
working_helen
[데이터 전처리] 마켓컬리 리뷰 데이터 전처리 / kiwipiepy 형태소 분석기 본문
수집한 마켓컬리 리뷰 데이터에 대해 전처리를 진행한 과정을 정리해본다.
1. kiwipiepy 형태소 분석기
2. PyKoSpacing
3. 띄어쓰기 교정 과정
✅ 현재 dataframe
- '국 · 탕 · 찌개' 카테고리 내 상품 목록

- '국 · 탕 · 찌개' 카테고리 상품의 리뷰 목록
✅ 전체 전처리 과정
→ 결측치 제거 : review 열에 존재하는 5개의 결측치 제거
→ 중복값 제거 : 3181개의 중복되는 리뷰 제거 (동일인이 동일한 내용으로 이중 작성한 리뷰)
→ 한국어 리뷰만 사용 : 아예 영어로만 쓰여진 826개의 리뷰들을 제거
→ 정규 표현식으로 특수문자 + 이모티콘 제거
① r"[^가-힣A-Za-z0-9\w\s]" : 한국어, 영어, 숫자, 띄어쓰기, 줄바꿈을 제외한 모든 문자를 제거
② r"([ㄱ-ㅎㅏ-ㅣ])\1{1,}" : 'ㅋㅋ', 'ㅠㅠ'와 같이 하나의 모음 혹은 자음으로 이루어진 문자 제거
→ 'product_type' 통일 : 같은 상품이지만 상품명이 변하며 다르게 인식된 'product_type'을 통일
→ 띄어쓰기 교정 : kiwipiepy 형태소 분석기 이용
1. kiwipiepy 형태소 분석기
- Korean Intelligent Word Identifier 엔진을 사용하는 한국어 자연어 처리 파이썬 라이브러리
- 형태소 분석을 기반으로 품사 추출, 구문 분석, 사용자 정의 사전 지원 등의 task를 수행
- 한국어 특유의 복잡한 문법과 어휘를 처리하는 데 최적화
1) kiwipiepy의 장점
- Python으로 구현되고 C++로 작성된 성능 최적화 모듈을 사용
→ 적은 메모리를 사용하면서도 빠르게 대용량 텍스트 데이터를 처리할 수 있음
