
working_helen
[NLP 학습] 3주차 : prompt engineering, CoT / 논문 리뷰 : Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 본문
[NLP 학습] 3주차 : prompt engineering, CoT / 논문 리뷰 : Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
HaeWon_Seo 2024. 8. 18. 17:28이전 포스트에서 다룬 언어모델에 대한 이해를 바탕으로 프롬프트 엔지니어링에 대해 학습해본다. Chain-of-Thought prompting과 관련된 논문 "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"를 리뷰한다.
1. prompt engineering
2. Chain-of-Thought prompting
3. 논문 리뷰
1. prompt engineering
1) prompt 프롬프트
: 특정 작업을 수행하도록 AI에 요청하는 자연어 텍스트
언어모델에서 특정한 출력을 생성하기 위해 사용자가 입력하는 텍스트
2) prompt engineering 프롬프트 엔지니어링
: AI가 원하는 결과를 생성하도록 지시하는 최적의 프롬프트를 설계하는 과정
LLM에서 원하는 결과를 얻기 위해 프롬프트를 최적화하는 과정
3) 프롬프트 엔지니어링의 등장 배경
- GPT와 같은 LLM(대규모 언어모델)은 다양한 자연어 task에 활용
- 이때 모델이 특정한 task에서 더 좋은 성능을 보이기 위해선 모델로부터 원하는 출력 결과를 얻을 수 있도록 올바른 입력값을 사용하는 것이 중요해짐
- 이러한 최적의 입력값을 설계하고 찾는 것이 프롬프트 엔지니어링의 역할
==> 각각의 specific task에서 LLM의 성능을 최적화하기 위해 등장
2. Chain-of-Thought prompting
- Google에서 2022년 발표한 "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" 논문에서 제안된 구조
- 인간과 유사한 추론 과정을 언어모델이 사용할 수 있도록 학습시킴으로써 복잡한 추론 문제에 대한 모델 성능을 향상키는데 기여함
chain of thought(CoT)
= 문제 해결을 위해 거치는 여러 중간 단계의 논리적 사고 과정
= 최종 output으로 이어지는 중간 자연어 추론 과정
➡️ CoT를 포함하는 프롬프트로 LLM을 학습시킴
→ 모델은 CoT와 유사한 논리적 사고 과정을 따라 답을 출력하도록 유도됨
= 대규모 모델이 chain of thought를 사용하여 추론하도록 prompting
= 대규모 언어모델의 reasoning 능력을 상당히 향상
3. 논문 리뷰
논문명 : Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
저자명 : Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
https://arxiv.org/abs/2201.11903
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we show how such reasoning abilities emerge naturally in su
arxiv.org
✏️ 논문 내용 정리
- CoT prompting 고안 배경
: arithmetic, commonsense, symbolic reasoning과 같은 complex reasoning task에선 단순히 모델 크기를 확장하는 것만으로는 성능을 높이기 어려움. 대규모 언어 모델의 추론 능력 항샹을 위한 새로운 방법이 필요
- CoT prompting과 이전 모델의 차이점
: " in-context few-shot prompting with CoT "
CoT가 포함된 프롬프트 예제를 이용해 학습시키는 간단한 방법을 사용해 자연어 논리 전개 과정을 통해 추론하는 언어모델 생성, chain of thought(CoT)는 output으로 이어지는 일련의 중간 자연어 추론 단계
- CoT prompting 의 구조
: ⟨input, chain of thought, output⟩ 3가지로 구성된 프롬프트 예제 준비
