

working_helen
[CNN] CNN 모델의 발전 본문
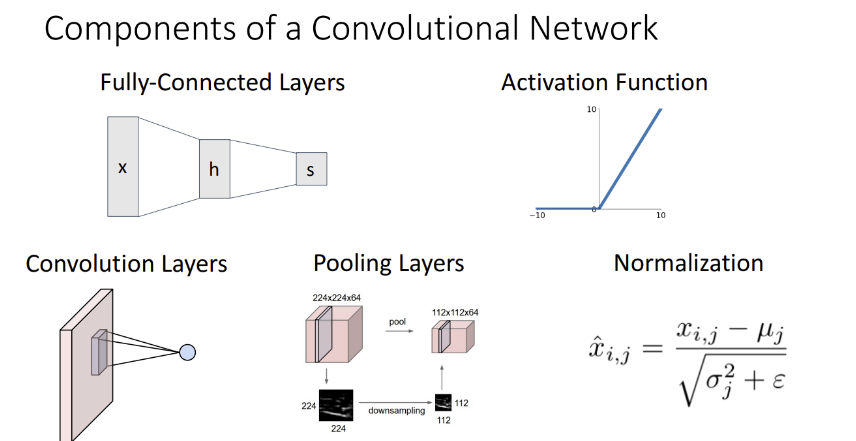
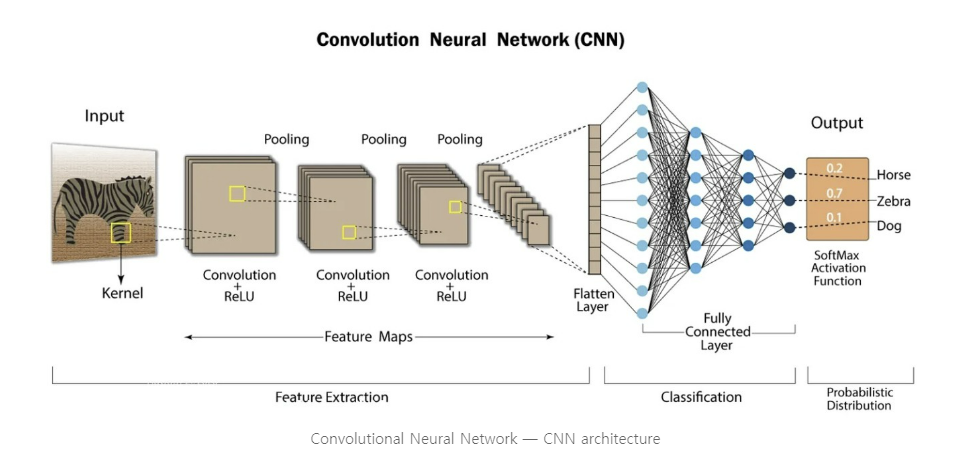
현재까지 발전해온 다양한 CNN 구조의 모델에 대해 공부해본다.
1. ImageNet Classification Challenge
2. LeNet
3. AlexNet
4. VGG (Visual Geometry Group)
5. ResNet (Residual Network)
1. ImageNet Classification Challenge
- CNN 기반 이미지 분류 모델의 성능을 평가하기 위해 매년 열린 대회
- 1.2 million 크기의 이미지와 1000개의 class(categroy)를 가지는 거대 데이터셋 ImageNet Dataset을 분류

2. LeNet

- 4 layers = 3 convolution layers + 1 fully-connected layers
- input : 32 x 32 흑백 이미지
- Subsampling(Pooling) function : average pooling
- activation function : tanh
- normalization : Local response normlization
- CNN 초기 모델로, CNN의 기본 구조를 정립한 것으로 알려진 모델
- 다양한 버전이 존재하며, 최종 버전은 LeNet-5
3. AlexNet


- 8 layers = 5 convolution layers + 3 fully-connected layers
- input : 227 x 227 x 3 컬러 이미지
- Pooling function : max pooling
- activation function : ReLU
- normalization : Local response normlization
- 현재 많이 사용되는 비선형 활성화 함수 ReLU를 처음으로 사용한 모델
- 현재는 주로 Batch Normalization 사용
- 개발 당시 GPU 용량 부족으로 인해 2개의 GPU로 병렬연산을 수행
4. VGG (Visual Geometry Group)

