
working_helen
[리뷰 감정분석] ELECTRA / Korean Pre-trained Language Models 본문
[리뷰 감정분석] ELECTRA / Korean Pre-trained Language Models
HaeWon_Seo 2024. 9. 8. 21:33각 리뷰들에 대하여 긍정/부정/중립 감정을 라벨링하는 감정분석을 진행하고자 한다. 이때 감정분석 모델을 사용하는 과정에서 학습한 ELECTRA와 Korean Pre-trained Language Models에 대해 정리해본다.
1. ELECTRA
2. 논문 리뷰
3. KcBERT & KcELECTRA
4. KoBERT & KoELECTRA
1. ELECTRA
- Google에서 2020년 발표한 "ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators" 논문에서 제안된 모델
- Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- 작은 모델 크기와 적은 연산량으로도 BERT와 유사한 성능을 보일수 있도록 기여
1) ELECTRA 등장 배경
- BERT가 pre-training 과정에서 사용하는 task인 MLM은
입력 시퀀스에서 전체 토큰이 아닌 일부 토큰만 마스킹하여 학습에 사용
- 대량의 학습 데이터가 필요하기 때문에 훈련 과정 내 비효율성 문제가 존재
➡️ ELECTRA
= pre-training 과정에서 MLM이 아닌 RTD (Replaced Token Detection) task를
사용함으로써 입력 시퀀스의 모든 토큰을 학습에 사용
= 생성 모델이 아닌 분류 모델을 pre-training
==> 적은 계산량으로도 BERT와 유사한 성능을 보일 수 있음
기존의 BERT에서 학습의 효율성을 증진한 모델
리소스가 제한적이거나 크기가 작은 모델인 경우에도 효과적으로 학습 가능
2) ELECTRA의 구조

- 2가지 Transformer Encoder : Generator-Discriminator
- 결과적으로 Discriminator가 pre-trained encoder로 사용됨
Generator
- BERT와 유사하게 MLM task로 학습
- 입력 시퀀스에서 일부 토큰을 마스킹한 후 마스킹된 토큰의 원본을 예측
- 문맥 상 적절한 토큰을 예측하는 과정을 학습
Discriminator
- 마스킹 토큰에 대하여 Generator의 예측 토큰이 원래의 토큰인지 아닌지 판별하는 task로 학습
- 특정 위치 토큰이 문맥상 적절한지 아닌지 이진분류하는 과정을 학습
2. 논문 리뷰
논문명 : ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
저자명 : Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning
https://arxiv.org/abs/2003.10555
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, the
arxiv.org
✏️ 논문 내용 정리
- ELECTRA 고안 배경
: 현재 언어모델의 학습에 사용되는 MLM pre-training은 전체 입력 시퀀스의 일부만 학습 대상으로 사용하기 때문에 모델 성능을 위해 많은 양의 학습을 요구한다는 한계가 존재
- ELECTRA와 이전 모델의 차이점
" we propose pre-training task called replaced token detection "
" Instead of masking the input, our approach corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, we train a discriminative model that predicts whether each token in the corrupted input was replaced by a generator sample or not. "
: MLM 대신 RTD라는 새로운 pre-training task를 사용해 사전 학습
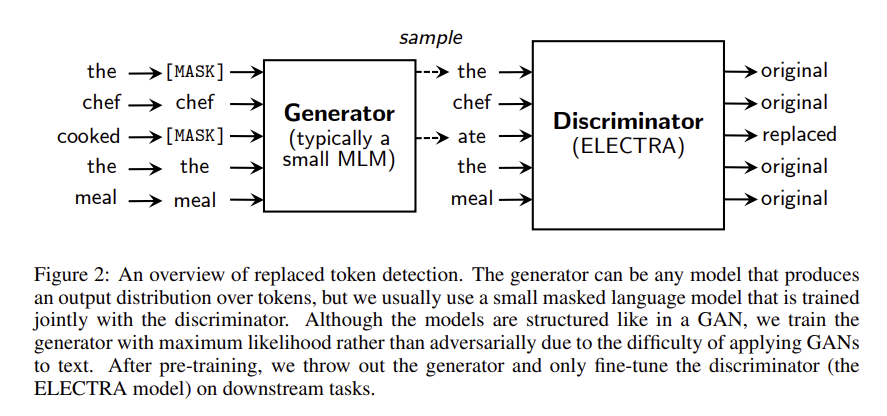
- ELECTRA 모델의 구조
= 2개의 Transformer Encoder neural network = generator G & discriminator D
