
working_helen
[ Week 7-2 ] Feature Selection 본문
Lecture : Machine Learning
Date : week 7, 2024/04/18
Topic : Feature Selection
1. Feature selection
2. Wrapper method
3. Filter method
4. Embedded method
1. Feature selection
- 모델 학습에 불필요하고 관계없는 feautre는 제거하고 중요한 feature만을 사용하여 학습시키는 것
- 기존 데이터에서 최적의 모델의 성능을 보여주는 일부 feature subset을 찾아내 학습시키는 것
- 모델 성능을 높일 수 있을 뿐만 아니라 학습에 필요한 메모리와 시간을 줄일 수 있다는 점에서 중요함
- 변수 선택 기법
- Wrappers method : 모델이 가장 좋은 성능을 보이는 feature subset을 선택
- Filtering method : feature간 관계를 통계적 수치로 계산하여 최적의 feature subset을 선택
- Embedded method : 모델 학습 과정에서 내부적으로 feature selection을 진행
2. Wrappers Method

- 여러 feature subset 기반 모델 중 가장 좋은 성능을 보이는 모델의 feature subset을 선택하는 방법
- 각 feature subset에서 모델을 학습시킨 후 예측 성능을 기준으로 최적의 성능을 보인 모델의 feature subset을 선택
- 장점
- validation data에 대하여 최적의 feature subset을 찾을 수 있다. - 단점
- m개의 feature가 있을때 가능한 feature subset 개수가 2^m-1개
- 여러 feature subset에 대해 모델을 학습시키고 정확도를 계산해야하기 때문에 소요되는 시간과 비용이 매우 크다.
- validation set에 대하여 최적의 feature subset을 찾는 것이므로 overfitting의 위험이 있다.
- 전진선택법(Sequential Forward Selection) : 크기가 1인 feature subset에서 시작하여, 통계적으로 유의미한 변수들을 차례대로 추가, 성능 향상이 없을 때까지 변수 추가
- 후진제거법(Sequential Backward Selection/Elimination) : 전체 feature를 모두 사용해 모델링한 다음, 통계적으로 유의하지 않은 변수가 없을 때까지 변수를 제거, 성능 향상이 없을 때까지 변수 추가
- 단계적 선택법(Stepwise Selection) : 전진선택법으로 변수를 추가하다가, 추가되는 변수로 인해 앞선 변수들의 중요도가 낮아지면 제거, 즉 변수를 추가하기 전과 후의 모형 성능을 비교해 성능이 높아질 때까지만 추가
3. Filter Method

- feature간 관계를 통계적 수치로 계산한 후 학습에 중요한 feature subset을 선택하는 방법
- Wrapper method와 달리 모델 학습 전에 feature subset을 결정된다.
- 통계적 수치 = 예측 변수와 특정 feature 간 상관관계가 얼마나 높은지 계산
- correlation coefficient(상관계수) : 피어슨 상관분석, 카이제곱검정
- gain information(불순도) : Pointwise Mutual Information(PMI), Mutual Information(MI)
- 장점
- 계산 시간과 비용이 덜 소요되어 빠르고 효율적이다.
- 대부분 ML 모델 종류에 함께 관계없이 사용될 수 있다. - 단점
- feature 간 관계성이 높다고 해서 꼭 모델 학습에 중요하진 않을 수 있다.
→ Wrapper method를 사용하기 전 전처리용으로 주로 사용된다.
1) Pointwise Mutual Information(PMI)
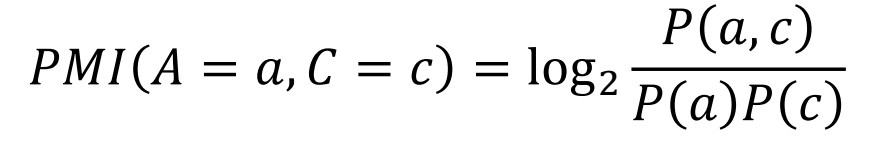
- 두 사건이 함께 발생할 확률과 두 사건이 독립적으로 발생할 확률을 비교
- PMI 값이 클수록 예측 변수와의 상관성이 높음
