
working_helen
[모델링] LLM : OpenAI GPT & Meta Llama / LLM few-shot prompting 본문
[모델링] LLM : OpenAI GPT & Meta Llama / LLM few-shot prompting
HaeWon_Seo 2024. 9. 15. 15:53LLM의 등장배경을 살펴보고 본 프로젝트에서 활용한 Meta Llama와 OpenAI GPT에 대해 알아본다.
1. LLM 등장 배경
2. OpenAI GPT vs Meta Llama
3. few-shot prompt engineering
4. GPT API prompt engineering
5. Llama prompt engineering
1. LLM 발전 과정

(1) LLM 이전의 언어모델
Statistical language models (SLM)
- 통계적 학습 방법 기반
- n-gram 모델, Hidden Markov Model (HMM)
Neural language models (NLM)
- RNN, LSTM, Seq2Seq, Transformer
- 특정 데이터로 훈련된 후 일정한 하나의 task에서만 사용
Pre-trained language models (PLM)
- ELMO, BERT, ELECTRA, GPT-1/2
- GPT-1 : 2018년 OpenAI에서 발표한 PLM, Transformer decorder만으로 구성
BERT : 2019년 구글에서 발표한 PLM, Transformer encorder만으로 구성 - 대규모 데이터 기반 pre-training → downstream task로 fine-tuning
pre-training 단계에서 일반적인 언어 구조를 학습한 후, 다양한 task에서 범용적으로 사용
pre-trained 모델을 각각의 task에 사용되는 데이터를 기반으로 fine-tuning 해야함
[NLP 학습] 2주차 : BERT / 논문 리뷰 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
이전 포스트에서 다룬 Transformer의 개념을 바탕으로 BERT에 대해 학습해본다. BERT와 관련된 논문 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"를 리뷰한다. 1. BERT 2. 논문 리뷰
working-helen.tistory.com
[NLP 학습] 2주차 : GPT-1 / 논문 리뷰 : Improving Language Understanding by Generative Pre-Training
이전 포스트에서 다룬 Transformer의 개념을 바탕으로 GPT-1에 대해 학습해본다. GPT-1과 관련된 논문 "Improving Language Understanding by Generative Pre-Training"를 리뷰한다. 1. GPT-1 2. 논문 리뷰 1. GPT-1 - Ope
working-helen.tistory.com
(2) Large language models (LLM)
- 많은 연구에서 훨씬 더 큰 PLM을 pre-traing했을 때 downstream task에서 모델 성능이 향상됨을 발견
- OpenAI에서 2020년 발표한 "Scaling Laws for Language Models"은 언어모델 학습 시 연산량, 데이터셋 규모, 파라미터를 늘리면 test loss가 계속해서 감소함을 실험적으로 보임
➡️ 대규모 텍스트 데이터로 훈련된, 수천억 개 이상의 매개변수를 포함하는, Transformer 언어 모델