→ Mecab이나 Komoran과 같이 Java Runtime Environment (JRE) 또는 Java Development Kit (JDK)의 설치가 필요한 Java 기반 라이브러리와 달리, Java 의존성이 없는 kiwipiepy는 별도의 Java 시스템 설치 없이 Python에서 바로 실행할 수 있어 호환성 문제를 줄이고 더 자유롭게 배포할 수 있다는 장점이 있음
2) kiwipiepy의 띄어쓰기 교정 기능
- 0.11.1 (2022-04-03) 버전부터 띄어쓰기 교정을 수행하는 Kiwi.space() method가 추가됨
- 형태소 분석 결과에 기반하여 한국어 텍스트의 띄어쓰기를 자동으로 교정
!pip install kiwipiepy
from kiwipiepy import Kiwi
kiwi.space("이문장을 띄어 쓰기해주세요")
>>> "이 문장을 띄어 쓰기 해 주세요"
#`reset_whitespace=True`는 아예 기존 문장에 있던 공백들을 무시하고 띄어쓰기 교정
kiwi.space("이문장을 띄어 쓰기해주세요", reset_whitespace=True)
>>> "이 문장을 띄어쓰기해 주세요"
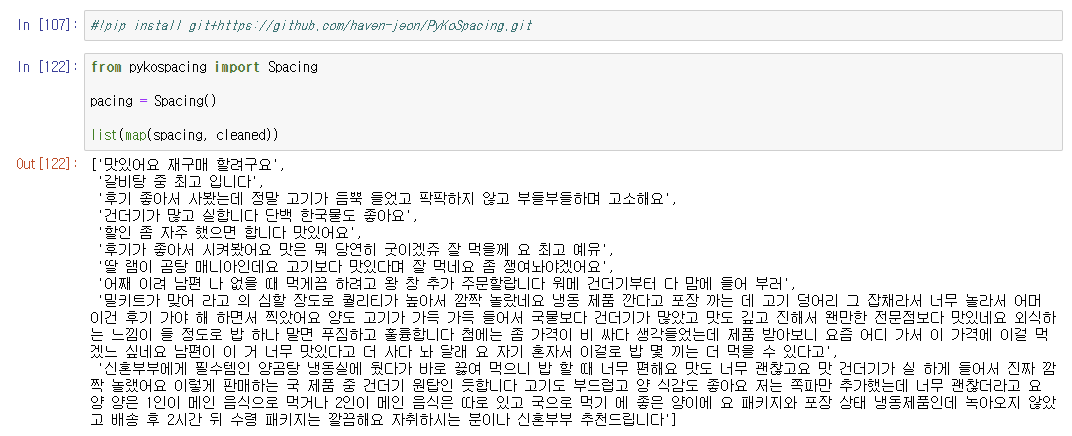
2. PyKoSpacing
- 전희원님이 개발한 오픈소스 한국어 전처리 패키지
깃헙에서 다운받은 후 파이썬 라이브러리로 import하여 사용 가능
- 형태소 분석기가 아닌, 방대한 한국어 말뭉치를 사용해 학습한 한국어 띄어쓰기 딥러닝 모델
- 띄어쓰기 교정 및 맞춤법 교정을 지원
!pip install git+https://github.com/haven-jeon/PyKoSpacing.git
from pykospacing import Spacing
spacing = Spacing()
