text 감정 추출 모델 구현 과정에서 학습한 Data Augmentation에 대해 공부해본다.
1. Data Augmentation 데이터 증강 2. 학습 데이터 부족 문제 3. 학습 데이터 불균형 문제 4. Back translation
5. EDA (Easy Data Augmentation) 논문
1. Data Augmentation 데이터 증강
1) Data Augmentation
(위키백과) 데이터 증대(data augmentation) 또는 데이터 첨가, 데이터 증강은 주로 기계 학습을 위해 새로운 데이터를 첨가하거나, 수를 늘리는 기법이다. 과대표집(oversampling)과 관련이 있다. 기계 학습 모델을 훈련할 때 과적합을 줄이는 데에 도움이 된다.
- 보유하고 있는 데이터를 활용해 추가 합성 데이터를 생성하는 기법
- 데이터 셋의 규모를 키워 딥러닝 모델을 훈련하기에 충분한 수의 데이터를 확보하기 위해 사용한다.
2) 목적
① 학습 데이터의 수나 다양성이 부족해 자체적으로 데이터 수를 늘리고 싶을 때 ② 불균형 데이터의 수를 늘려 데이터 불균형 문제를 해소하고자 할 때
3) 이미지 데이터 증강 (Image Augmentation)
- 가지고 있는 이미지 데이터를 약간씩 변형시켜 데이터를 증강
- Computer Vision 분야에선 학습 데이터 부족 문제를 해결하기 위해 augmentation를 자주 사용한다.
이미지 회전 (Image Rotation) / 이미지 대칭 (Image Flipping) / 이미지 이동 (Image Translation)
이미지 확대·축소 (Image Scaling) / 이미지 밝기 조절 (Image Brightness Adjustment) 등
4) 텍스트 데이터 증강 (Text Augmentation)
- 텍스트는 한 단어만 바꿔도 문장의 의미 자체가 변화할 수 있다. (문장 분류의 정답 라벨이 달라질 수 있다.)
- 이로 인해 CV에 비해 NLP에서 augmentation이 더 신중하게 사용된다.
- 학습 데이터셋에 대해서만 수행하며, 새로운 증강 데이터셋을 사전에 생성한 후 모델에 사용한다.
Back translation
data noising as smoothing (데이터에 노이즈 추가)
EDA (Easy Data Augmentation)
2. 학습 데이터 부족
1) 학습 데이터 부족의 문제점
- 머신러닝, 딥러닝에선 데이터 수가 많을수록 좋음
- 다양한 variation의 학습 데이터를 통해 더 일반화된 패턴을 학습하기 때문에 Overfitting을 방지, 모델 성능을 높일 수 있음 - 하지만 관련 데이터가 없거나 데이터 수집 비용이 커 모델 학습이 어려운 경우가 발생
2) 해결 방안
Augmentation : 학습 데이터 수 자체를 늘리려는 방식
Transfer Learning 전이학습 : 어떤 문제를 해결하기 위해 학습된 모델을 유사한 다른 문제 해결에 활용하는 것, 사전에 대량의 data로 학습된 모델을 들고와 새로운 모델로 발전시키는 방식
- 2018년 EMNLP에 발표된 논문 - 쉽게 데이터를 증강하는 기법 - 데이터 증강이 적용되기 어려웠던 NLP 분야에서 유의미한 효과를 보였다.
- EDA가 CNN과 RNN 모두에서 성능을 향상시키며, 규모가 작은 데이터셋에서 특히 강력함을 보였다. - 논문에서의 실험 결과, 평균적으로 전체 훈련 데이터셋의 50%만 사용한 채 EDA를 적용하여 학습시킨 경우와 전체 데이터셋을 이용해 학습시킨 것과 유사한 정확도를 달성했다.
1) EDA 기법
- 기존의 텍스트 데이터를 변형시켜 데이터를 증강시키는 4가지 방법
- 훈련 데이터셋의 문장에 대해 다음 4가지 작업 중 일부를 선택하여 사용한다.
- 긴 문장은 짧은 문장보다 많은 단어를 가지고 있어 기존 문장의 틀을 유지하면서 더 많은 노이즈 데이터를 생성할 수 있다.
