
목록전체 글 (101)
working_helen
 프로그래머스 코딩테스트 연습 Lv4
프로그래머스 코딩테스트 연습 Lv4
프로그래머스 MySQL Lv4FOOD_PRODUCT 테이블 : PRODUCT_ID, PRODUCT_NAME, PRODUCT_CD, CATEGORY, PRICE는 식품 ID, 식품 이름, 식품코드, 식품분류, 식품 가격을 의미 식품분류별 가장 비싼 식품의 정보 조회하기 : 식품분류별로 가격이 제일 비싼 식품의 분류, 가격, 이름을 조회하는 SQL문을 작성해주세요. 이때 식품분류가 '과자', '국', '김치', '식용유'인 경우만 출력시켜 주시고 결과는 식품 가격을 기준으로 내림차순 정렬해주세요. 풀이 1- WHERE절 서브쿼리 사용- 같은 테이블 간 비교이므로 테이블 별칭 사용해주기 SELECT CATEGORY, PRICE AS MAX_PRICE, PRODUCT_NAMEFROM FOOD_PRODUCT ..
 프로그래머스 코딩테스트 연습 Lv3
프로그래머스 코딩테스트 연습 Lv3
프로그래머스 MySQL Lv3ANIMAL_INS 테이블 ANIMAL_OUTS 테이블 : ANIMAL_ID, ANIMAL_TYPE, DATETIME, NAME, SEX_UPON_OUTCOME는 각각 동물의 아이디, 생물 종, 입양일, 이름, 성별 및 중성화 여부를 나타냄. ANIMAL_OUTS 테이블의 ANIMAL_ID는 ANIMAL_INS의 ANIMAL_ID의 외래 키 풀이 1 - NOT IN 연산자 사용 SELECT NAME, DATETIMEFROM ANIMAL_INSWHERE ANIMAL_ID NOT IN (SELECT ANIMAL_ID FROM ANIMAL_OUTS)ORDER BY 2LIMIT 3 풀이 2 - OUTER JOIN 사용 SELECT A.NAME, A.DATETIMEFROM ANIMAL..
 프로그래머스 코딩테스트 연습 Lv2
프로그래머스 코딩테스트 연습 Lv2
프로그래머스 MySQL Lv2 PRODUCT 테이블 가격대 별 상품 개수 구하기 : 만원 단위의 가격대 별로 상품 개수를 출력하는 SQL 문을 작성해주세요. 가격대 정보는 각 구간의 최소금액(10,000원 이상 ~ 20,000 미만인 구간인 경우 10,000)으로 표시해주세요. 결과는 가격대를 기준으로 오름차순 정렬해주세요. 풀이- Oracle TRUNC(숫자, 위치 n) / MySQL TRUNCATE(숫자, 위치 n) : 버림 연산, n이 양수면 소수점 n번째 자리까지 유지, n이 음수면 정수 n번째에서 버림- Oracle과 MySQL 모두 실행 순서는 GROUP BY → SELECT지만 GROUP BY 1에서의 1은 SELECT절의 컬럼 위치를 참조하는 문법적 표현으로 사용 가능 (GROUP ..
 프로그래머스 코딩테스트 연습 Lv1
프로그래머스 코딩테스트 연습 Lv1
프로그래머스 MySQL Lv1 ANIMAL_INS 테이블 아픈 동물 찾기 : 동물 보호소에 들어온 동물 중 아픈 동물1의 아이디와 이름을 조회하는 SQL 문을 작성해주세요. 이때 결과는 아이디 순으로 조회해주세요. 풀이- ORDER BY에서 숫자를 사용해 정렬에 사용할 칼럼이 무엇인지 지정 가능 SELECT ANIMAL_ID, NAMEFROM ANIMAL_INSWHERE INTAKE_CONDITION = 'Sick'ORDER BY ANIMAL_IDSELECT ANIMAL_ID, NAMEFROM ANIMAL_INSWHERE INTAKE_CONDITION = 'Sick'ORDER BY 1 역순 정렬하기: 동물 보호소에 들어온 모든 동물의 이름과 보호 시작일을 조회하는 SQL문을 작성해주세요. 이때 결과는..
 프로그래머스 코딩테스트 연습 Lv1
프로그래머스 코딩테스트 연습 Lv1
프로그래머스 MySQL Lv1 FOOD_FACTORY 테이블: FACTORY_ID, FACTORY_NAME, ADDRESS, TLNO는 각각 공장 ID, 공장 이름, 주소, 전화번호를 의미합니다. 강원도에 위치한 생산공장 목록 출력하기문제 : FOOD_FACTORY 테이블에서 강원도에 위치한 식품공장의 공장 ID, 공장 이름, 주소를 조회하는 SQL문을 작성해주세요. 이때 결과는 공장 ID를 기준으로 오름차순 정렬해주세요. 풀이 1 SELECT FACTORY_ID, FACTORY_NAME, ADDRESSFROM FOOD_FACTORYWHERE ADDRESS LIKE '강원도%'ORDER BY FACTORY_ID - LIKE : 부분적으로 일치하는 문자열을 찾을 때_ : 모든 글자, 한 글자 % : 모..