① generator G
: 입력 시퀀즈에서 일부 토큰을 x_masked로 마스킹
→ 마스킹된 원래 토큰이 무엇인지 예측하는 과정을 학습, P_G(x_t|x_masked)를 학습
② discriminator D
: 마스킹된 토큰을 generator가 학습한 P_G(x_t|x_masked)로부터 샘플링한 토큰 x_corrupt로 치환
→ x_corrupt가 원본과 동일한지 혹은 바뀌었는지 예측하는 과정을 학습
- 논문에서 보인 모델의 특성
① 입력 시퀀즈의 모든 토큰에 대해서 학습하기 때문에 MLM에 비해 계산 효율성이 높음
② 동일한 학습 조건에서 MLM 기반 방법을 크게 능가하는 성능을 보임
▶ 0. Abstract
- BERT 등에 사용되는 MLM pre-training은 일부 토큰을 [MASK]로 대체하여 입력을 손상시킨 다음 원본 토큰을 재구성하기 위해 모델을 훈련하는 방식으로 좋은 성능을 위해선 많은 계산량이 필요
- 입력 시퀀즈의 일부 토큰을 generator network에서 샘플링된 그럴듯한 대체 토큰으로 손상시키고
손상된 각 토큰이 generator의 샘플로 대체되었는지 혹은 원본인지 여부를 예측하는 discriminator를 훈련
- 새로운 모델 ELECTRA는 MLM보다 더 효율적이며, 동일한 학습 조건에서 BERT보다 더 좋은 성능을 보임
▶ 1. Introduction
1) 기존 MLM pre-training 방식의 한계
- 현재 sota 모델은 MLM task를 이용해 pre-training
- 입력 시퀀스의 약 15% 토큰을 마스킹한 후 다시 이를 예측(복원)하는 task
- 양방향 정보를 고려하여 학습할 수 있다는 장점
- 하지만 입력 데이터의 15%만 학습에 사용하기 때문에 학습에 많은 비용이 소요되며
pre-training 과정에서 사용한 [MASK] 토큰이 fine-tuning 과정에는 사용되지 않는 불일치 문제가 존재
2) ELECTRA : Efficiently Learning an Encoder that Classifies Token Replacements Accurately
" we propose replaced token detection, a pre-training task in which the model learns to distinguish real input tokens from plausible but synthetically generated replacements "
- pre-training task로 Replaced Token Detection (RTD)를 제안
- 모델이 실제 입력 토큰과 가짜로 합성된 대체 토큰을 구별하는 task
- generator는 입력 시퀀스의 일부 토큰을 그럴듯한 가짜 토큰으로 대체
discriminator는 각 토큰이 원본 토큰인지 혹은 대체된 토큰인지 예측
- 입력 시퀀즈의 모든 토큰에 대해서 학습하기 때문에 MLM에 비해 계산 효율성을 높임
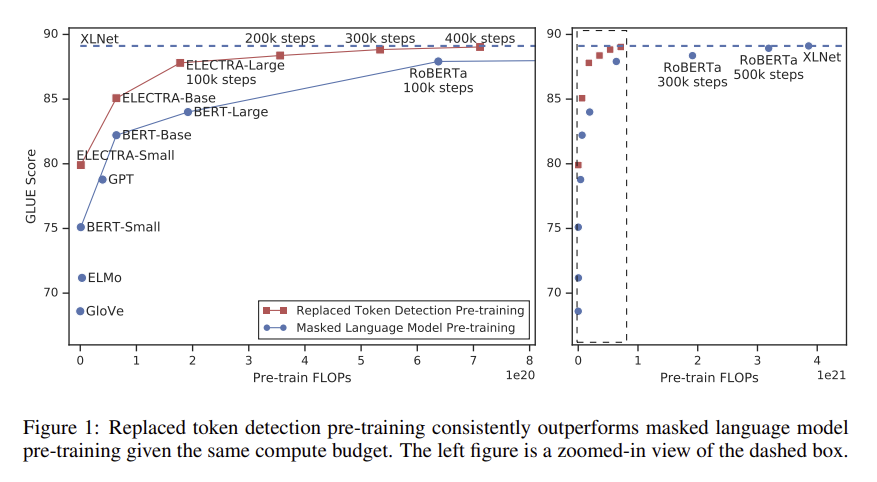
- 다양한 크기의 ElectRA 모델을 학습하고 downstream task에서 성능을 비교한 결과,
ElECTRA는 동일한 모델 크기, 데이터, 계산량에서 MLM 기반 방법을 크게 능가하는 성능을 보임
▶ 2. Method
- generator G & discriminator D
- 입력 시퀀스 x를 contextualized vector representations h(x)로 매핑하는 Transformer Encoder 구조의 neural network
1) Generator G
" the generator outputs a probability for generating a particular token x "
" the generator then learns to predict the original identities of the masked-out tokens "
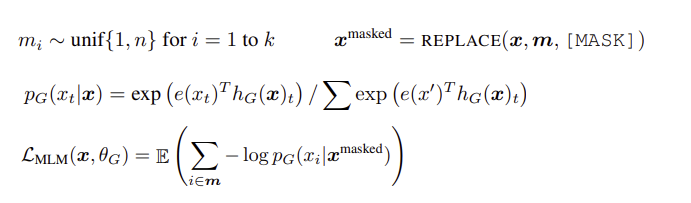
- e : token embeddings
- t : 시퀀즈에서 각 토큰의 position
- n : input x의 전체 토큰 수
- m : input x에서 마스킹할 위치의 집합
- k : 마스킹할 위치의 개수, k = [0.15*n] 전체 토큰의 약 15%를 마스킹