- 데이터의 규모, 모델의 크기(파라미터의 수)에서 PLM을 확장
- PLM의 사전학습 모델 규모가 증가하며 대형 PLM으로 불리다가 LLM으로 명명됨
LLM과 이전 언어모델의 주요 차이점
- 모델 크기 증가
- 수십억~수천억 개 이상의 파라미터
- GPT-2의 파라미터 수는 15억 개, GPT-3의 파라미터 는 1750억 개 - 대규모 학습 데이터
- 특정 task에 대한 데이터가 아닌 다양한 도메인의 초대형 데이터셋
- GPT-3는 인터넷 크롤링 데이터 4100억 개, WebText2 데이터 190억 개, Books 데이터 670억 개, Wikipedia 30억 개의 토큰으로 학습됨 - in-context learning / zero-shot learning
- LLM은 대규모 데이터 pre-training을 통해 문맥 구조 자체를 학습
- 별도의 fine-tuning 없이 pre-traing 모델의 파라미터를 그대로 사용하면서 입력된 텍스트의 맥락만을 사용해 새로운 task를 해결
- few-shot, zero-shot learning으로 다양한 task에 바로 적용 가능 - 긴 문맥 처리 / 복잡한 텍스트 생성
- 대규모 학습 데이터와 파라미터를 사용함으로써 복잡한 문맥 및 의미관계도 학습 가능해짐
LLM 모델 종류
- OpenAI에서 2020년 GPT-3를 공개하며 LLM이 큰 주목을 받기 시작
- GPT-3 이후 LLM 개발 타임라인
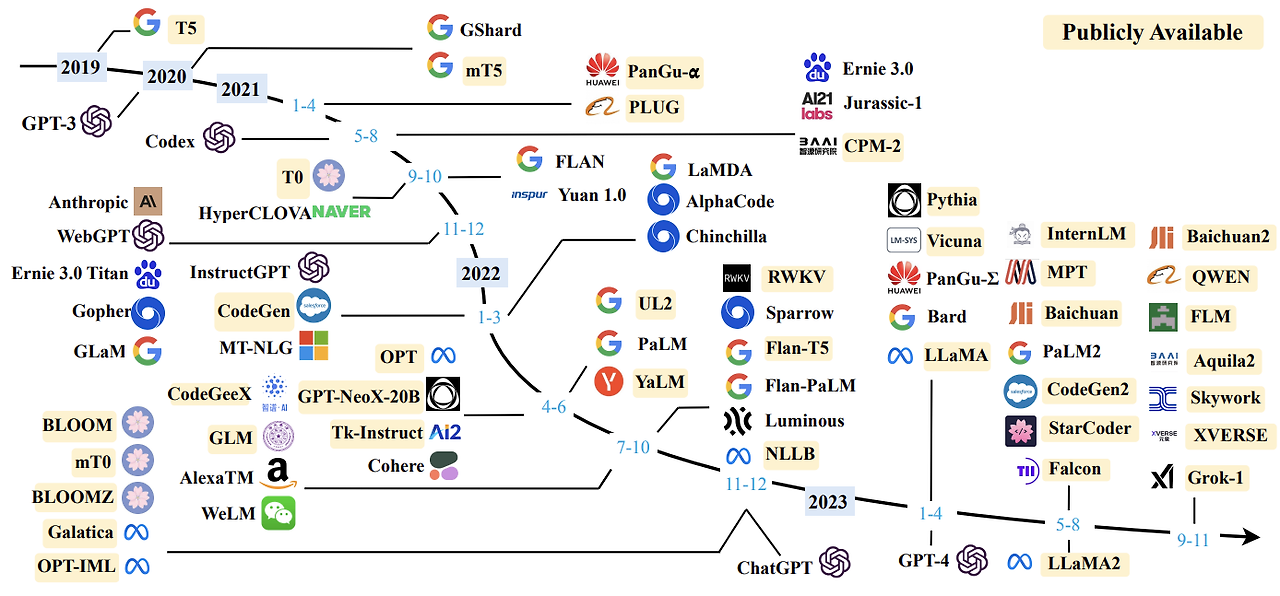
(3) 오픈소스 LLM
- LLM은 데이터 및 모델 규모로 인해 학습 비용이 매우 높음 → 작은 연구실이나 개인 개발자가 자체적으로 LLM 학습이 어렵고, 대형 기업들만 LLM 개발을 독점하는 문제 발생
- LLM 연구 지원하고 개발자 간 협업적인 연구 생태계를 위해 대형 기업에서 오픈소스 LLM을 제공하기 시작
- 기존 LLM보다 크기는 작지만 성능은 비슷한 일명 sLLM(소규모 대규모 언어 모델)
- Meta에서 2023년 2월 LlaMa를 오픈소스로 공개하며 sLLM 모델이 많이 공개되기 시작함
2. OpenAI GPT vs Meta Llama
| OpenAI GPT | Meta Llama | |
| 파라미터 개수 | GPT-3 : 175B GPT-4 : 1조 개 이상으로 추정 |
Llama1 : 7B, 13B, 30B, 65B Llama2 : 7B, 13B, 70B Llama 3 : 8B, 70B (400B 학습 중) |
| 학습 데이터 | 다양한 출처와 형식의 데이터 사용, 이때 웹 페이지나 SNS 등 인터넷 데이터를 많이 사용 | 다양한 출처와 형식의 데이터 사용, 과학 기사 혹은 뉴스 기사 등 고품질 텍스트 데이터를 선별하여 모델 학습 |
| 장점 | - 엄청난 크기의 모델 파라미터를 기반으로 압도적인 성능을 보임 - 다양한 자연어 task에서 범용적으로 사용 가능 |
- 더 적은 자원으로도 GPT-3와 유사한 수준의 높은 성능 보임, 효율성이 강조된 모델 - 오픈소스를 이용해 누구나 사용 가능 - 모델 설계 및 구조가 공개되어 있어 연구용으로 발전시키거나 실험하기 적합함 |
| 단점 | - 사용을 위해 많은 자원이 필요 - 좋은 모델은 비용을 지불해야 사용 가능 - 모델 구조가 비공개되어 있어 연구용으로 사용하히 어려움 |
- GPT에 비해 적은 수이 파라미터 사용하기 때문에 성능이 더 낮음 |
| 활용 분야 | 실제 산업에서 자연어 분야와 관련된 서비스에 응용되어 사용 | 주로 연구 및 학술적 용도로 사용 |
👍🏻 GPT를 사용하기 더 적합한 경우
