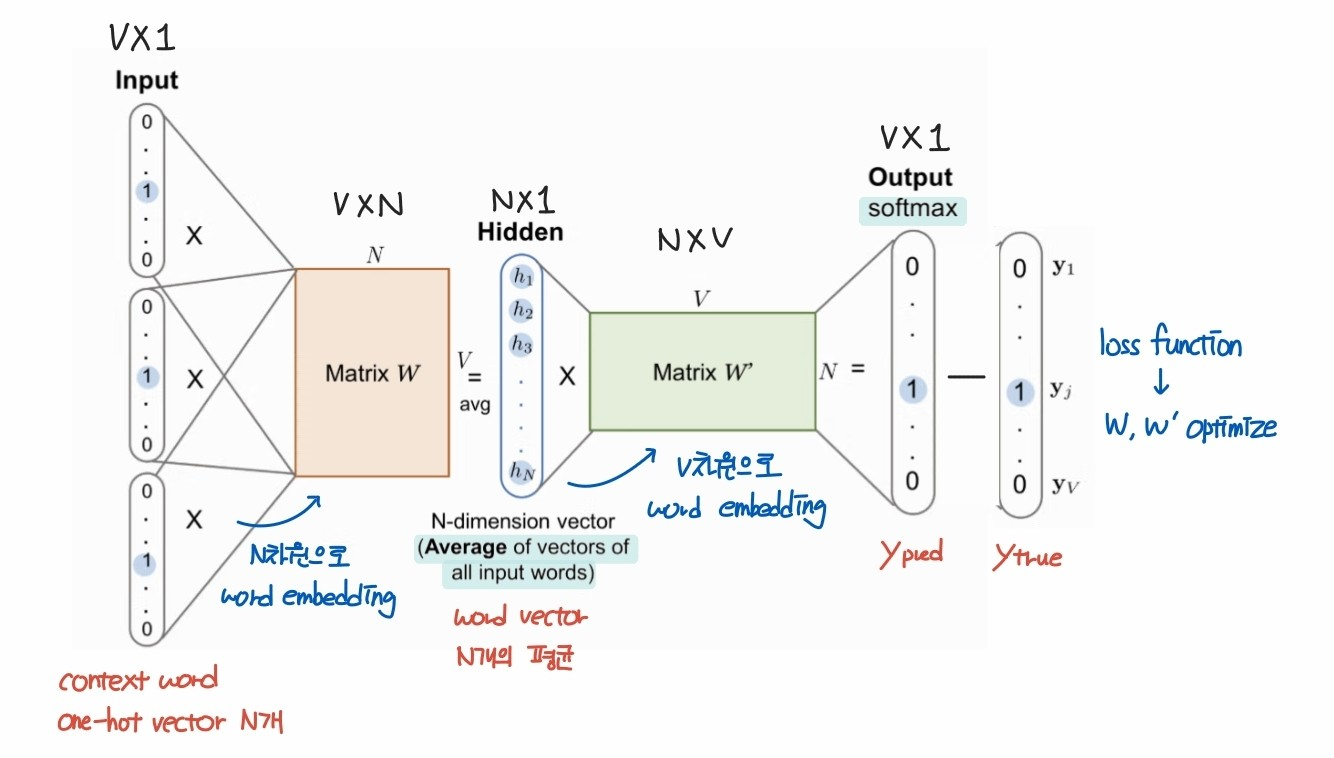
- CBOW는 optimization 과정에서 center word 1개에 대하여 1번의 가중치 업데이트만 진행하지만,
- Skip-gram은 window size에 해당하는 context word 개수만큼 가중치 업데이트를 수행할 수 있으므로
- CBOW보다 Skip-gram의 학습량이 더 크고, 성능이 더 뛰어난 것으로 알려져있다.
Reference
https://aws.amazon.com/ko/what-is/nlp/
https://msmskim.tistory.com/26
https://wikidocs.net/22660
https://wikidocs.net/33520
https://medium.com/areomoon/natural-language-processing-word2vec-a2e9cfa1f35b
https://aegis4048.github.io/demystifying_neural_network_in_skip_gram_language_modeling
https://shuuki4.wordpress.com/2016/01/27/word2vec-%EA%B4%80%EB%A0%A8-%EC%9D%B4%EB%A1%A0-%EC%A0%95%EB%A6%AC/
https://velog.io/@xuio/NLP-TIL-Word2VecCBOW-Skip-gram
https://simonezz.tistory.com/35
https://www.linkedin.com/pulse/understanding-differences-between-encoding-embedding-mba-ms-phd/
https://ted-mei.medium.com/from-static-embedding-to-contextualized-embedding-fe604886b2bc
https://ws-choi.github.io/blog-kor/nlp/deeplearning/paperreview/Contextualized-Word-Embedding/
'교내 수업 > 인공지능' 카테고리의 다른 글
| [NLP] Language Model / n-gram, NNLM, RNNLM (1) | 2024.01.30 |
|---|---|
| [CNN] CNN 모델의 발전 (1) | 2024.01.21 |
| [CNN] Convolution Layer / Pooling layer (1) | 2024.01.21 |
| [CNN] Fully-Connected Layer (0) | 2024.01.19 |
| [Linear Algebra] SVD를 이용한 image compression (1) | 2024.01.19 |