- x_masked : [MASK]로 마스킹된 토큰
- MLM (masked language modeling)으로 학습
- 입력 시퀀스 x에 대하여 마스킹할 위치 m=[m_1, m_2, ... , m_k]를 결정
→ 위치 집합 m에 해당하는 토큰들을 [MASK]로 대체
→ generator가 마스킹된 토큰의 원본이 무엇인지 예측하는 과정을 학습
softmax 확률분포 P_G(x_t|x_masked)를 학습
2) Discriminator D
" the discriminator is trained to distinguish tokens in the data from tokens that have been replaced by generator samples "
" the discriminator predicts whether the token x_t is real "
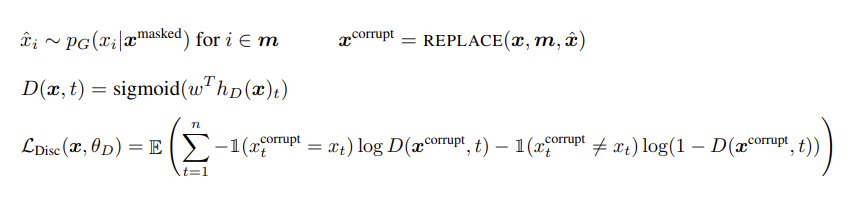
- x_hat, x_corrupt : generator G가 예측한 토큰
- generator G를 이용해서 마스킹된 입력 토큰들을 예측
= 위치 집합 m의 [MASK] 토큰을 generator의 P_G(x_t|x_masked)에서 샘플링한 토큰 x_corrupt로 치환
= x_corrupt는 원본과 같을수도, 다를수도 있음
→ discriminator가 x_corrupt에 대하여 원본과 동일한지 혹은 바뀌었는지 예측하는 과정을 학습
각 토큰에 대하여 'original'인지 'replaced'인지 이진 분류
※ generator G & discriminator D 학습 과정 예시
- Original input : [the, chef, cooked, the, meal]
- Input for generator : [[MASK], chef, [MASK], the, meal]
generator는 [MASK]된 토큰이 원래 무엇이었을지 확률분포 학습 - Input for discriminator : [the, chef, ate, the, meal]
첫 번째 [MASK] 토큰에 대해서는 generator가 원래 입력 토큰과 동일하게 “the”로 예측
두 번째 [MASK] 토큰에 대해서는 generator가 원래 입력 토큰과 다른 "ate"로 예측
discriminator는 "the"와 "ate"과 원래 토큰과 동일한지 대체되었는지 학습
3) training objective에서 GAN과의 차이점
- generator가 원래 토큰과 동일한 토큰을 생성했을 때, GAN에선 여전히 fake로 간주되지만 ELECTRA는 real로 간주한다는 점
- generator의 discriminator를 속이기 위해 학습되는 것이 아니라 예측의 maximum likelihood로 학습된다는 점
- GAN에서와 달리 generator의 입력으로 노이즈 벡터를 넣어주지 않는다는 점
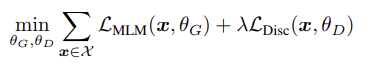
" minimize the combined loss over a large corpus 𝒳 of raw text "
- ELECTRA는 대용량 코퍼스 𝒳에 대해 generator loss와 discriminator loss의 합을 최소화하도록 학습
- discriminator loss가 generator로 역전파 되지 않음
- pre-training 후에는 discriminator만 사용해 downstream task으로 fine-tuning
- λ는 muliclass classification인 generator와 binary classification인 discriminator의 scale을 맞추기 위해 사용
▶ 5. Conclusion
- language representation을 학습하기 위한 새로운 task로 replaced token detection 제안
- RTD의 핵심은 discriminator가 입력 토큰과 generator로부터 생성된 high-quality negative samples와 구별하도록 학습시키는 것
- MLM 기반 모델에 비해 계산 효율성이 높고 downstream task에서 더 나은 성능을 제공
- 상대적으로 적은 계산량을 사용하는 경우에도 잘 작동
3. KcBERT & KcELECTRA
- KcBERT: Korean comments BERT / KcELECTRA: Korean comments ELECTRA