- 다양한 자연어 처리 작업에 응용하면서, 상용화 및 서비스 쪽으로 활용하기를 원할 때
- 비용을 지불하더라도 높은 성능의 결과물을 원할 때
👍🏻 Llama를 사용하기 더 적합한 경우
- 비용 부담 없이 LLM을 다양하게 실험해보고 싶을 때
- 사전학습된 LLM을 자신의 목적에 맞게 fine-tuning시켜 새로운 모델로 발전시키거나 개발하고 싶을 때
3. few-shot prompting
1) LLM prompt engineering
- LLM은 대규모 데이터 pre-training을 통해 문맥 구조 자체를 학습
- 별도의 fine-tuning 없이 pre-trained모델의 파라미터를 그대로 사용하면서 입력된 텍스트의 맥락만을 사용해 새로운 task도 효과적으로 해결
- Tranformer 아키텍처를 사용하기 때문에 긴 문맥 및 단어 간 관계를 잘 이해
➡️ LLM은 입력 텍스트 = prompt를 최적화하는 방식만으로도 다양한 task를 처리
LLM은 Prompt Engineering을 효과적으로 적용 가능
2) few-shot prompting
- LLM이 새로운 task를 올바르게 수행할 수 있도록 promt에 성공적으로 수행된 예제들을 함께 제시하는 프롬프트 엔지니어링 기법
- LLM은 promt 내 예제들을 기반으로 학습하여 새로운 입력값에 대해 더 정확하게 처리
- 소수의 예제를 활용해 전체 task의 문제로 일반화하여 문제 해결
- 사전에 라벨링된 데이터 세트가 없거나 적은 경우에도 사용 가능
적은 수의 라벨링 데이터를 가지고도 task 성능을 높일 수 있음 - prompt의 예제로 LLM의 출력 형식을 사전 정의함으로써 출력의 일관성을 보장 가능
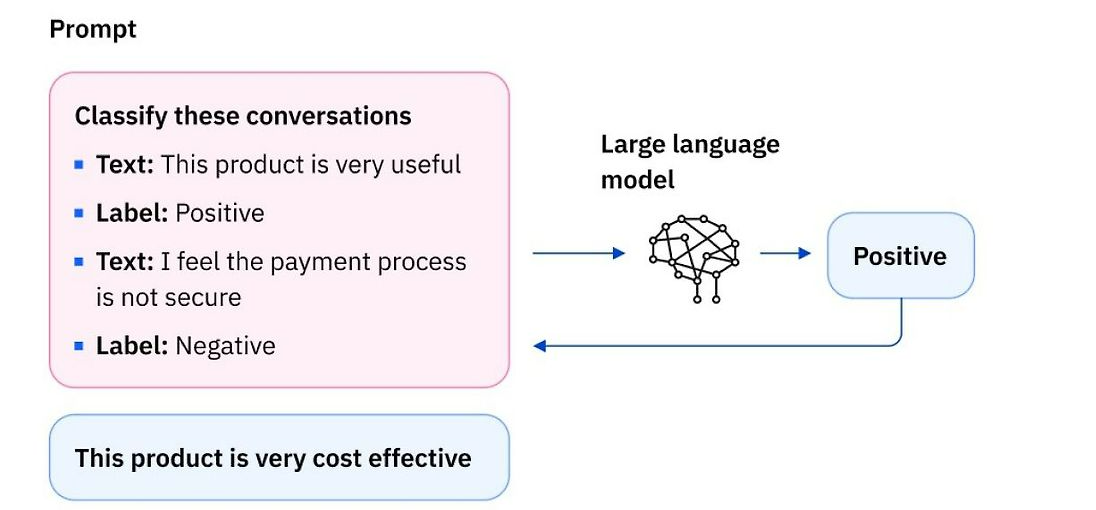
4. GPT API prompt engineering
- 본 프로젝트에서는 gpt-4o-mini의 API를 파이썬으로 호출해 사용
- GPT 모델 중 가장 최신 버전인 GPT 4o의 경량화 버전
GPT 4o보다 성능은 낮지만 비용이 저렴하고 빠르다는 장점
- https://platform.openai.com/docs/models#gpt-4o-mini
- GPT prompt engineering 관련 이전 포스트
[프롬프트 엔지니어링] 프롬프트 엔지니어링 연습 with ChatGPT Prompt Engineering for Developers
DeepLearning.AI(Beta)에서 무료로 공개하고 있는 "ChatGPT Prompt Engineering for Developers" 강의를 수강하며 프롬프트 엔지니어링에 대해 학습한 과정을 정리한다. 1. GPT API Request / Response 형식 2. 파이썬에
working-helen.tistory.com
5. Llama prompt engineering
- 본 프로젝트에서는 hugging face에서 Meta-Llama-3.1 모델을 불러와 사용
- https://huggingface.co/meta-llama/Llama-3.1-8B
meta-llama/Llama-3.1-8B · Hugging Face
The information you provide will be collected, stored, processed and shared in accordance with the Meta Privacy Policy. LLAMA 3.1 COMMUNITY LICENSE AGREEMENT Llama 3.1 Version Release Date: July 23, 2024 "Agreement" means the terms and conditions for use,
