
working_helen
[추천시스템 학습] 1주차 : 콘텐츠 기반 필터링 본문
1. 콘텐츠 기반 필터링
2. 콘텐츠 기반 필터링 과정
3. 콘텐츠 기반 필터링 장단점
4. Pandora 음악 추천시스템 - 콘텐츠 기반 필터링 사례
5. 카카오 페이지 추천시스템 - 콘텐츠 기반 필터링 사례
1. 콘텐츠 기반 필터링(Content-Based Filtering, CBF)
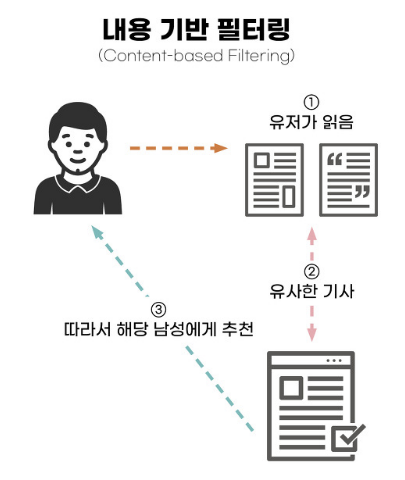
: 사용자가 선호하거나 사용한 적 있는 아이템과 비슷하고 관련된 아이템으로 추천하는 추천 시스템 방법이다. 사용자의 과거 사용 데이터를 기반으로 해당 사용자가 좋아할 법한 콘텐츠(content)를 가지고 있는 유사한 새로운 아이템을 찾아 추천한다.
다루는 문제 : 개별 사용자마다의 아이템 호불호 분류 문제
사용 데이터 : 사용자의 과거 아이템 사용 이력 + 각 아이템의 특징 정보(콘텐츠 content)
제시하는 답 : 아이템의 content를 기반으로 해당 사용자의 각 아이템에 대한 호불호를 분류
> 사용자가 좋아할 법한 content를 가진 새로운 아이템 선정
2. 콘텐츠 기반 필터링 과정
각 아이템을 행으로, 아이템의 특성을 열로, 특성의 유무를 성분으로 하는 Matrix
step 1. 아이템을 특성을 이용해 벡터 형태로 표현한다.
step 2. 아이템 간 유사도를 계산한다.
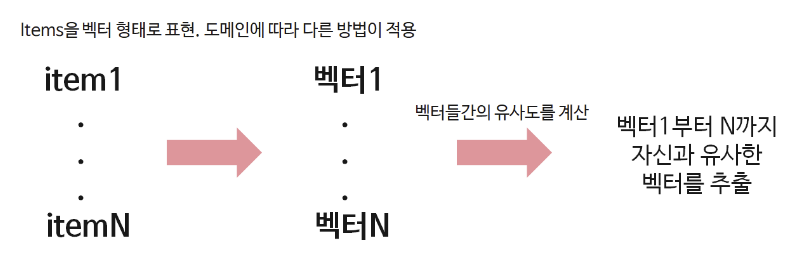
step 1. 아이템을 특성을 이용해 벡터 형태로 표현 = 임베딩(Embedding)
임베딩(Embedding)이란?
: 자연어와 이미지처럼 수치화되어 있지 않는 데이터를 특징 추출을 통해 컴퓨터가 처리할 수 있는 벡터 형태로 수치화해주는 방법. 특히 자연어 처리와 관련해 다양한 임베딩 기법이 발전해오고 있다.
1) 원 핫 인코딩(One-hot encoding)
- 범주형 데이터를 벡터로 표현하는 방법
- 범주의 개수와 같은 크기의 벡터에 대하여 0과 1을 사용해 어떤 범주에 속하는지 표현한다. 아래과 같이 속하는 범주에 대해선 1을, 그 외의 범주에 대해선 0을 성분으로 두어 어떤 범주에 속하는지 표현한다. (데이터 특징에 따라 0과 1외의 실수값을 사용하기도 한다.)
- 단어 임베딩의 경우 문장에서 특정 단어의 출현 여부를 0과 1로 표현하여 임베딩할 수 있다.

2) TF-IDF 기반 임베딩
- One-hot encoding과 유사하게 단어의 출현 여부를 기준으로 벡터로 표현하되, 벡터 성분으로 TF-IDF의 값을 사용한다.