→ 이미 개발된 언어 모델에 fine-tuning 없이 프롬프트만 사용하여 in-context few-shot learning
- 논문에서 보인 모델 특성
① 산술 추론, 상식 추론, 기호 추론 모두에서 standard prompting보다 좋은 성능을 보임
② 모델 크기가 커질수록 성능을 극적으로 향상됨 = 대규모 언어모델의 추론 능력을 향상시킴
③ 반면 크기가 작은 모델에서는 성능 향상이 미미하거나 저하됨
▶ 0. Abstract
- complex reasoning task에서 chain of thought가 언어모델의 성능을 상당히 향상시킬 수 있음을 보임
- chain-of-thought 예제를 prompting하는 간단한 방법을 통해 대규모 언어모델에서 상당한 reasoning 능력을 이끌어낼 수 있음
- arithmetic, commonsense, symbolic reasoning tasks에서 3가지 대규모 언어모델이 성능 향상을 보임
▶ 1. Introduction
1) 기존 NLP에서 모델 크기 확장의 한계
- 기존의 NLP에선 언어 모델의 크기를 확장시킴으로써 성능을 높이고자 함
- 하지만 산술(arithmetic), 상식(commonsense), 기호추론(symbolic reasoning)과 같은 task에선
단순히 모델 크기를 확장하는 것만으로는 높은 성능을 달성하기 어려움
2) 언어 모델의 추론 능력 항샹을 위한 이전의 연구들
① rationale-augmented training and finetuning method
- generating natural language rationales → arithmetic reasoning
- 자연어 논리를 바탕으로 산술 문제를 해결하도록 만드는 방식
모델이 합리적 자연어 논리 전개 과정에서 산술 문제를 해결
- 단점 : 고품질의 대규모 rationales 데이터를 생성하기 위한 많은 비용 소요
② traditional few-shot prompting method
- in-context few-shot learning via prompting
- 프롬프트 조작을 통한 in-context learning
task 입출력 예시를 이용해 모델을 "프롬프트"하는 방식
- 단점 : 추론 능력이 필요한 작업에선 부적합, 언어 모델 규모를 키워도 성능이 크게 향상되지 않음
3) chain-of-thought prompting
- prompting을 통한 in-context learning을 사용하면서 자연어 논리 전개 과정을 통해 답을 내는 언어모델
- ⟨input, chain of thought, output⟩ 3가지로 구성된 프롬프트가 주어지면
few-shot prompting을 통해 추론 작업을 수행하는 언어 모델
- "chain of thought (CoT)" = 최종 output으로 이어지는 일련의 중간 자연어 추론 단계
= series of intermediate natural language reasoning steps that lead to the final output
= series of intermediate reasoning steps that lead to the final answer for a problem
- 산술, 상식, 기호추론 task에서 기존의 prompting보다 좋은 성능을 보임
- 단일 모델이 일반성을 잃지 않고 많은 task에서 사용될 수 있기 때문에
대규모 훈련 데이터셋이 필요하지 않고, 일부 자연어 예시 데이터만 가지고도 학습 가능
* in-context learning
: 프롬프트만으로 task를 수행하는 학습 방식, pretraining이나 fine-tuning과 같은 별도의 추가 훈련 없이 주어진 프롬프트 내용(context) 안에서만 학습하는 방식이다.
* few-shot learning
: 모델에게 여러 개의 예시(shot)을 제공하여 학습시키는 in-context learning의 한 종류, 이 외에도 in-context learning은 주어지는 예시(shot)의 수에 따라 예시 없이 사전 지식으로만 학습하는 Zero-shot, 하나의 예시만 사용하는 One-shot가 있다.