spacing("이문장을 띄어 쓰기해주세요")
>>> "이 문장을 띄어 쓰기해주세요"
3. 띄어쓰기 교정 과정
- 앞선 전처리 과정을 모두 거친 텍스트 예시

- 4가지 방법 시도
- kiwipiepy 형태소 분석기
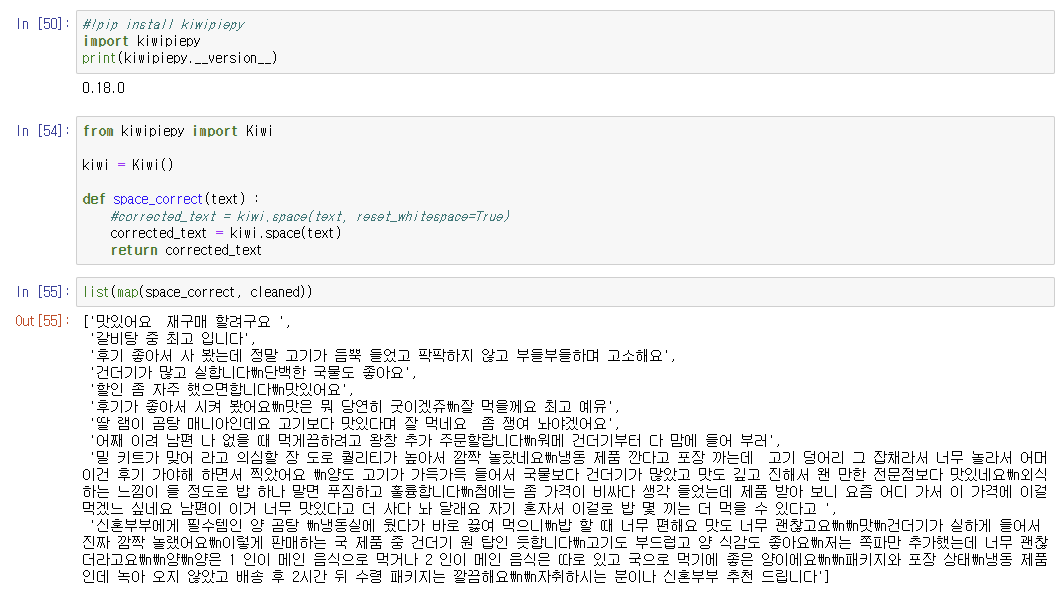
- PyKoSpacing
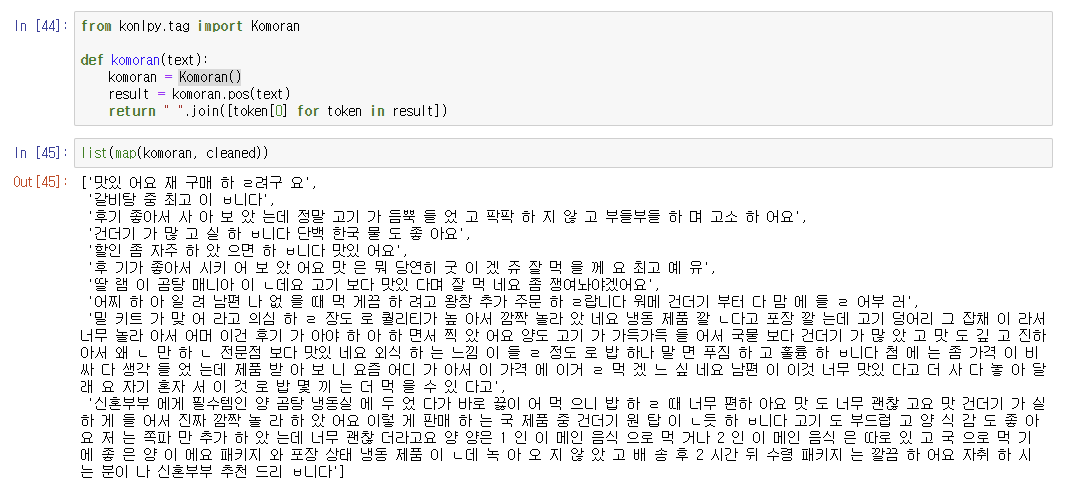
- KoNLPy 형태소 분석기
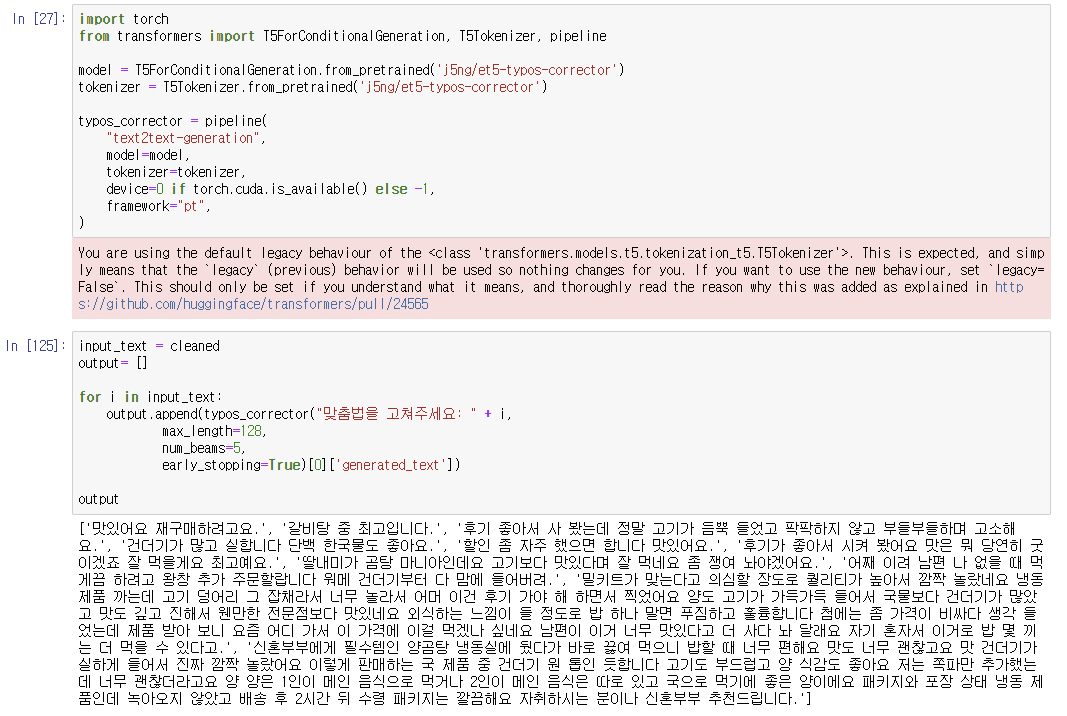
- 오픈소스 ETRI-et5 모델 (출처)
➡️ 최종 선택 = kiwipiepy를 사용한 띄어쓰기 교정
- 현재 약 150만개에 달하는 텍스트 데이터 → 처리 속도가 빠른 kiwipiepy의 장점 이용
- 향후 이 리뷰 요약 서비스가 '국 · 탕 · 찌개' 카테고리 외 다른 카테고리로도 확장될 가능성이 존재
→ 다른 형태소 분석기들에 비해 사용 환경 조건에서 제약이 적어 배포에 유용한 kiwipiepy의 장점 이용
- kiwipiepy가 내재적으로 제공해주는 띄어쓰기 mothod를 사용 가능
- 실제로 몇가지 리뷰 문장 예시에 적용해 본 결과 다른 방법에 비해 성능이 좋았고,
네이버 맞춤형 교정기를 사용했을때의 결과와도 가장 근접한 성능을 보임
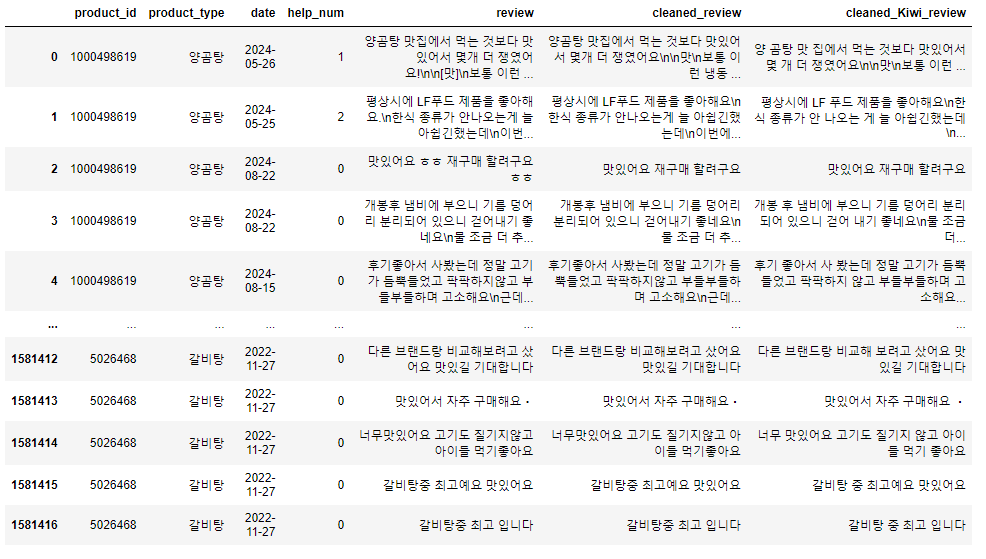
✅ 전처리 후 dataframe
'국 · 탕 · 찌개' 카테고리 내 267개 상품의 리뷰 약 150만개
- product_id : 컬리 내 상품의 id
- product_type : 상품 옵션
- date : 리뷰 작성 날짜
- help_num : 리뷰 '도움돼요' 개수
- review : 리뷰 원문
- cleaned_review : kiwipiepy 적용 전까지 전처리 결과