- TF-IDF(Term Frequency - Inverse Document Frequency)란?
: TF(단어 빈도, term frequency)와 DF(문서 빈도, document frequency)를 사용하여 어떤 단어가 특정 문서 내에서 얼마나 자주 등장하는지를 표현한 통계적 가중치이다.
- TF는 문서 내에 특정 단어가 등장한 빈도로, 값이 높을수록 해당 문서에서 중요한 단어라고 할 수 있다.
- DF는 문서군에서 해당 단어가 등장하는 문서들의 수로, 값이 높을수록 해당 단어가 여러 문서에서 흔하게 등장한다는 것을 의미하며, 역수를 IDF(역문서 빈도, inverse document frequency)라고 한다.
- TF가 높고 DF가 작을수록(IDF가 높을수록) 해당 단어는 다른 문서에는 잘 나오지 않지만 특정 문서에는 매우 빈번하게 등장한다는 것을 의미한다.
- TF-IDF는 TF와 IDF를 곱한 값이며, 해당 값이 높을수록 특정 문서에 해당 단어가 중요하다는 것을 의미한다.
- TF-IDF 기반 임베딩에서는 단어가 존재하는 경우 단순히 1이 아닌 TF-IDF 값을 성분값으로 가지도록 한다.
1)과 2)의 경우 범주의 개수와 같은 크기의 벡터를 사용하기 때문에 범주가 너무 넓거나 복잡하면 표현에 필요한 데이터가 너무 많아져 메모리 낭비 및 계산 복잡도가 커진다. 예를 들어 하나의 문장을 단어를 기준으로 One-hot encoding하면 총 단어의 개수만큼의 긴 길이의 벡터를 사용해야 하지만, 각 벡터가 0이 대부분인 매우 sparse한 형태의 고차원 벡터로 표현되는 문제가 존재한다.
step 2. 아이템 벡터 간 유사도 계산
벡터 간 유사도를 계산해주는 유사도 함수를 사용하며, 다양한 종류의 유사도 함수가 존재하며, 각 유사도 함수의 특징과 데이터의 특징을 바탕으로 적절한 함수를 선택하여 사용한다.
1) 유클리디안 유사도
- 두 벡터 간 유클리드 거리로 유사도 지표로 사용한다.
- 값이 작을수록 두 벡터가 인접하기 때문에 유사하다.
- 유클리디안 유사도 = 1 / (유클리디안 거리 + 1e-05)
2) 코사인 유사도
- 두 벡터 간 사잇를 유사도 지표로 사용한다.
- -1~1의 값을 가지는데, -1은 서로 방향이 완전히 반대인 경우, 0은 두 벡터가 서로 독립적인 경우, 그리고 1은 서로 완전히 같은 경우를 의미한다. 1에 가까울수록 유사도가 높다고 할 수 있다.
- 벡터의 크기나 거리보단 방향의 유사성을 우선시한다.
3) 피어슨 유사도
- 피어슨 상관계수를 유사도 지표로 사용한다.
3. 콘텐츠 기반 필터링 장단점
1) 장점
- 다른 사용자의 데이터 혹은 사용자 간 상호작용에 대한 데이터가 필요없다.
- 아이템 간 어떤 content의 유사성을 근거로 추천한 것인지 파악할 수 있어 추천의 근거를 설명하기 좋다.
- 항목 데이터로 인한 Cold Start 문제가 적다.
(위키백과) Cold Start : 시스템이 아직 충분한 정보를 수집하지 않은 사용자 또는 항목에 대해 추론할 수 없다는 문제
아이템의 content 데이터만을 사용하기 때문에 사용 이력 데이터가 충분히 쌓이지 않은 새로운 아이템이나 유명하지 않은 아이템도 추천 대상에 포함할 수 있다.
2) 단점
- 개별 사용자의 과거 사용 이력에 대한 데이터가 필요하다. 즉 새로운 사용자에 대해서는 Cold Start 문제가 존재한다.
- 아이템의 content를 추출하고 정의하는 과정에서 정확도가 떨어질 수 있다. 예를 들어, 특정 영상물이 ‘지루하다’, ‘잔잔하다’, ‘일상적이다’ 등의 표현의 다양성으로 인해 같은 작품에 대해서도 사람에 따라 다르게 평가할 수 있다.