(참고 링크) https://velog.io/@dongyoungkim/GPT-fine-tuning-5.-in-context-learning#few-shot-learning
▶ 2. Chain-of-Thought Prompting
1) 논문의 목표
- chain-of-thought를 생성하는 능력을 갖는 대규모 언어모델 생성
- chain of thought 과정이 포함된 few-shot prompt가 주어진다면
= chain of thought 예시들로 few-shot prompting한다면
규모가 큰 언어모델이 chain of thought를 생성할 능력을 갖출 수 있음을 보임
➡️ 대규모 언어모델이 chain of thought를 사용하여 추론하도록 만듬으로써 reasoning 능력을 상당히 향상시킴
= reasoning task에서 모델 크기를 확장함으로써 추론 능력을 향상시키는 것을 가능하게 함
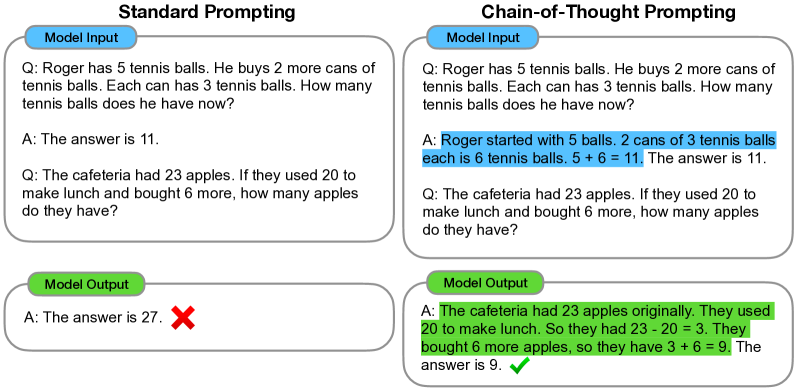
2) Chain-of-thought prompting의 특징
- 문제를 intermediate steps으로 분해하여 더 많은 추론이 필요한 단계에 추가적인 계산을 할당
- chain of thought는 모델의 출력 결과에 대해 해석가능성을 부여
- chain of thought는 인간이 언어로 해결하는 모든 작업에 잠재적으로 적용 가능
- chain of thought의 몇가지 예시로 few-shot prompting하면 대규모 모델도 chain of thought reasoning이 가능
3) Chain-of-thought prompting을 적용할 task
- 산술 추론(arithmetic reasoning)
- 상식 추론(commonsense reasoning)
- 기호적 추론(symbolic reasoning)

▶ 3. Arithmetic Reasoning
- 산술 추론 문제에서 CoT prompting 사용한 언어 모델의 성능 평가
- math word problems 이용
▶ 3.1 Experimental Setup
- 5가지 math word problem benchmarks : GSM8K, SVAMP, ASDiv, AQuA, MAWPS
- 5가지 language models : InstructGPT(350M, 1.3B, 6.7B, 175B parameters), LaMDA(422M, 2B, 8B, 68B, 137B parameters), PaLM(8B, 62B, 540B parameters), UL2(20B parameters), Codex
- baseline : 질문/답변 형태로 된 in-context 예제들로부터 예측을 출력하는 standard few-shot prompting
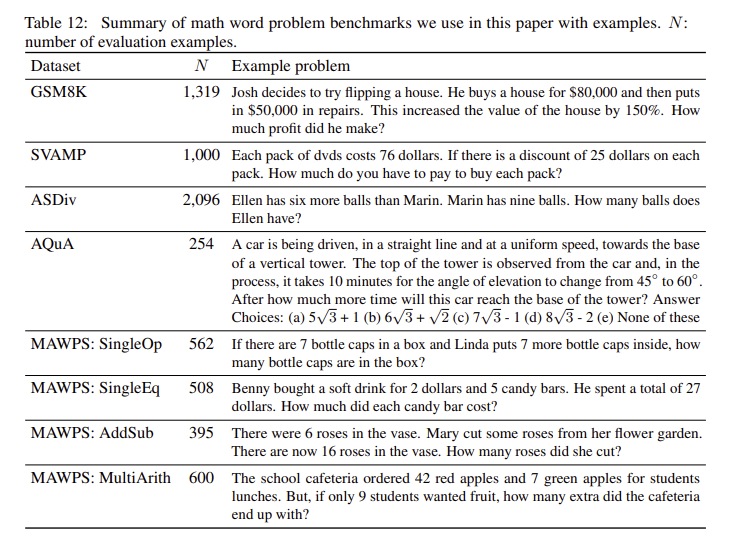
- 새로운 모델의 목표는 few-shot prompt의 예시를 CoT를 사용하여 보충하는 것
- 8가지 few-shot exemplars with chains of thought를 직접 제작하여
AQuA를 제외한 모든 자유응답 형식의 benchmarks에서 이 예제들을 1번씩 사용
- 다중 객관식 선택 형식에 해당하는 AQuA의 경우 별도의 4가지 예제 사용
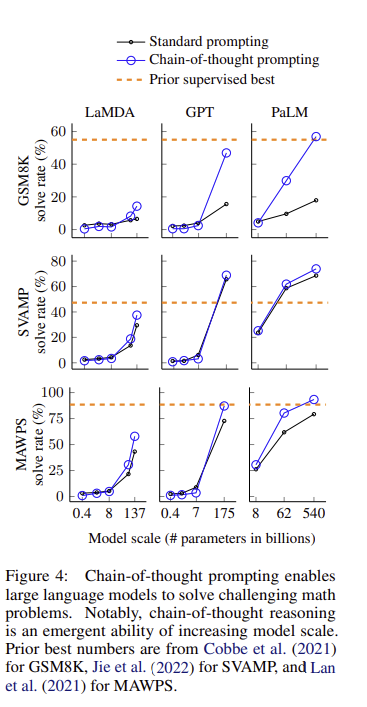
▶ 3.2 Results
