
working_helen
[추천시스템 논문 리뷰] 5주차 : Matrix Factorization, Netflix 본문
[추천시스템 논문 리뷰] 5주차 : Matrix Factorization, Netflix
HaeWon_Seo 2023. 8. 27. 11:40
논문명 : Matrix Factorization Techniques for Recommender Systems
저자명 : Yehuda Koren, Robert Bell and Chris Volinsky
파일 링크 : https://datajobs.com/data-science-repo/Recommender-Systems-[Netflix].pdf
본 논문에서는 Matrix Factorization(MF) 모델이 CF 방식에서 성능이 뛰어난 모델임을 보인다. MF의 원리와 기초적인 수식을 제시한 후 MF의 정확도를 높이기 위해 평점 이외에 다양한 정보를 MF 수식에 적용할 수 있는 방법에 대해 소개한다.
✏️ 논문 내용 요약
1. Collaborative filtering에서 MF은 높은 성능을 보이고 있다.
2. MF는 rating뿐만 아니라 implicit feeedback, temporal dynatics, confidence level 등 추가적인 정보를 통합적으로 사용함으로써 추천시스템의 성능을 높일 수 있다.
0. Abstract
- Matrix Factorization 모델은 고전적인 neighborhood methods CF보다 우수하다.
- implicit feeedback, temporal dynatics, confidence level과 같은 추가 정보도 통합적으로 사용할 수 있다.
1. Introduction
- 오늘날 소비자들의 선택의 폭이 매우 넓어지고 있다.
- 소비자에게 가장 적절한 상품을 제공하는 것이 사용자 만족도와 충성도를 높이는데 중요하기 때문에 추천 시스템에 대한 관심이 높아지고 있다.
- 추천 시스템은 특히 영화, 음악, TV 프로그램 등 엔터테이먼트 상품에 유용하다.
2. Recommender system strategies
추천시스템의 구현 방법으로는 크게 content filltering과 collaborative filtering이 있다.
1) 콘텐츠 필터링 Content filtering (CBF)
The content filtering approach creates a profile for each user or product to characterize its nature.
- 각 user 또는 item의 특징에 대한 프로필을 생성해 특징을 특성화하는 방법
- item profiles : 영화를 예로 들면 장르, 참가 배우들, 그것의 흥행 인기 등
user profiles : 인구 통계학적 정보, 설문지를 통해 제공된 개개인의 답변 등
2) 협업 필터링 collaborative filtering (CF)
Collaborative filtering analyzes relationships between users and interdependencies among products to identify new user-item associations
- user 간의 관계, item 간의 상호 의존성을 분석하여 새로운 uesr-time 관계의 연관성을 식별하는 방법
- profiles를 생성할 필요가 없기 때문에 CBF로 profiles를 정의하기 어려운 데이터에도 적용할 수 있다.
- 이전 거래 내역, 제품 평점 등 과거 user의 행동 데이터에 기반한다. 이로 인해 CBF보다 cold start 문제에 민감하다.
- 협업 필터링에는 아래의 2가지 접근방식이 있다.
2.1) neighborhood methods
Neighborhood methods are centered on computing the relationships between items or, alternatively, between users.
- item 사이, 또는 uesr 사이 관계를 계산하는 것이 중심
▶︎item-oriented approach
: 어떤 item에 대한 특정 user의 선호도를 평가할 때, 해당 item과 유사한 '이웃 아이템들'에 대한 동일 uesr의 평가를 기반으로 판단하는 방식. 한 사용자는 이웃 아이템 간에 비슷한 평가를 준다고 가정한다.
▶︎user-oriented approach
: 어떤 item에 대한 특정 user의 선호도를 평가할 때, 해당 user와 유사한 '이웃 사용자들'의 해당 item에 대한 평가를 기반으로 판단하는 방식. 이웃 사용자들은 서로의 평가를 보완할 수 있다고 가정한다.