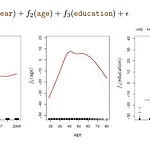 [R로 하는 통계분석] GAM(Generalized Additive Models)
[R로 하는 통계분석] GAM(Generalized Additive Models)
1. GAM (Generalized Additive Models)2. GAM R 코드로 구현하기 1. GAM (Generalized Additive Models)" 각 feature에 대한 비선형 함수를 선형결합 "= 각각의 설명변수 xj에 대해선 비선형 함수 fj(xij)를 적합 + fj(xij)들을 선형결합 - 각 fj는 glm, spline, identity 등 단일변수로 y를 예측하는 어떠한 모델이든 사용 가능 - linear additivity 유지함으로써 fj를 단순히 선형결합하여 최종 모델 적합 GAM regression 모델링 예시 `year` : natural spline, 자유도 4`age` : natural spline, 자유도 5 `education` : step function..
 [R로 하는 통계분석] Piecewise polynomial regression, Splines
[R로 하는 통계분석] Piecewise polynomial regression, Splines
1. Piecewise polynomial regression2. Spline3. Spline R 코드로 구현하기 1. Piecewise polynomial regression(1) piecewise polynomial regression - 설명변수 X를 여러 개의 구간을 분할하고, 각 구간마다 별도의 다항회귀모형을 적합하는 방법 - 구간마다 각각 LSE를 적용해 회귀계수 β를 추정 - knots : 회귀모형이 바뀌는 X의 지점, K개의 knots가 있으면 K+1개의 구간이 생성 (2) basis function- piecewise polynomial regression은 basis function approach의 일종- 이미 알고있는 basis function(기저 함수) K개의 선형결합으..
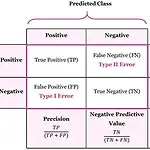 [R로 하는 통계분석] Classification 모델 적합과 평가
[R로 하는 통계분석] Classification 모델 적합과 평가
1. Logistic regression2. LDA3. QDA4. Naive Bayes model5. classification model evaluation 1. Logistic Regression: Binary Classification 반응변수 Y의 class가 0 또는 1 - q = P(Y=1) = E(Y) f(q) = logit(q) = log(q/(1- q)) = log(odds ratio) = Xβ- 주어진 x에 대한 결과 Y가 1이 될 확률의 예측값을 계산 예측된 확률에 적절한 threshold를 사용해 0 또는 1로 분류 (보통 0.5를 threshold로 사용) - β = logit(P(Y=1))의 변화량 = log(odds ratio)의 변화량 exp(β) = odds..
 [리뷰 감정분석] Llama를 이용한 리뷰 감정분석
[리뷰 감정분석] Llama를 이용한 리뷰 감정분석
각 리뷰들에 대하여 긍정/부정/중립 감정을 라벨링하는 감정분석을 진행한다. LLM 프롬프트 엔지니어링을 사용해 감정분석을 진행한 과정에 대해 정리해본다. 1. Llama few-shot prompting2. 감정분석 결과 ▶ KcELECTRA을 fine-tuning 모델을 활용한 리뷰 감정 분석 : ELECTRA 모델에서 감정분석 성능이 좋지 않았음 → 모델 크기가 더 큰 LLM에 해당하는 Llama 사용 시도 2024.09.06 - [deep daiv./NLP project] - [리뷰 감정 분석] KOTE 논문 리뷰 / KOTE fine-tuning 모델을 활용한 감정 분석 [감정 분석] 한국어 감정 분석 데이터셋 KOTE 논문 리뷰 / Python에서 KOTE 모델 사용하기마켓컬리 ..
 [카테고리 태깅] GPT API를 이용한 리뷰 내용 카테고리 태깅
[카테고리 태깅] GPT API를 이용한 리뷰 내용 카테고리 태깅
앞서 키워드 추출을 통해 선정한 6가지 리뷰 내용 카테고리를 활용한다. 프롬프트 엔지니어링을 사용해 각 리뷰마다 내용에서 6가지 카테고리 중 해당되는 일부분이 있다면 이를 태깅하여 데이터셋으로 저장하는 과정을 진행한다. 1. GPT API few-shot prompting2. 카테고리 태깅 결과 📢 카테고리 태깅 과정, 감정분석, 요약 과정- Llama의 수행 시간 및 코랩 GPU 제한, GPT API 호출 비용으로 인해 150만개 리뷰 전체를 다 사용 불가 - 23년도 이후 & 4단어 이상 리뷰들만 선택 → ’도움돼요’ 개수가 많은 순, 최신순으로 정렬 후 각 상품마다 상위 50개의 리뷰만 사용 1. GPT API few-shot prompting✅ GPT API few-shot prom..