- chain-of-thought prompting은 모델의 크기가 커질수록 성능 향상에 기여함, 크기가 작은 모델에선 오히려 standard prompting보다도 낮은 성능을 보이는 경우도 존재
- chain-of-thought prompting은 복잡한 문제일수록 성능 향상에 크게 기여함, 쉬운 문제인 경우 성능 향상이 미미하거나 오히려 안좋아짐
- GPT-3 175B와 PaLM 540B 모델에서는 CoT를 사용했을때 새로운 sota 달성
- 모델이 생성한 chains of thought를 분석
- 모델이 정답을 맞춘 50개 중 우연히 정답이었던 2개를 제외하고 모든 CoT가 논리적이고 수학적으로 정확함
- 모델이 오답을 제시한 50개 중에서 46%의 CoT는 작은 실수(계산 오류, 기호 사용 오류, 추론 단계 누락)를 제외하고 거의 정확했으며, 나머지 54%의 CoT는 의미를 잘못 이해하거나 일관성이 떨어지는 큰 오류를 보임
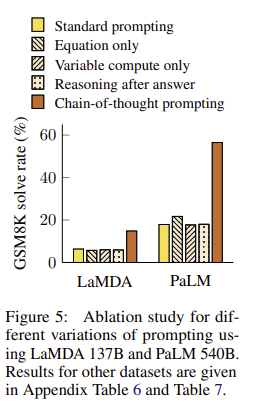
▶ 3.3 Ablation Study
3가지 방법의 다른 프롬프트 유형에서도 chain-of-thought prompting가 동일하게 효과적인지 검증
① Equation only
- 프롬프트에 자연어를 사용하지 않고 수식만을 포함하였을 때도 성능이 좋아지는지 확인
- GSM8K와 같이 어려운 문제는 수식만 포함된 프롬프트로 성능이 좋아지지 않았지만, 한두단계만 거치고 풀 수 있는 단순한 문제는 성능 향상을 보임
② Variable compute only
- CoT prompting의 성능 향상이 단순히 프롬프트의 길이가 길어지면서 Standard prompting 때보다 모델이 다루는 토큰 수가 늘어나면서 연산량이 증가에 의한 것인지 검증
- Standard prompting에서 '...'을 넣어 CoT 때와 동일한 토큰으로 동일한 연산량을 가지도록 만들어 실험
- 연산량이 같더라도 여전히 CoT가 성능이 좋았음. 단순히 연산량 증가로 인한 성능 향상은 아니였음을 의미
③ Chain of thought after answer
- CoT prompting의 성능 향상이 단순히 사전 정보를 더 많이 입력했기 때문인지 검증
- CoT prompting을 정답 이후에 두고 실험
- 이 경우 Standard prompting과 유사한 성능을 보임. CoT prompting이 단순한 정보 추가의 측면이 아닌 논리 전개 과정을 학습하는데 도움을 주어 성능을 향상시킴을 의미
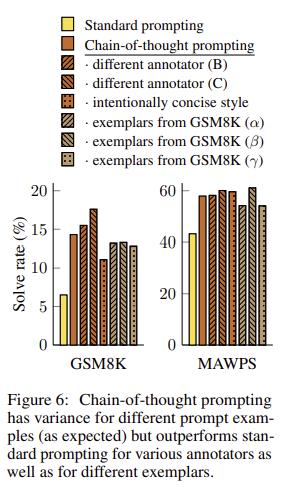
▶ 3.4 Robustness of Chain of Thought
- CoT prompting의 exemplars에 대한 민감도 검증
- 서로 다른 사람이 설계한 프롬프트들에 대해서 동일하게 좋은 성능을 보이는지 실험
- 또한 서로 다른 exemplars에서도 작동하는지 확인하기 위해 8개의 exemplars 중 3개를 임의 선택하여 실험
- 모든 프롬프트들에서 standard prompting보다 CoT prompting에서 성능이 향상
==> CoT prompting이 exemplar와 annotator에 robust
▶ 4. Commonsense Reasoning
- 상식 추론 문제에서 CoT prompting 사용한 언어 모델의 성능 평가
- 5가지 benchmarks : CSQA, StrategyQA, BIG-bench의 Date Understanding과 Sports Understanding 문제, SayCan
