
working_helen
[추천시스템 논문 리뷰] 3주차 : 경사하강법 / SGD 본문
논문 리뷰 과정에서 접한 경사하강법에 대해 학습해본다.
1. 경사하강법
1) loss function
2) 경사하강법
3) 수식 표현
4) 경사하강법의 문제점
2. Epoch, Iteration, Batch
3. 배치 경사하강법
4. 확률적 경사 하강법
5. 미니배치 확률 경사 하강법
1. 경사하강법
1) loss function
- loss function 손실 함수 : 모델의 파라미터 θ에 따른 예측값과 실제값 사이의 차이인 loss를 계산하는 함수
- loss function 값이 낮아질수록 예측값과 실제값 사이의 차이가 적으므로 더 좋은 모델 파라미터라고 할 수 있다. 즉 loss function 값을 최소화함으로써 최적의 모델 파라미터를 얻을 수 있다.
2) 경사하강법 Gradient Descent
(위키백과) 경사 하강법(傾斜下降法, Gradient descent)은 1차 근삿값 발견용 최적화 알고리즘이다. 기본 개념은 함수의 기울기(경사)를 구하고 경사의 반대 방향으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
: gradient를 이용해 loss fucntion의 최소화하는 가중치 매개변수 θ를 찾는다.
gradient 부호와 반대 방향으로 반복적으로 x를 이동시켜 업데이트함으로써 loss fucntion의 최솟값으로 수렴한다.
- gradient = 1차 미분계수 = loss funtion의 기울기
- gradient의 반대 방향 = loss funtion 함수값이 낮아지는 방향

✅ gradient 부호와 반대 방향 = 함숫값이 작아지는 방향으로 이동
gradient가 양수 = x값이 커질수록 함숫값이 커진다 → 함숫값이 작아지는 방향 = 음의 방향으로 이동
gradient가 음수 = x값이 커질수록 함숫값이 작아진다 → 함숫값이 작아지는 방향 = 양의 방향으로 이동
✅ gradient의 절댓값을 기준으로 얼마나 이동할지(step size) 조
gradient 절댓값이 크다 = x의 위치가 최소값 위치에서 멀다 → 많이 이동한다
gradient 절댓값이 작다 = x의 위치가 최소값 위치와 가깝다 → 조금만 이동한다
3) 수식 표현

f(x) : 최적화할 함수
x_0 : 초기 시작점
x_i : i번째에 계산된 x 좌표
x_i+1 : i+1번째에 계산된 x 좌표
r_i : step size 이동거리 값, learning rate 학습률
x_i 위치에서 step size x gradient 만큼 이동하여 x_i+1 위치로 업데이트한다.
4) 경사하강법의 문제점
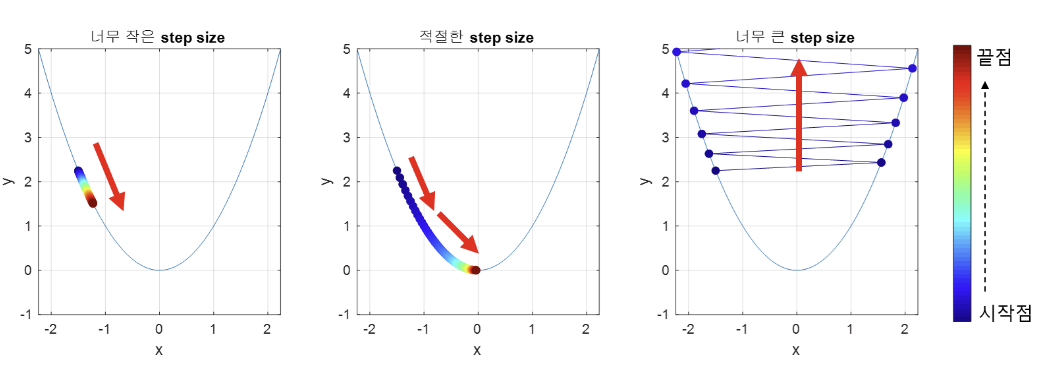
▶︎ 적절한 step size 설정
- step size가 큰 경우
장점 : 한 번 이동하는 거리가 크므로 빠르게 최솟값으로 수렴할 수 있다.