- cleaned_Kiwi_review : kiwipiepy 적용 후 최종 전처리 결과
Reference
https://wikidocs.net/233361
https://bab2min.github.io/kiwipiepy/v0.18.0/kr/#kiwipiepy.Kiwi.space
https://wikidocs.net/92961
https://haru0229.tistory.com/57
https://velog.io/@acdongpgm/NLP-%ED%95%9C%EA%B5%AD%EC%96%B4-%EA%B5%AC%EC%96%B4%EC%B2%B4%EB%8C%80%ED%99%94%EC%B2%B4-%EB%A7%9E%EC%B6%A4%EB%B2%95-%EA%B5%90%EC%A0%95%EA%B8%B0Korean-typos-corrector-ET5-Text2Text-Generation#%ED%95%9C%EA%B5%AD%EC%96%B4-%EB%A7%9E%EC%B6%A4%EB%B2%95-%EA%B5%90%EC%A0%95%EA%B8%B0
'deep daiv. > NLP project' 카테고리의 다른 글
| [리뷰 감정분석] KOTE 논문 리뷰 / KOTE fine-tuning 모델을 활용한 감정분석 (2) | 2024.09.12 |
|---|---|
| [리뷰 감정분석] ELECTRA / Korean Pre-trained Language Models (6) | 2024.09.08 |
| [프롬프트 엔지니어링] 프롬프트 엔지니어링 연습 with ChatGPT Prompt Engineering for Developers (2) | 2024.09.01 |
| [프롬프트 엔지니어링] 프롬프트 엔지니어링의 개념, 기법, 예시 (0) | 2024.08.30 |
| [데이터 수집] 마켓컬리 리뷰 데이터 크롤링 (1) | 2024.08.29 |