user-oriented approach의 예시
Joe는 왼쪽에 있는 3편의 영화를 선호 = 과거 기록
→ Joe가 선호할 법한 영화를 예측하기 위해 3편의 영화를 좋아하는 이웃 사용자들을 찾고, 해당 사용자들이 좋아하는 다른 영화를 확인 = 이웃 사용자의 과거 기록
→ 이웃 사용자 3명이 모두 좋아하는 영화 '라이언 일병 구하기'와 이웃 사용자 2명이 좋아하는 영화 '듄' 순서로 Joe의 추천 영화 리스트를 생성
2.2) Latent factor models
Latent factor models try to explain the ratings by characterizing both items and users on 20 to 100 factors inferred from the ratings patterns
- 평점 패턴으로부터 20~100개의 factor를 추론하고, 이를 이용해 item과 user를 모두를 특성화하는 방법
- factor의 예시 (영화 아이템)
obvious dimensions : 코미디/드라마, 액션의 양, 어린이 중심 정도 등
less well-defined dimensions : 캐릭터 발달의 깊이 등
completely uninterpretable dimensions : 해석할 수 없는 부분
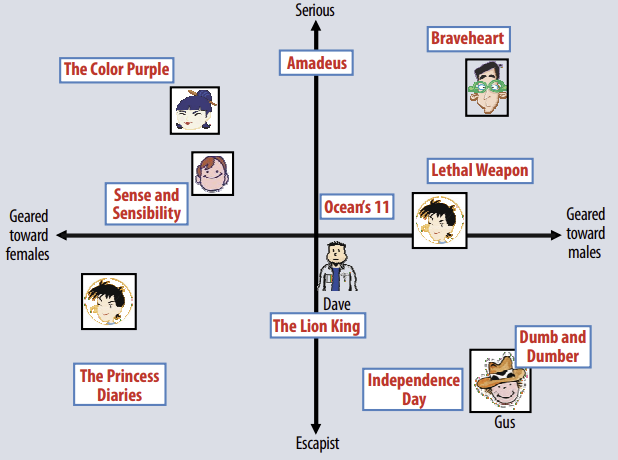
2차원으로 factor 추론 예
여성 지향적/남성 지향적, 진지한 것/현실 도피적인 것
→ 2가지 특징을 이용해 2차원으로 특성화하고, 영화와 사용자들이 어디에 해당되는지 표현했다.
→ 영화의 평균 평점에 대한 각 사용자의 예측 평점은 그래프에서 영화와 사용자 위치 좌표의 내적과 같다.
✏️ CF 방법론 총정리
Memory-based CF (neighborhood methods)
: 사용자 간 혹은 아이템 간 유사성 similarity 값을 계산하여 평점을 예측하고, 이를 활용해 추천 리스트를 작성.
Item-based CF
: 아이템 간의 유사도를 기준으로 추천리스트를 작성 아이템을 사용자로 구성된 벡터로 표현하고 아이템 벡터 간의 유사성을 계산하여 추천리스트를 작성. (행렬 열 간의 유사성을 계산)
User-based CF
: 사용자 간의 유사도를 기준으로 추천리스트를 작성 사용자를 아이템으로 구성된 벡터로 표현하고 사용자 벡터 간의 유사성을 계산하여 추천리스트를 작성.(행렬 행 간의 유사성을 계산)
Model-based CF (Latent factor models)
: 데이터에 숨겨진 User-Item 관계의 잠재적 특성 혹은 패턴 Latent feature를 찾아 평가되지 않은 항목에 대한 사용자의 평가를 예측해 추천 리스트를 작성. 클러스터링 기반 알고리즘, Latent Factor 방식, 딥러닝 알고리즘 등
3. Matrix factorization methods
: 평점 패턴에서 추론한 factor vector로 item과 user를 모두 특성화
→ item과 user factor 간의 높은 상관성이 추천으로 귀결된다.
장점
- Model-based CF Latent Factor 방식에 속하며, 예측 정확도가 높아 최근 인기를 얻고 있다.
- 모델의 확장성과 유연성이 높아 다양한 실제 상황에 적용할 수 있다.
- explicit feedback뿐만 아니라 implicit feedback을 추론에 이용할 수 있다. 이에 따라 explicit feedback 데이터가 부족하거나 너무 sparse한 경우 implicit feedback을 이용해 dense한 행렬로 표현할 수 있다.