단점 : 너무 크면 최소값으로 수렴하지 못하고 함숫값이 커지는 방향으로 발산하는 현상이 발생한다.
- step size가 작은 경우
장점 : 함숫값이 발산하는 문제를 방지할 수 있다.
단점 : 이동거리가 너무 작아 최소값으로 수렴하는데 많은 시간이 소요되거나 수렴하지 못할 수 있다.
- 이러한 이유로 적절한 step size를 설정하는 것이 매우 중요하다. 하지만 step size를 정하기 위한 체계적인 알고리즘이 없어 직접 실행해보며 최적값을 찾아야한다는 문제가 있다.
▶︎ 다른 최솟값으로 수렴
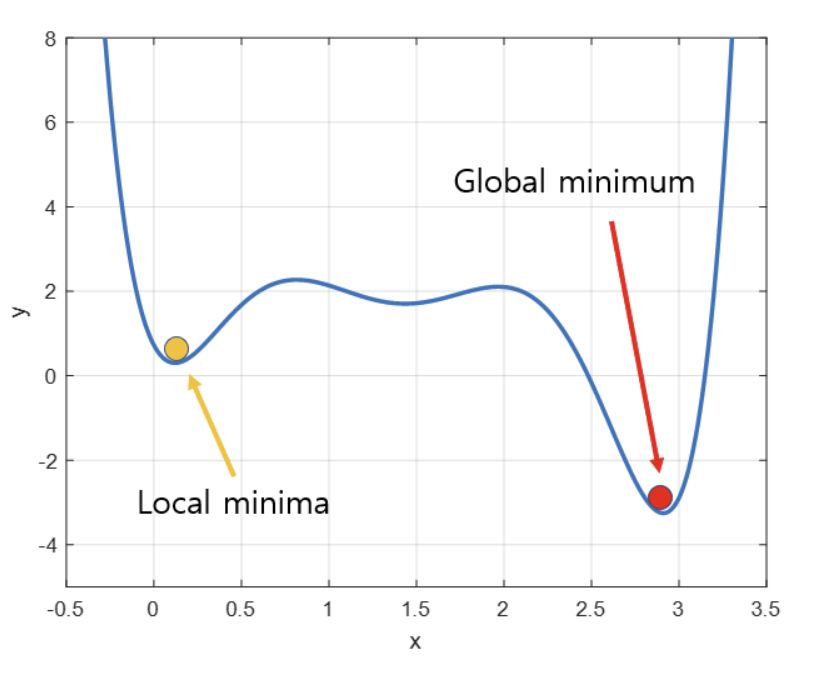
- Gradient Descent의 초기 시작점은 무작위로 선택되는데, 이 시작점에 따라 수렴하는 값이 달라질 수 있다.
- step size가 작은 경우 전역 최소값(global minimum)이 아닌 지역 최소값(local minimum)에 수렴할 수 있다.
- gradient 값이 크지 않은 경우 = 기울기가 완만한 구역에 존재하는 경우 최솟값을 구하는데 시간이 오래 걸리거나 도달하지 못하는 문제가 발생할 수 있다.
2. Epoch, Iteration, Batch
1) Epoch
One Epoch is when an ENTIRE dataset is passed forward and backward
: 전체 train set를 1번 사용하는 과정, 전체 data에 대해 1번 학습을 완료한 상태를 의미
- epochs = 10이라면 전체 데이터에 대한 학습 과정을 10번 완료했다는 의미이다.
- 대부분의 모델은 학습 과정에서 Gradient Descent와 같이 여러 번의 최적화 과정을 거친다. 하지만 이러한 iterative 최적화 과정은 많은 메모리와 연산을 요구하기 때문에 데이터가 많은 경우 1번의 epoch에서 모든 데이터를 사용해 학습하는 것이 어렵다. 따라서 batch와 iteration의 개념을 도입해 일부 데이터를 사용한 반복으로 모델을 학습시키는 방법을 사용한다.