- VGG16 : 16 layers = 13 convolution layers + 3 fully-connected layers
VGG19 : 19 layers = 16 convolution layers + 3 fully-connected layers - design principle 정립
- 모든 convolution layer : 3x3, stride 2, pad 1 사용
- 모든 Pooling layer : 2x2, stride 2, max pooling 사용
- Pooling layer output에서 채널의 개수를 2배로
- conv-conv-pool 구조를 여러 Stage에 걸쳐 반복하는 구조
- 유사한 결과에서 연사량을 최소화할 수 있도록 CNN 모델의 구현 원칙을 정립
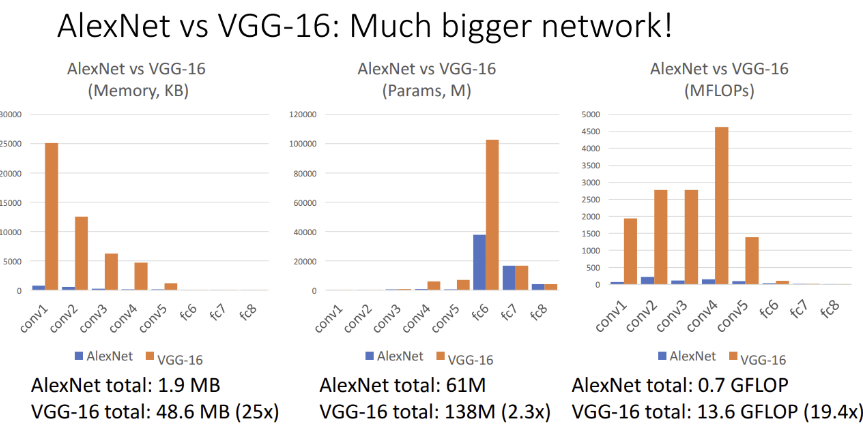
- AlexNet과 성능 비교 : AlexNet보다 연산량이 약 19배 많은 거대 모델
5. ResNet (Residual Network)
1) 등장 배경

- 2015년부터 CNN에 Batch Normalization이 적용되면서 사람들은 layer가 Deep한 모델을 구현하기 시작
- 하지만 Deep한 모델이 Train data와 Test data 모두에서 Shallow한 모델보다 성능이 떨어지는 문제 발생
==> Deep 모델이 학습이 잘 일어나지 않는 Underfitting 상태
==> 초기에 생각했던 것보다도 더 많은 layers를 가지는 Deep 모델을 생성하기 시작
Deep model = Shallow model의 layers를 모방하여 사용 + extra identity function layers를 추가
- 기존의 Shallow model을 통해 학습 정보를 유지 + 각 identity layers는 residual에 해당하는 작은 정보만 학습
- 기존 Shallow model의 성능을 유지하면서 + 추가적인 정보를 학습할 수 있는 모델
identity function의 기능
- underfitting을 해소하기 위해 model의 layer를 추가할 수 있고
- residual을 학습하기 때문에 esay to optimization인 장점
2) ResNet의 모델 구조
: identitiy function 효과적으로 학습할 수 있는 모델 구조인 Residual Learning을 제시

- x : 입력값
- F(x) : Conv Layer -> ReLU -> Conv Layer 을 통과한 출력값
- H(x) : Conv Layer -> ReLU -> Conv Layer -> ReLU 를 통과한 출력값
① 기존의 identity function block
- convolution layer를 거진 결과 H(x)에 대하여, H(x) - x = 0가 되도록 학습시키는 것이 목표
- H(x) = x가 되는 복잡한 함수에 H(x)를 근사시키는 문제
② ResNet에서 identity function block
- Skip Connection (Additive "shortcut") : x가 convolution layer를 건너뛰어 출력값에 더해지는 방식
- H(x) = F(x) + x = x, F(x) = H(x) - x = residual
- F(x) = 0, 즉 residual이 0이 되도록 학습 시키는 것이 목표
- H(x)를 복잡한 함수에 근사시키는 것보다, F(x) + x 에 근사시키는 것이 더 쉬움
- F(x)=0 목표값이 있는 optimazation 과정이라 학습에 더 용의함
- ResNet은 이러한 residual block을 여러번 반복적으로 쌓은 구조
- 총 152 layers의 모델까지 생성함

3) ResNet의 장점
- identitiy function 효과적으로 학습할 수 있는 방법을 제시했고,
- layer를 매우 깊이 쌓은 상황에서도 모델 성능이 저하되지 않게 만들었다.
- Residual Learning이라는 개념 자체 또한 이후 많은 모델들에서 응용되고 있다.
Reference
https://velog.io/@kbm970709/%EC%8B%A0%EC%9E%85%EC%83%9D-%EC%84%B8%EB%AF%B8%EB%82%98-Lecture-8-CNN-Architectures-DL-for-CV
https://velog.io/@lighthouse97/AlexNet%EC%9D%98-%EC%9D%B4%ED%95%B4
https://velog.io/@lighthouse97/LeNet-5%EC%9D%98-%EC%9D%B4%ED%95%B4
https://wikidocs.net/164796
https://wikidocs.net/137252
'교내 수업 > 인공지능' 카테고리의 다른 글
| [NLP] Language Model / n-gram, NNLM, RNNLM (1) | 2024.01.30 |
|---|---|
| [NLP] Word2Vec / Skip-gram, CBOW (0) | 2024.01.29 |
| [CNN] Convolution Layer / Pooling layer (1) | 2024.01.21 |
| [CNN] Fully-Connected Layer (0) | 2024.01.19 |
| [Linear Algebra] SVD를 이용한 image compression (1) | 2024.01.19 |