- PMI > 0 : 사건 A와 B가 positively correlated
- PMI = 0 : 사건 A와 B가 independant
- PMI < 0 : 사건 A와 B가 negatively correlated
2) Mutual Information(MI)
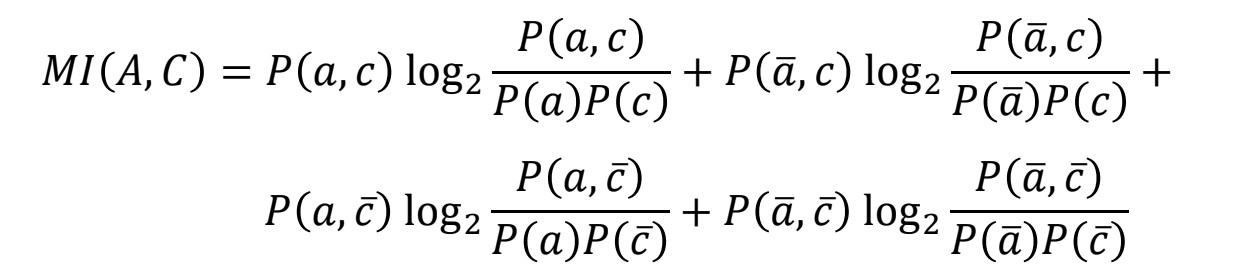
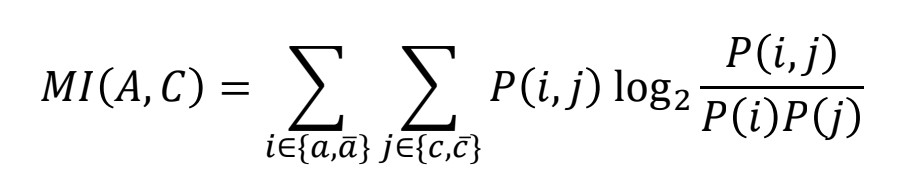
- 두 사건이 함께 발생하는 경우의 PMI 뿐만 아니라 발생하지 않는 경우의 PMI까지 포함한 값
- negatively correlated인 feature도 예측 변수를 예측하는데 정보를 제공한다는 점을 고려
- MI 값이 클수록 예측 변수를 예측하는데 많은 정보를 제공함
4. Embedded Method
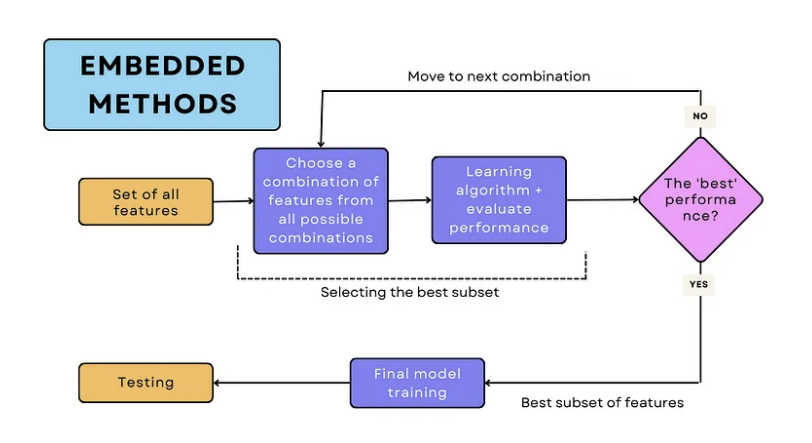
- feature selection을 모델의 학습 과정 동안 진행함
- feature selelction이 모델 학습과 구분되어 진행되는 Wrapper와 Filter method과 달리, 모델 자체에 feature selection 과정이 포함되어 있는 경우
- 모델이 학습 과정에서 성능을 높이는 feature를 선택하고 최적화를 진행함
- 대표적으로 LASSO/Ridge regression, Decision tree 모델은 알고리즘 재부적으로 feature selection을 진행함
- 장점
- 모델이 알아서 변수 선택과 최적화를 진행하기 때문에 효율적이다. - 단점
- 다른 방법에 비해 변수 선택의 이유를 해석하기 어려울 수 있다.
- 일부 ML 알고리즘에만 해당되는 방법이다.
- LASSO/Ridge regression : 회귀계수 추정 과정에서 각각 L1-norm/L2-norm을 통해 제약을 주는 regression with regularisation 모델, 중요하지 않은 feature에겐 회귀계수 값을 0으로 설정함으로써 feature selection이 진행된다.
- Decision trees : 모델을 학습하는 과정에서 feature importance를 계산함을써 feature slelection이 진행된다.
Reference
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=euleekwon&logNo=221465334793
https://wooono.tistory.com/249
https://medium.com/@dancerworld60/exploring-wrapper-methods-for-optimal-feature-selection-in-machine-learning-517ad48c4ac6
https://en.wikipedia.org/wiki/Pointwise_mutual_information
https://arismuhandisin.medium.com/unveiling-the-power-of-embedded-methods-in-machine-learning-a-deep-dive-into-embedded-feature-99a259e9715c
https://medium.com/@learnwithwhiteboard_digest/filter-vs-wrapper-vs-embedded-methods-for-feature-selection-8cc21e2174f7
'교내 수업 > Machine Learning' 카테고리의 다른 글
| [ Week 11-1 ] Unsupervised learning / clustering, GMM, KDE (0) | 2024.05.17 |
|---|---|
| [ Week 9-1 ] Structured Classification (0) | 2024.05.06 |
| [ Week 7-1 ] Classifier combination (1) | 2024.04.20 |
| [ Week 4-2 ] Decision Tree, ID3 algorithm (0) | 2024.03.25 |
| [ Week 3-2 ] Discretisation, Naive Bayes with continuous variable (0) | 2024.03.22 |