- 필터 버블 문제 (추천 대상의 다양성 부족)
: 추천시스템이 사용자의 취향과 관심사에 치중하여 정보를 제공하면서 사용자가 반복적으로 특정 성격의 정보만 접하게 되는 현상. 사용자가 자신의 관심사에서 벗어난 다양한 정보를 접하는 것을 방해한다. 콘텐츠 기반 필터링의 경우 이미 사용자가 선호하는 아이템과 유사한 아이템을 추천하는 원리로 인해 이외의 영역에 있는 아이템이 추천 대상에서 지속적으로 제외될 수 있는 문제가 있다. 따라서 새로운 영역의 아이템을 추천하는 것이 어렵다.
(위키백과) 필터 버블(filter bubble)은 개인화된 검색의 결과물의 하나로, 사용자의 정보(위치, 과거의 클릭 동작, 검색 이력)에 기반하여 웹사이트 알고리즘이 선별적으로 어느 정보를 사용자가 보고싶어 하는지를 추측하며 그 결과 사용자들이 자신의 관점에 동의하지 않는 정보로부터 분리될 수 있게 하면서 효율적으로 자신만의 문화적, 이념적 거품에 가둘 수 있게 한다.
4. Pandora 음악 추천시스템 - 콘텐츠 기반 필터링 사례
1) Pandora 판도라

: 미국의 음악 스트리밍 서비스로 “Music Genome Project”와 “Matching Algorithm”을 활용한 음악 추천을 주요 서비스로 제공하고 있다. (현재 한국에서는 사용 불가)
(위키백과) 판도라(Pandora)는 뮤직 게놈 프로젝트에 기반한 자동 음악 추천 시스템 및 인터넷 라디오 서비스이다.
2) Music Genome Project
- 사람을 개인의 유전자 정보 게놈(Genome)으로 해석하듯이, 각각의 노래를 음악적 게놈으로 정의하려는 프로젝트
- 약 450개의 음악 attribute를 사용하여 노래의 Music Genome을 표현한다. melody, harmony, rhythm, instrumentation, vocal performance 등의 영역에서 가장 기본적인 음악적 요소들이 attribute에 포함된다.
- 판도라는 musicians 집단을 고용하여 각 노래의 attribute를 수동 분류하여 DB로 저장하는 작업을 진행했다. musicians는 하루 종일 노래를 들으며 각 노래마다 450여 개의 attributes를 부여하는 작업을 진행한다.
3) Matching Algorithm
- Music Genome Project를 통해 분류한 노래의 attribute 데이터를 기반으로 콘텐츠 기반 필터링 기법을 적용한다.
- 사용자가 자신이 좋아하는 곡 혹은 음악가 정보를 제공하면 해당 음악의 attribute와 유사한 attribute를 가진 새로운 음악을 들려준다. 사용자는 추천 음악에 대해 “thumbs up” 혹은 “thumbs down” 반응을 제시할 수 있으며, 판도라는 해당 반응을 데이터로 활용해 더 정교하게 다음 곡을 추천해준다.
- 판도라의 추천시스템은 다른 사용자의 데이터를 사용하지 않는다. 각 사용자가 좋아하는 곡에 대한 정보와 곡의 attribute에 대한 DB만을 사용하여 해당 사용자가 좋아할 법한 음악을 재생해주는 개인화된 채널을 제공한다.
4) 현재와 전망
- 판도라의 추천시스템의 경우 노래마다 attribute를 분석하여 DB에 추가하는 과정에서 효율성 문제가 존재한다. musicians 기반의 집단에서 수동적으로 해당 작업을 진행하고 있기 때문에 새로운 곡을 추가할 때마다 많은 시간과 인력이 필요하다.
- 최근 Apple Music도 유튜브, 시리 등 자사 서비스를 결합한 음악 스트리밍 및 추천 서비스를 발표하면서 미국 내 맞춤형 음악 서비스 산업에서 경쟁하고 있다.
5. 카카오 페이지 추천시스템 - 콘텐츠 기반 필터링 사례
1) 카카오 페이지

카카오에서 운영하는 모바일 콘텐츠 제공 서비스로 웹툰, 웹 소설, 영상 등을 유통하고 있다.