SR (Synonym Replacement), 유의어 교체 : 특정 단어를 유의어로 교체 → 불용어가 아닌 n개의 단어를 골르고, 임의로 선택한 유의어와 교체
RI (Random Insertion), 무작위 삽입 : 임의의 단어를 삽입 → 불용어가 아닌 단어들 중 랜덤하게 단어를 고르고, 유의어를 문장 내 임의의 위치에 삽입, n번 실행
RS (Random Swap), 무작위 교체 : 텍스트 내 임의의 두 단어 순서를 변경 → 랜덤하게 2개의 단어를 선택하고, 둘의 위치를 바꿈, n번 실행
RD (Random Deletion), 무작위 삭제 : 임의의 단어를 삭제 →각 단어를 p의 확률로 임의로 삭제
2) Experiment, Result
(1) 변수
l : 문장의 길이
α : augmentation parameter, 문장 내 단어들 중 변경된 단어의 비율
n : 변경된 단어의 개수, n = l x α
n_aug : 증강된 문장의 개수
(2) Does EDA conserve true labels?
: EDA로 생성된 문장이 기존 문장의 정답 라벨을 그대로 유지하는가?
- 데이터 증강 없이 텍스트 이진분류 과제(pro-con 긍부정 분류)를 수행하는 RNN 모델 훈련
- 9개의 문장으로 증강하는 EDA 수행 후 RNN 모델로 긍부정 label 예측
- 기존 문장 + 증강 문장의 label을 t-SNE로 시각화
▶ 증강된 문장과 원래 문장이 공간적으로 밀접한 관련이 있다.
▶ EDA로 증강된 문장들이 기존 문장의 label을 대부분 유지하고 있다.
(3) Training Set Sizing
: EDA가 성능 향상에 얼마나 효과가 있을까?
- 전체 데이터셋에서 사용한 학습 데이터의 비율을 다르게 하며, EDA를 적용한 경우와 그렇지 않은 경우 성능 비교
- 평균적으로 전체 훈련 데이터셋의 50%만 사용한 채 EDA를 적용하여 학습시켰을 때, 전체 데이터셋을 이용해 학습시킨 것과 유사한 정확도를 달성했다.
(4) Ablation Study: EDA Decomposed
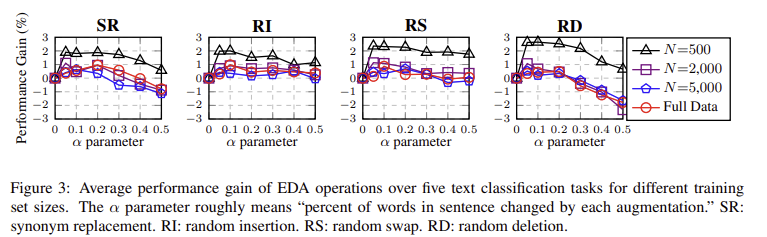
: augmentation parameter α 의 가장 적절한 값은 무엇인가?
- α의 값을 {0.05, 0.1, 0.2, 0.3, 0.4, 0.5}로 설정했을때 성능 비교
- SR, RI, RS, RD 각각에 대해 최적의 α를 계산
▶ 소규모 데이터셋일때 성능 향상이 높았으며
▶ α=0.1일때 4가지 모두에서 성능이 좋았다(sweet spot).
(5) How much augmentation?
: 얼마나 많은 개수로 증강해야 하는가?
- 각 문장을 {1, 2, 4, 8, 16, 32}개로 증강했을때 성능 비교
- 규모가 작은 훈련 데이터셋 : 문장을 많은 생성할수록 오버피팅이 방지되어 성능이 향상되었다.
- 규모가 큰 훈련 데이터셋 : 이미 모델이 적절하게 일반화된 상태로, 증강 문장 4개 이상 추가하는 것은 성능에 큰 영향을 미치지 못했다.
▶ EDA는 소규모 데이터셋에 대해 오버피팅 방지를 통해 성능을 향상시킬 수 있다.
▶ EDA는 소규모 데이터셋에 대해선 성능 변화에 유의미한 영향을 미치지 못했다.
▶ 적절한 증강 문장 개수 파라미터
3) 의의 및 한계
- 데이터 증강이 적용되기 어려웠던 NLP 분야에서 유의미한 효과를 보였다.
- EDA가 CNN과 RNN 모두에서 성능을 향상시키며, 특히 규모가 작은 데이터셋에서 유의미함을 보였다.
==> "어떻게 라벨 손상 없이 텍스트 데이터 증강을 할 수 있을까?"에 관한 접근
- 규모가 큰 데이터셋에 대해선 유의미한 성능 개선을 이루기 어려웠다.
- 전이학습과 같이 사전 훈련된 모델을 사용하는 경우에도 EDA를 적용하는 것이 성능에 큰 영향을 주지 못한다.