✏️ 평점 데이터 = feedback type 정리
explicit feedback : 5점 범위의 평점과 같이 호/불호가 명확히 드러나는 데이터
implicit feedback : 브라우징 이력, 마우스 움직임, 구매 이력, 검색 패턴 등의 숨겨진 데이터
사용자가 장바구니에 담거나 검색하는 등 user의 소비 패턴을 유추할 수 있는 데이터
4. A basic matrix factorization model
- item과 user를 모두 f차원 latent factor space에 매핑
→ latent factor space에서 내적 계산으로 item-user 상호작용을 예측
4.1) latent factor space
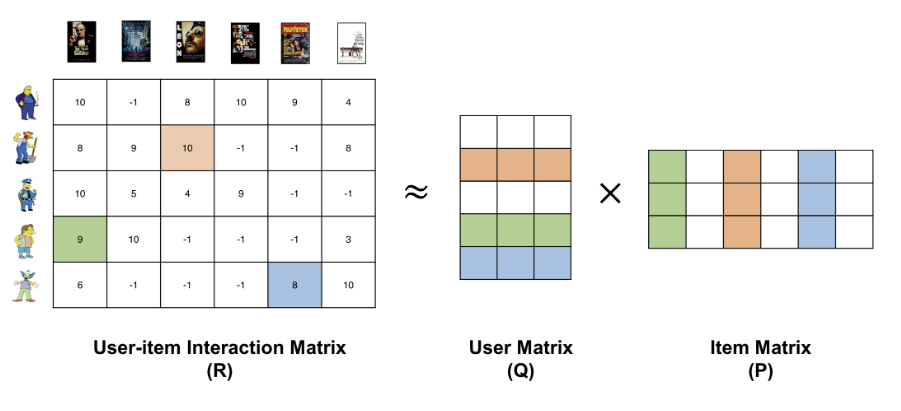

- i : 아이템 / u : 사용자
- f : latent factor space의 차원
- q_i : item latent, item f차원 LFS에 매핑했을 때 vetcor ∈ R^f
- p_u : user latent, user를 f차원 LFS에 매핑했을 때 vector ∈ R^f
- r_ui_hat : i item에 대한 u user의 평점 예측값
4.2) 특이값 분해 SVD (Singular Value Decomposition)
- 예측 평점을 계산하기 위해 item과 user를 (q_i, p_u)에 매핑하는 과정이 필요하다.
= (q_i, p_u)를 학습하는 과정이 필요하다
- 행렬 분해 방법 중 하나인 SVD를 추천시스템에 적용하는 매핑 방법을 사용하고 있다.
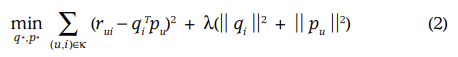
- K : r_ui가 관측된(known) (u, i) set
- λ : regularization 정도를 조절하는 상수 (주로 CV로 결정)
- 관측된 데이터만을 사용하면서 + 과적합 방지를 위한 규제항 포함된 => regularizaed model을 이용한다.
- 위 식을 최소화하는 (q_i, p_u)를 찾는다.
5. Learning Algorithms
▶︎ SGD를 이용해 (q_i, p_u) 학습
모든 데이터에 대해서, 실제 평점 r_ui와 예측 평점 r_ui_hat의 오차 e_ui를 계산
→ γ크기에 비례하여 기울기의 반대 방향으로 q_i, p_u 업데이트
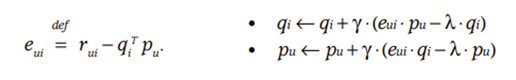
▶︎ ALS를 이용해 (q_i, p_u) 학습
- ALS(Alternating Least Squares) 교대 최소 제곱법을 이용해 q_i와 p_u를 서로 번갈아가면서 업데이트
- 모든 p_u값을 고정한 상태에서 q_i에 대한 least-squares problem을 해결
→ 모든 q_i값을 고정한 상태에서 p_u에 대한 least-squares problem을 해결
→ (2) 수식값이 수렴할 때까지 위 과정을 반복
- 일반적으로 SGD를 사용하나, ALS가 더 효과적인 경우도 있다.
- 병렬화 : p와 q 중 하나를 고정해놓고 교대로 계산하기 때문에 병렬 계산이 가능하다.
- implicit data : implicit data로 채워진 dense matrix의 경우 모든 데이터에 대해 loop 계산을 거치는 SGD보다, 각 케이스를 병렬적으로 처리하는 ALS가 더 효율적이다.
아래부터 MF의 정확도를 높이기 위해 (1)과 (2) 수식에 평점 이외에 다양한 정보를 포함하는 방법을 설명한다.
6. Adding biases
- item-user 상호 작용에 관계없이 item이나 user 자체와 관련된 효과로 인해 bias가 발생한다.
남들보다 평점을 전반적으로 높게/낮게 주는 사용자, 다른 아이템보다 더 나은(또는 더 나쁜) 것으로 인식되는 경우 등
➡️ 상호작용만 고려한 (1) 수식에 개별 item과 user에 의한 bias가 포함될 필요성이 있다.
- (3)은 r_ui와 관련된 전체 bias값을 구하는 식, (4)는 (1)에 (3)을 반영하여 r_ui_hat을 구하는 식이다.


- b_ui : r_ui와 관련된 전체 bias
- μ : 전체 평균 평점
- b_i : 개별 item에 의한 bias / b_u : 개별 user에 의한 bias
- 학습을 위한 regularization term 까지 추가하면 (5) 수식이 된다.