2) Iteration과 Batch
iteration : The number of passes to complete one epoch
batch(배치) : Total number of training examples present in a single batch.
iteration : 1개의 epoch에서 수행한 반복 학습의 횟수 = 전체 data를 몇 번 나누어 학습하는가
batch : 일괄적으로 처리되는 집단, 1 epoch에 사용되는 data size= 각 iteration마다 몇 개의 data를 쓰는가
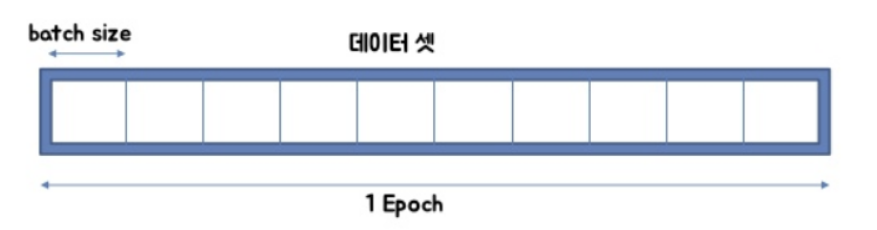
➡️ epoch는 전체 data를 모두 사용하여 학습하는 1번의 과정을 의미
epoch 1번 → batch만큼의 data를 사용하는 sub 학습 iteration번으로 나누어서 전체 data를 학습한다.
전체 data 개수 = batch size x iteration 횟수
예) 전체 data 1000개, epochs = 20, batch_size = 200인 경우
=> 1 epoch마다 data size가 200인 batch를 사용하는 5번의 iteration으로 학습하며,
총 20번의 epoch를 진행한다. 따라서 학습은 총 5*20=100번 이루어진다.
3) Epoch와 Batch 설정
- 모델 적합시 적절한 epoch와 batch 값을 설정해야한다.
- epoch 값이 너무 작다면 underfitting이, 너무 크다면 overfitting이 발생할 확률이 높다.
- batch size가 너무 작으면 적은 데이터를 대상으로 업데이트가 이루어지므로 학습이 불안정할 수 있고,
batch size가 너무 크면 처리해야할 데이터가 많아져 메모리 부족이나 학습 속도 저하로 이어질 수 있다.
4) Batch에 따른 경사하강법 종류
Gradient Descent에서 batch size = 각 업데이트 반복에서 gradient를 계산하는 사용하는 data의 개수
- 배치 경사하강법(Batch gradient descent)
- 확률적 경사 하강법(SGD)
- 미니배치 확률 경사 하강법 (Mini-Batch Stochastic Gradient Descent)
3. 배치 경사하강법 (Batch gradient descent, BGD)
: batch size = 전체 data / batch size가 전체 data 크기인 경사하강법
전체 train data에 대한 loss를 구하고, gradient를 1번만 계산해 모델 파라미터를 업데이트하는 학습 방법
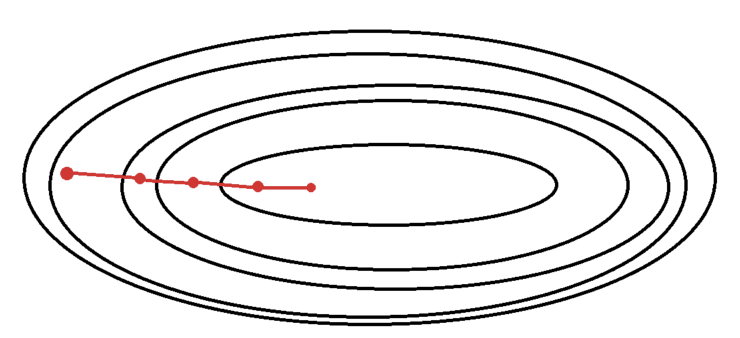
장점 : 1 epoch마다 1번만 업데이트를 진행하기 때문에 연산 횟수가 적다.
최솟값까지 부드럽게 값이 감소하기 때문에 안정적인 수렴이 가능하다.
단점 : 데이터가 큰 경우 필요한 메모리나 계산량이 크다.
한번 local minimum에 도달하면 빠져나오기 어렵다.