Jupyter notebook
EDA를 적용해 텍스트 데이터 증강
import random
import pickle
import re
wordnet = {}
with open("wordnet.pickle", "rb") as f:
wordnet = pickle.load(f)
## 유의어 list 반환 함수 (wordnet 이용)
def get_synonyms(word):
synomyms = []
try:
for syn in wordnet[word]:
for s in syn:
synomyms.append(s)
except:
pass
return synomyms
## SR 수행 함수
def synonym_replacement(words, n):
# words : 주어진 문장
# n : SR할 단어 개수, n개의 단어
#현재 문장의 단어들 랜덤 셔플
random_word_list = list(set([word for word in words]))
random.shuffle(random_word_list)
num_replaced = 0
#문장 내에서 단어 임의로 n개 선택
# new_words : 새롭게 생성된 증강 문장 저장
new_words = words.copy()
for random_word in random_word_list:
#선택된 단어 유의어 list 불러오고 임의로 하나 선택해서 대체
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(list(synonyms))
new_words = [synonym if word == random_word else word for word in new_words]
num_replaced += 1
if num_replaced >= n:
break
if len(new_words) != 0:
sentence = ' '.join(new_words)
new_words = sentence.split(" ")
else:
new_words = ""
return new_words
## RD 수행 함수
def random_deletion(words, p):
if len(words) == 1:
return words
new_words = []
for word in words:
#문장 내 각 단어에 대해 임의로 발생확률 부여
#단어가 삭제될 확률 p보다 작으면 제외
r = random.uniform(0, 1)
if r > p:
new_words.append(word)
#모두가 삭제되는 경우, 단어 한개만 임의로 골라서 남김
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return new_words
## RS 수행 함수
def random_swap(words, n):
new_words = words.copy()
for _ in range(n):
new_words = swap_word(new_words)
return new_words
## 단어 위치 교환 함수
def swap_word(new_words):
random_idx_1 = random.randint(0, len(new_words)-1)
random_idx_2 = random_idx_1
counter = 0
while random_idx_2 == random_idx_1:
random_idx_2 = random.randint(0, len(new_words)-1)
counter += 1
if counter > 3:
return new_words
new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
return new_words
## RI 수행 함수
def random_insertion(words, n):
new_words = words.copy()
for _ in range(n):
add_word(new_words)
return new_words
## 단어 삽입을 위한 함수
def add_word(new_words):
synonyms = []
counter = 0
while len(synonyms) < 1:
if len(new_words) >= 1:
#문장 내 임의로 한 단어 골라서 유의어 list 불러오기
random_word = new_words[random.randint(0, len(new_words)-1)]
synonyms = get_synonyms(random_word)
counter += 1
else:
random_word = ""
if counter >= 10:
return
random_synonym = synonyms[0] #맨 앞 유의어로 골라버리기
random_idx = random.randint(0, len(new_words)-1) #임의의 위치에 유의어 삽입
new_words.insert(random_idx, random_synonym)
def EDA(sentence, alpha_sr=0.1, alpha_ri=0.1, alpha_rs=0.1, p_rd=0.1, num_aug=9):
# alpha : 4가지 방식 모두에서 초적의 alpha 0.1로 설정
# num_aug : 총 증강할 문장의 개수
words = sentence.split(' ')
words = [word for word in words if word != ""]
num_words = len(words)
augmented_sentences = []
augmented_sentences_dict = {'SR':[], 'RI':[], 'RS':[], 'RD':[]}
num_new_per_technique = int(num_aug/4) + 1
# n_ : 각 방식별로 문장 내에서 변경할 단어의 개수
n_sr = max(1, int(alpha_sr*num_words))
n_ri = max(1, int(alpha_ri*num_words))
n_rs = max(1, int(alpha_rs*num_words))
# sr
for _ in range(num_new_per_technique):
a_words = synonym_replacement(words, n_sr)
augmented_sentences.append(' '.join(a_words))
augmented_sentences_dict['SR'].append(' '.join(a_words))
# ri
for _ in range(num_new_per_technique):
a_words = random_insertion(words, n_ri)
augmented_sentences.append(' '.join(a_words))
augmented_sentences_dict['RI'].append(' '.join(a_words))
# rs
for _ in range(num_new_per_technique):
a_words = random_swap(words, n_rs)
augmented_sentences.append(" ".join(a_words))
augmented_sentences_dict['RS'].append(' '.join(a_words))
# rd
for _ in range(num_new_per_technique):
a_words = random_deletion(words, p_rd)
augmented_sentences.append(" ".join(a_words))
augmented_sentences_dict['RD'].append(' '.join(a_words))
# 4가지 방식으로 증강한 문장들 중 임의로 n_aug개만 선택
random.shuffle(augmented_sentences)
if num_aug >= 1:
augmented_sentences = augmented_sentences[:num_aug]
else:
keep_prob = num_aug / len(augmented_sentences)
augmented_sentences = [s for s in augmented_sentences if random.uniform(0, 1) < keep_prob]
augmented_sentences.append(sentence)
return augmented_sentences #, augmented_sentences_dict