huggingface.co
1) Llama 모델 로드하기
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from huggingface_hub import login
login(token="hugging face token")
device = "cuda" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16
- login : 발급받은 hugging face token을 이용해 로그인
- device : GPU에서 모델 실행 속도가 더 빠르기 때문에 사용할 수 있다면 GPU를 우선적으로 선택
- torch_dtype : 모델이 사용할 tensor의 데이터 타입을 float16으로 설정
def load_model(base_model, torch_dtype=torch.bfloat16, use_quantization=False, quantization_config=None):
# 양자화를 적용하는 경우
if use_quantization:
if quantization_config is None:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
else:
bnb_config = None
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
torch_dtype=torch_dtype,
device_map="auto",
attn_implementation="eager"
)
# 양자화를 적용하지 않는 경우
if not use_quantization:
model.to(device)
return model
model_name = "meta-llama/Meta-Llama-3.1-8B-Instruct"
model = load_model(model_name, use_quantization=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)
- use_quantization : 모델을 로드하는 과정에서 양자화를 적용할지 설정
- load_in_4bit = True: 모델을 4비트 양자화로 로드
- tokenizer : 텍스트 입력을 로드한 모델이 사용할 수 있는 형태로 변환하는 토크나이저도 로드
2) Llama prompt 설계
Llama의 special tokens
- <|begin_of_text|> : 문장의 시작, [BOS] (Beginning Of Sentence token) 역할
- <|start_header_id|>{role}<|end_header_id|> : 메시지에 대한 역할 = system/user/assistant
- <|eot_id|> : 현재 role에 해당하는 메시지의 끝
- <|end_of_text|>: 문장의 끝, [EOS] (End Of Sentence token) 역할
https://www.llama.com/docs/model-cards-and-prompt-formats/meta-llama-3/
Llama 3 | Model Cards and Prompt formats
Special Tokens used with Llama 3. A prompt should contain a single system message, can contain multiple alternating user and assistant messages, and always ends with the last user message followed by the assistant header.
