
working_helen
[text 감정 추출 모델] SVM 모델 학습 / text 감정 추출 결과 본문
text 감정 추출 모델 학습 및 적용 과정에 대해 공부해본다.
1. text 감정 추출 SVM 모델
2. SVM 모델 적용 결과
1. text 감정 추출 SVM 모델
- 목표 : 주어진 text에 대하여 11가지 sentiment 각각에 매칭될 확률를 예측하는 모델
- input : 임의의 text (텍스트 전처리를 거친 후)
- output : 길이 11의 감정 확률 벡터
1) 사용 데이터
- tweet_data_agumentation.csv
: 기존의 트위터 감정 데이터 tweet_emotions.csv에 대하여 텍스트 데이터 증강(EDA)를 진행한 데이터
2) SVM 모델 학습
## `content`열의 text들 tf-idf 벡터화
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer()
text = tfidf_vect.fit_transform(df["content"])
text_arr = text.toarray()
x = pd.DataFrame(text_arr, columns=tfidf_vect.get_feature_names_out())
y = df["sentiment"]
## train-validation 데이터셋 준비
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(text1, y, test_size=0.3, random_state=123)
## SVM 모델 학습 & 결과 확인
from sklearn.svm import SVC
from sklearn.metrics import classification_report
model = SVC()
model.probability=True
model.fit(X_train, y_train)
pred_svm = model.predict(X_test)
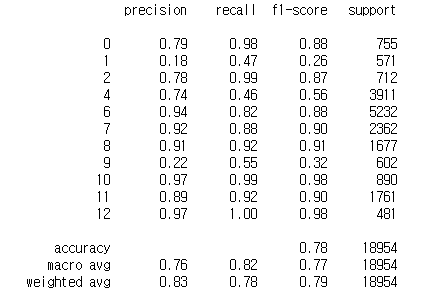
print(classification_report(pred_svm, y_test))
3) 모델 예측 결과
- 모델 성능
- text 감정 추출 예시


2. SVM 모델 적용 결과
- SVM 모델이 트위터 데이터를 이용해 학습했기 때문에, 학습 당시 사용했던 input 데이터와 동일한 형태로 새로운 input text의 형태를 변형해야 한다.
→ 트위터 데이터를 이용해 text를 tf-idf 벡터로 변환하는 모델 fit_transform
→ 위의 모델로 도서 설명 text와 노래 가사 text 데이터를 transform
(즉, input 데이터를 동일한 tf-idf 벡터 형태로 변환)
1) 노래 가사 text
: 노래 가사 크롤링 → 가사 요약 T5 모델 적용 → 텍스트 전처리 → text 감정 추출 SVM 모델 적용
# 트위터 데이터 + SVM 모델 불러오기
df = pd.read_csv('tweet_data_agumentation.csv', index_col = 0)
model = joblib.load('SVM.pkl')
# df로 tf-idf 학습
tfidf_vect = TfidfVectorizer()
tfidf_vect.fit_transform(df["content"])
# 학습한 tf-idf 모델을 가사 text에 동일하게 적용
text2 = tfidf_vect.transform(song['summary_text'])
pred = model.predict_proba(text2)
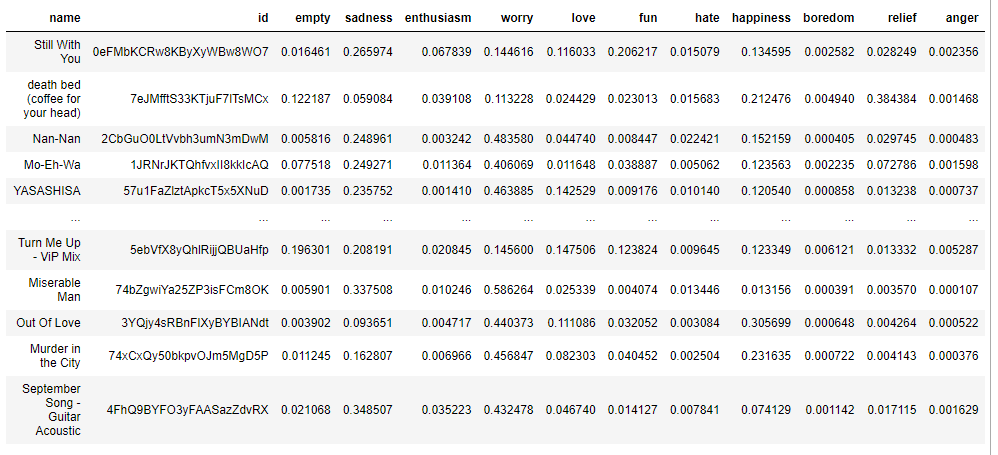
# 전체 노래 DB에 있는 노래들의 가사 text 감정 벡터 추출
sentiment = pd.DataFrame(pred,columns=['empty','sadness','enthusiasm','worry','love','fun','hate','happiness','boredom','relief','anger'])
sentiment.insert(0,'id',song['id'])
sentiment.insert(0,'name',song['name'])
sentiment
2) 도서 설명 text
: 도서 설명 text API에서 받아오기 → 텍스트 전처리 → text 감정 추출 SVM 모델 적용
text = 도서 설명 text
# 트위터 데이터 + SVM 모델 불러오기
df = pd.read_csv('tweet_data_agumentation.csv', index_col = 0)
model = joblib.load('SVM.pkl')
# df로 tf-idf 학습
tfidf_vect = TfidfVectorizer()
tfidf_vect.fit_transform(df["content"])
# 학습한 tf-idf 모델을 도서 text에 동일하게 적용
text2 = tfidf_vect.transform(text_df['text'])
model.predict_proba(text2)
# 도서 설명 text의 감정 확률 벡터 추출
book_sentiment = pd.DataFrame(model.predict_proba(text2), index=['prob']).T
book_sentiment['감정'] = ['empty','sadness','enthusiasm','worry','love','fun','hate','happiness','boredom','relief','anger']
book_sentiment = book_sentiment.sort_values(by='prob',ascending=False)
book_sentiment

'deep daiv. > 추천시스템 project' 카테고리의 다른 글
| [웹페이지 구현] Streamlit 웹페이지 구현 / 공모전 제출 (0) | 2024.01.12 |
|---|---|
| [플레이리스트 작성] 최종 유사도 분석 (0) | 2024.01.11 |
| [text 감정 추출 모델] Data Augmentation 데이터 증강 (0) | 2024.01.06 |
| [text 감정 추출 모델] 텍스트 전처리 / Goolgetrans 번역 API (0) | 2023.09.18 |
| [Audio feature 군집화] Spotify Song Clustering with k-means (0) | 2023.09.16 |
'deep daiv./추천시스템 project' Related Articles
more