4. 확률적 경사 하강법 (Stochastic Gradient Desenct, SGD)
: batch size = 1 / batch size가 1인 경사하강법
매 학습마다 train data에서 무작위로 딱 1개의 데이터를 선택하고, 해당 데이터에 대해서만 loss function의 gradient를 계산하여 모델을 업데이트하는 학습 방법
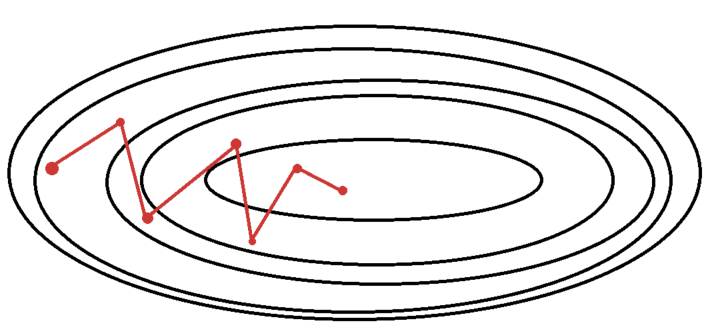
- 장점 : 1개의 데이터만 처리하기 때문에 각 학습의 속도가 매우 빠르고, 소요되는 메모리도 적다.
local minimum에 도달하더라도 쉽게 빠져나올 수 있어 BGD보다 global minimum을 찾을 가능성이 높다.
- 단점 : 무작위로 선택된 1개의 데이터로 업데이트를 진행하기 때문에 오차율이 크고, 최적해에 도달하지 못할 수 있다.
큰 진폭으로 요동치면서 수렴 과정에서 Shooting 등의 노이즈가 많이 발생한다.
이에 따라 BGD보다 최솟값으로 불안정하게 수렴한다.
5. 미니배치 확률 경사 하강법 (Mini-Batch Stochastic Gradient Descent, MSGD)
: batch size = 사용자 지정
전체 data를 batch size 크기의 batch로 나누고, 각 batch에 대하여 경사하강법을 수행하는 학습 방법
각 batch의 loss값의 평균에서 gradient를 계산하는 경사하강법으로 모델 파라미터를 업데이트하는 방법
예) 전체 data 1000개, batch_size = 200인 경우
1번의 epoch에서 10개의 batch에 대하여 SGD를 수행하여, 1 epoch당 10번의 경사하강법이 수행된다.
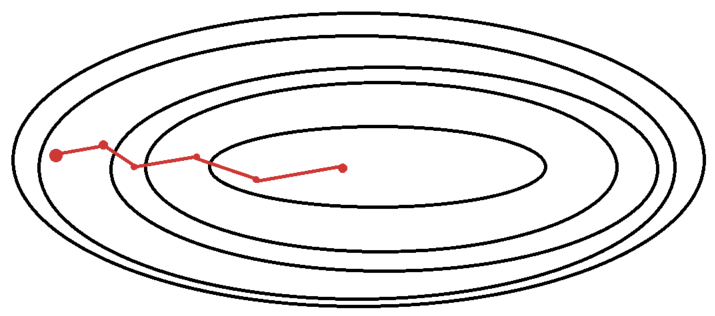
- 장점 : 1개의 데이터가 아닌 batch의 평균 loss로 gradient를 계산하기 때문에 SGD에서의 shooting 문제를 줄인다.
BGD에 비해 local Minimum 문제가 적다.
- 최근에는 SGD라고 하면 MSGD를 의미하는 것으로 받아들여진다.
Reference
[경사 하강법]
https://ko.wikipedia.org/wiki/%EA%B2%BD%EC%82%AC_%ED%95%98%EA%B0%95%EB%B2%95
https://hi-guten-tag.tistory.com/205
https://angeloyeo.github.io/2020/08/16/gradient_descent.html
[SGD]
https://mangkyu.tistory.com/62
https://m.blog.naver.com/qbxlvnf11/221449297033
https://velog.io/@arittung/DeepLearningStudyDay8
https://skyil.tistory.com/68
'deep daiv. > 추천시스템 스터디' 카테고리의 다른 글
| [추천시스템 논문 리뷰] 5주차 : Matrix Factorization, Netflix (3) | 2023.08.27 |
|---|---|
| [추천시스템 논문 리뷰] 4주차 : Loss function (0) | 2023.08.26 |
| [추천시스템 논문 리뷰] 3주차 : Factorization Machines (2) | 2023.08.23 |
| [추천시스템 논문 리뷰] 3주차 : SVM (0) | 2023.08.23 |
| [추천시스템 학습] 1주차 : 협업 필터링 (0) | 2023.08.07 |