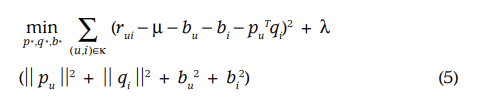
7. Additional input sources
- CF는 cold start 문제를 해결해야한다.
- cold start 문제는 주로 특정 user에 대한 정보가 부족한 경우 발생한다.
➡️ user에 대한 추가적인 정보를 통합적으로 사용하여 q_u를 보완하는 방법을 사용할 수 있다.
- user에 대한 추가 정보로 사용할 수 있는 것
- implicit feedback(preference) : 구매, 검색 이력과 같은 사용자 행동과 관련된 정보
- user attribute : 성별, 나이, 소득 수준과 같은 사용자 자체와 관련된 특성 정보
- (6)은 기존의 p_u에 user에 관한 추가정보가 추가된 enhanced user represontation을 사용한 수식이다.
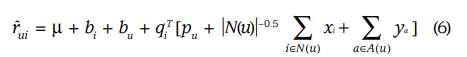
- N(u) : user u가 implicit preference를 보인 아이템들의 set
- x_i : N(u)에 속하는 아이템들들에 대한 item factor
- A(u) : user u와 관련된 사용자 특성
- y_a : A(u)에 속하는 사용자 특성에 대한 attribute factor
8. Temporal dynamics
- Trend : 아이템에 대한 인식과 인기는 시간이 흐름에 따 지속적으로 변화한다.
Taste : 고객의 성향과 취향 또한 시간이 지남에 따라 변화하고 재정의 된다.
➡️ 따라서 추천시스템은 item-user 상호작용에 시간에 따라 변화하는 Temporal dynamics 특성을 반영해야 한다.
- (7)은 b_i, b_u, p_u를 시간 t에 대한 함수로 표현해 동적 특성을 반영한 수식이다.
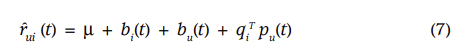
- b_i → b_i(t) : 개별 item의 popularity가 시간에 따라 변함
- b_u → b_u(t) : 개별 user의 inclination이 시간에 따라 변함
- q_u → q_u(t) : 개별 user의 preference가 시간에 따라 변함
9. Inputs with varying confidence levels
- 모든 평점들이 동일한 신뢰도 confidence를 갖지 않는다.
고의적인 별점 테러, implicit feedback 중심의 정보는 신뢰도가 낮다.
➡️ 추정된 선호도에 각 정보에 대한 confidence socre를 포함하는 것이 필요하다.
- confidence socre로 사용할 수 있는 것
- 특정 action의 frequence : 특정 쇼를 얼마나 자주 시청했는지, 특정 품목을 얼마나 자주 구입했는지 등
- (8)은 각 관측 평점 r_ui에 대한 confidence level c_ui를 반영한 수식이다.
더 의미있는 정보에 대하여 더 높은 weight를 부여한다.
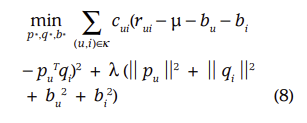
✏️ basic MF를 향상시키는 방법 정리
Adding biases : 개별 item과 user에 의한 bias가 포함
Additional input sources
: implicit feedback, user attribute 등 사용자에 대한 추가적인 정보를 통합적으로 사용하여 q_u를 보완
Temporal dynamics
: item Trend, user Taste 등 시간에 따라 변화하는 Temporal dynamics 특성을 반영
varying confidence levels : 각 정보에 대한 confidence socre를 포함
Reference
2023.08.01 - [deep daiv./추천시스템 스터디] - [추천시스템 학습] 1주차 : 콘텐츠 기반 필터링
2023.08.07 - [deep daiv./추천시스템 스터디] - [추천시스템 학습] 1주차 : 협업 필터링
'deep daiv. > 추천시스템 스터디' 카테고리의 다른 글
| [추천시스템 논문 리뷰] 5주차 : Neural Collaborative Filtering (0) | 2023.08.27 |
|---|---|
| [추천시스템 논문 리뷰] 4주차 : Loss function (0) | 2023.08.26 |
| [추천시스템 논문 리뷰] 3주차 : 경사하강법 / SGD (0) | 2023.08.24 |
| [추천시스템 논문 리뷰] 3주차 : Factorization Machines (2) | 2023.08.23 |
| [추천시스템 논문 리뷰] 3주차 : SVM (0) | 2023.08.23 |