www.llama.com
inputs = f'''
<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n{prompt}<|eot_id|>
<|start_header_id|>user<|end_header_id|>\n{query}<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>'''
outputs = model.generate(**tokenizer(inputs, return_tensors="pt").to(device), pad_token_id=tokenizer.eos_token_id)
- system role의 메시지로 지시사항에 해당하는 prompt 입력
- user role의 메시지로 질문에 해당하는 query 입력
- assistant role을 마지막에 제시해 LLM이 응답할 차례임을 명시
- 각 메시지의 끝에 <|eot_id|> 삽입
- tokenizer가 텍스트 inputs을 모델에 적합한 tensor 형태의 토큰으로 변환하여 device로 전달
- model.generate를 통해 모델의 응답 텍스트를 생성
- 패딩 토큰(pad_token_id)을 eos_token_id(<|end_of_text|>)로 설정
➡️ 프로젝트에서 LLM 활용
- 1차적으로 비용없이 실험 가능한 Llama를 사용해 최적의 prompt 실험 및 모델 성능 확인
→ Llama에서 성능이 너무 좋지 않았던 task에 대해선 GPT 모델로 대체
- 카테고리 태깅의 경우 자체적으로 labeled train data를 생성한 후 Llama fine-tuning까지 시도했으나 모델 성능이 좋아지지 않음을 확인한 후 GPT로 대체
| Llama (Meta-Llama-3.1) | GPT (gpt-4o-mini) |
| - 키워드 추출 - 감정분석 - 긍부정 요약 / 카테고리별 요약 |
- 카테고리 태깅 fine-tuning - '활용방법' 요약 (Llama에서 먼저 시도했으나 성능이 좋지 않아 GPT로 대체) |
Reference
https://wikidocs.net/237619
https://skyil.tistory.com/299
https://textcortex.com/ko/post/llama-3-vs-gpt-4
https://ko.upstage.ai/blog/insight/open-source-large-language-models-korean-llm
https://devloo.tistory.com/entry/%EC%B1%97-GPTchatgpt-Meta-LLaMA-vs-ChatGPT-%EC%99%84%EB%B2%BD-%EB%B9%84%EA%B5%90-%EB%B6%84%EC%84%9D
'deep daiv. > NLP project' 카테고리의 다른 글
| [카테고리 태깅] GPT API를 이용한 리뷰 내용 카테고리 태깅 (0) | 2024.11.15 |
|---|---|
| [키워드 추출] Llama를 이용한 리뷰 키워드 추출 및 카테고리 선정 (0) | 2024.09.15 |
| [리뷰 감정분석] KOTE 논문 리뷰 / KOTE fine-tuning 모델을 활용한 감정분석 (2) | 2024.09.12 |
| [리뷰 감정분석] ELECTRA / Korean Pre-trained Language Models (6) | 2024.09.08 |
| [데이터 전처리] 마켓컬리 리뷰 데이터 전처리 / kiwipiepy 형태소 분석기 (2) | 2024.09.05 |


