

working_helen
[ Week 11-1 ] Unsupervised learning / clustering, GMM, KDE 본문
[ Week 11-1 ] Unsupervised learning / clustering, GMM, KDE
HaeWon_Seo 2024. 5. 17. 18:52Lecture : Machine Learning
Date : week 11, 2024/05/13
Topic : Unsupervised learning
1. Unsupervised learning
2. Clustering
3. k-means
4. GMM
5. KDE
1. Unsupervised learning

| Supervised learning | Unsupervised learning | |
| training data | using labeled dataset | using unlabeled dataset |
| train | model learns a function to relate between attributes and labels pairs |
model learns a function that produces useful labels for each instances |
| test | model see new attributes and predict their labels | model see new attributes and predict their labels |
| evaluation | compare model's predictions to true labels | compare model's predictions to future samples from the same probability dist |
비지도 학습의 종류
- clustering : k-means, GMM, KDE, HCA
- association : Apriori algorithm, Eclat algorithm
- dimensionality reduction : PCA, t-SNE, SVD, autoencorder
2. Clustering
: instance가 속하는 class에 대한 사전에 정의된 바가 없음
→ 모델이 데이터로부터 직접 숨겨진 pattern이나 structure를 찾아내서 유의미한 class를 부여함
clustering 방식 종류
- deterministic clustering : 각각의 instance를 하나의 cluster로만 배정, no overlapping
- probabilistic clustering : 각각의 instance가 각 cluster에 배정될 wieght(probability) 계산, overlapping
- hierarachical clustering : cluster를 hierarchical tree 형태로 구분하는 방식
- partitional clustering : cluster를 disjoint group 형태로 구분하는 방식
3. k-means
1) k-means clustering
2023.09.16 - [deep daiv./추천시스템 프로젝트] - [Audio feature 군집화] Spotify Song Clustering with k-means
[Audio feature 군집화] Spotify Song Clustering with k-means
앞서 학습한 k-means 군집화 알고리즘을 적용하여 Spotify 노래 데이터 clustering하는 과정에 대해 정리해본다. 본 프로젝트에서는 audio feature를 이용해 노래의 mood cluster를 구하는 과정을 진행했다. 참
working-helen.tistory.com
2) soft k-means clustering
- k-means의 probabilistic clutering 형태
- 일반 k-means에선 새로운 instance와 가장 가장 가까운 centroid의 class로 직접적으로 배정하는 방식이라면,
soft k-means는 새로운 instance가 각 culster에 배정될 확률값을 softmax 함수를 이용해 계산하는 방식
- instance가 여러개의 culster에 속할 수 있는 경우 유용함

4. GMM (Gaussian mixture model)
- input 데이터의 확률분포를 mixture of k Gaussian distribution으로 표현

- Expectation Maximization(EM) algorithm을 통해 GMM의 파라미터를 찾음
: log-likelihood를 사용해 점근적으로 파라미터를 추정하는 알고리즘
- E step : calculate log-likelihood of each instances based on current parameters values
현재 가우시안 분포에서 각 instance의 likelihood를 계산 - M step : find parameters that maximizes the log-likelihood
likelihood를 최대화하는 distribution의 파라미터 (평균, 분산, 혼합 계수)를 업데이트 - repeat E and M steps until log-likelihood function converge
※ GMM에서 log-likelihood의 역할
- estimate the 'goodness' of the cluster model, 현재 모델이 데이터를 설명하는데 얼마나 적합한지
- estimate how likely each mixed distribution generate each instance, 현재 모델에서 해당 데이터가 발생할 확률이 얼마나 높은지
5. KDE (Kernel density estimation)
- input 데이터의 distribution을 평균이 0이고 표준편차가 sigma인 mixture of N Gaussian distribution으로 표현

- 전체 data에서 N개를 선택
→ 각 N개의 data point를 중심으로 평균이 0이고 표준편차가 sigma인 Gaussian distribution 생성
→ estimated pdf = N개의 Gaussian distribution에서 input을 관측할 확률의 평균
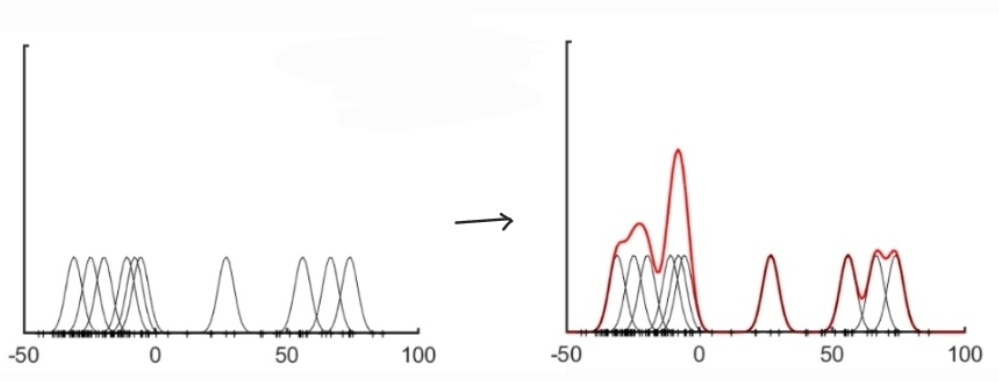
※ KDE에서 bandwidth의 역할
- KDE에서 kernel function의 width를 결정하는 파라미터
- Gaussian distribution에선 표준편차 sigma가 bandwidth에 해당
- bandwidth 커질수록, the kernel spreads more widely and estimates smooth pdf
- bandwidth 작아질수록, the kernel spreads narrowly and estimates jagged pdf
'교내 수업 > Machine Learning' 카테고리의 다른 글
| [ Week 11-2 ] with Insufficient Data / Semi-supervised learning, Active learning (0) | 2024.05.17 |
|---|---|
| [ Week 9-1 ] Structured Classification (0) | 2024.05.06 |
| [ Week 7-2 ] Feature Selection (0) | 2024.04.21 |
| [ Week 7-1 ] Classifier combination (1) | 2024.04.20 |
| [ Week 4-2 ] Decision Tree, ID3 algorithm (0) | 2024.03.25 |