(위키백과) 카카오페이지(kakaopage)는 카카오엔터테인먼트가 운영하는 콘텐츠 플랫폼으로, 웹툰과 웹소설 등이 연재되고 있다.
2) 연관 추천 알고리즘

- 카카오 페이지는 구독자들에게 새로운 작품을 추천하기 위해 콘텐츠 기반 연관 추천시스템을 사용하고 있다.
- 사용자가 작품 소개를 보러 들어오거나 한 작품을 끝까지 보고 최종화의 마지막에 도착했을 때, 해당 작품과 유사한 다른 작품을 추천해주는 방식이다.
- 작품의 제목과 소개 텍스트를 데이터로 활용해 작품의 attribute를 파악한다.
- TF-IDF 가중치 혹은 Word2Vec 등의 알고리즘을 활용해 각 작품을 벡터 형태로 표현한다. 벡터화를 통해 각 작품은 벡터 공간상의 하나의 점으로 대응된다.
- 각 작품 벡터 간 유사성을 비교하여 추천 리스트를 선정한다. 또한 추천 이후 독자들의 반응(긍정 혹은 무관심 등)을 실시간으로 다음 추천 결과에 반영하는 실시간 최적화를 진행한다.
3) 현재 및 전망
(매일경제) 종합 콘텐츠 기업 카카오엔터테인먼트가 업계 최초로 자체 인공지능(AI) 브랜드 '헬릭스(Helix)'를 내놓는다. 웹툰·웹소설부터 음악, 드라마·영화 등에 이르기까지 카카오엔터테인먼트 지식재산권(IP) 사업 전반에 걸쳐 헬릭스로 명명되는 AI 라인업을 구축·확대하겠다는 것이다.
출처 : https://www.mk.co.kr/news/it/10777358
- 카카오 추천팀에서 다양한 추천시스템을 개발하고 이를 카카오페이지에 적용해보는 방식으로 발전해오고 있다.
- 가장 최근에는 카카오 자체 AI '헬릭스(Helix)'를 활용한 추천 알고리즘 도입이 진행되고 있으며, 특히 헬릭스의 첫 서비스로 2023년 7월 6일부터 카카오 페이지에 ‘핼릭스 푸시’ 서비스가 시작되었다.
- 헬릭스 푸시는 AI가 카카오 페이지 이용자의 콘텐츠 이용 데이터를 학습하여 최적의 시점에 독자의 선호 예상 웹툰과 웹소설을 추천하고, 캐시 및 이용권 등 혜택 관련 정보를 알려주는 서비스이다.
- 카카오 엔터테인먼트는 헬릭스 푸시를 시작으로 헬릭스라는 브랜드명 아래 AI 서비스를 확대해나갈 계획이다.
Reference
[콘텐츠 기반 필터링]
https://en.wikipedia.org/wiki/Recommender_system
https://ko.wikipedia.org/wiki/Tf-idf
https://tech.kakao.com/2021/12/27/content-based-filtering-in-kakao/
https://www.blog.cosadama.com/articles/2021-practicenlp-03/
https://eda-ai-lab.tistory.com/524
https://abluesnake.tistory.com/111
https://casa-de-feel.tistory.com/28
https://en.wikipedia.org/wiki/Pandora_(service)
https://en.wikipedia.org/wiki/Music_Genome_Project
https://www.semanticscholar.org/paper/Pandora-%E2%80%99-s-Music-Recommender-Howe/f6356c70452b3f56dc1ae07b4649a80239afb1b6 (Pandora’s Music Recommender. Michael Howe)
https://towardsdatascience.com/recommender-systems-in-practice-cef9033bb23a
'deep daiv. > 추천시스템 스터디' 카테고리의 다른 글
| [추천시스템 논문 리뷰] 4주차 : Loss function (0) | 2023.08.26 |
|---|---|
| [추천시스템 논문 리뷰] 3주차 : 경사하강법 / SGD (0) | 2023.08.24 |
| [추천시스템 논문 리뷰] 3주차 : Factorization Machines (1) | 2023.08.23 |
| [추천시스템 논문 리뷰] 3주차 : SVM (0) | 2023.08.23 |
| [추천시스템 학습] 1주차 : 협업 필터링 (0) | 2023.08.07 |