- 이준범님이 생성한 댓글 데이터 기반 한국어 BERT & ELECTRA language model
- 기존의 한국어 언어모델은 위키백과, 뉴스 기사, 책 등 정제된 텍스트 데이터를 기반으로 학습
- 구어체, 오탈자, 신조어 등이 많이 포함되는 특성을 가지는 텍스트 데이터에도 적합한 언어모델을 개발하기 위해 온라인 뉴스의 댓글 및 대댓글을 학습데이터로 사용하여 토크나이저, BERT, ELECTRA를 pretraining
- 두 모델의 vocab 크기는 모두 3000이며, 모델 파라미터 크기는 각각 109M과 124M
GitHub - Beomi/KcBERT: 🤗 Pretrained BERT model & WordPiece tokenizer trained on Korean Comments 한국어 댓글로 프리트
🤗 Pretrained BERT model & WordPiece tokenizer trained on Korean Comments 한국어 댓글로 프리트레이닝한 BERT 모델과 데이터셋 - Beomi/KcBERT
github.com
GitHub - Beomi/KcELECTRA: 🤗 Korean Comments ELECTRA: 한국어 댓글로 학습한 ELECTRA 모델
🤗 Korean Comments ELECTRA: 한국어 댓글로 학습한 ELECTRA 모델. Contribute to Beomi/KcELECTRA development by creating an account on GitHub.
github.com
4. KoBERT & KoELECTRA
- KoBERT : Korean BERT
- SKT Brain에서 개발한 한국어 BERT 모델
- 위키피디아와 뉴스 등에서 수집한 수백만 개 한국어 문장 Corpus를 학습
- vocab 크기 8002, 모델의 파라미터 크기 92M
GitHub - SKTBrain/KoBERT: Korean BERT pre-trained cased (KoBERT)
Korean BERT pre-trained cased (KoBERT). Contribute to SKTBrain/KoBERT development by creating an account on GitHub.
github.com
- KoELECTRA : Korean ELECTRA
- 박장원님이 개발한 한국어 ELECTRA 모델
- 초기 버전은 뉴스, 위키, 나무위키에서 수집한 14G Corpus로 학습
이후 신문, 문어, 구어, 메신저, 웹 등에서 수집한 20G Corpus를 추가적으로 사용하여 모델 업데이트
GitHub - monologg/KoELECTRA: Pretrained ELECTRA Model for Korean
Pretrained ELECTRA Model for Korean. Contribute to monologg/KoELECTRA development by creating an account on GitHub.
github.com
Reference
https://tech.scatterlab.co.kr/electra-review/
https://velog.io/@nellcome/ELECTRA-ALBERT#conclusion
https://littlefoxdiary.tistory.com/41
https://sktelecom.github.io/project/kobert/
https://www.letr.ai/ko/blog/tech-20221124
'deep daiv. > NLP project' 카테고리의 다른 글
| [모델링] LLM : OpenAI GPT & Meta Llama / LLM few-shot prompting (0) | 2024.09.15 |
|---|---|
| [리뷰 감정분석] KOTE 논문 리뷰 / KOTE fine-tuning 모델을 활용한 감정분석 (2) | 2024.09.12 |
| [데이터 전처리] 마켓컬리 리뷰 데이터 전처리 / kiwipiepy 형태소 분석기 (2) | 2024.09.05 |
| [프롬프트 엔지니어링] 프롬프트 엔지니어링 연습 with ChatGPT Prompt Engineering for Developers (2) | 2024.09.01 |
| [프롬프트 엔지니어링] 프롬프트 엔지니어링의 개념, 기법, 예시 (0) | 2024.08.30 |