- 이전 실험과 유사하게 데이터셋에서 일부를 랜덤 선택해 few-shot exemplars를 직접 제작
- PaLM 모델에 적용한 결과, 모든 benchmarks에서 모델의 규모가 커짐에 따라 CoT에 의한 성능 향상이 극대화
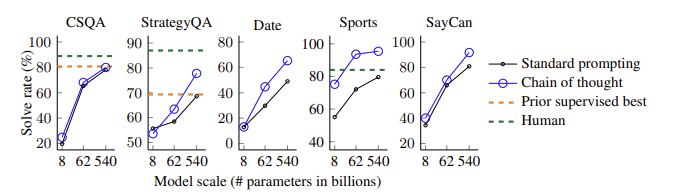
▶ 5. Symbolic Reasoning
- 기호 추론 문제에서 CoT prompting 사용한 언어 모델의 성능 평가
- 2가지 toy tasks 이용
- Last letter concatenation : 주어진 이름의 각 단어에서 마지막 글자끼리 연결하는 문제
- Coin flip : 주어진 지문을 따르는 결과 동전이 뒤집어졌는지 아닌지 답하는 문제
- 2가지 test set 이용
- in-domain test set : training/few-shot exemplars와 논리 step의 개수가 동일한 test set
- out-of-domain (OOD) test set : training/few-shot exemplars보다 논리 step의 개수가 더 많은 test set
- 예) training/few-shot exemplar가 2단어로 이루어진 이름일 때, test에서도 2단어 이름이 주어진다면 in-domain, 더 긴 단어의 이름이 주어진다면 OOD

- 크기가 작은 모델에선 CoT prompting가 정답률이 떨어짐
- Letter Concat in domain 문제에선 PaLM 540B를 사용하면 CoT prompting가 거의 100%에 해당하는 정답률을 보임
- standard prompting와 달리 CoT prompting은 in-domain 뿐만 아니라 OOD 문제도 잘 해결
▶ 6. Discussion
1) CoT의 의의
- CoT prompting은 산술 추론, 상식 추론, 기호 추론 모두에서 좋은 성능을 보임
- 이미 개발된 LM을 fine-tuning 없이 prompting만 사용하여 chain-of-thought reasoning을 적용할 수 있음
- standard prompting에선 모델 크기 증가에 따른 성능 향상이 완만(flat scaling curve)
→ 대규모 언어모델의 성능에 대한 낮은 한계
- CoT prompting은 모델 크기에 따라 성능을 극적으로 향상시킴 (dramatically increasing scaling curve)
→ 대규모 LLM이 성공적으로 수행할 수 있는 task를 확장
- 모델 크기가 추가로 증가함에 따라 추론 능력이 얼마나 더 향상될 것으로 기대할 수 있을지, 언어 모델이 해결할 수 있는 작업의 범위를 확장할 수 있는 다른 프롬프트 방법은 무엇인지 등의 질문을 남김
2) CoT의 한계
- neural network가 정말로 인간의 추론 과정을 흉내낸 것인지에 대한 확답 불가
- few-shot exemplars를 직접 만드는 것에 엄청난 비용이 소요
- 올바른 추론 경로에 대한 정해진 답이 없음
- 대규모 모델에서만 성능 향상을 보였기 때문에 소규모 모델에 적용하기 어려움
▶ 8. Conclusions
- 언어 모델에서 추론을 향상시키기 위한 간단하고 광범위하게 적용할 수 있는 방법으로 chain-of-thought prompting을 제시
- chain-of-thought reasoning은 충분히 큰 언어 모델이 성공적으로 추론 task를 수행할 수 있도록 해줌
Reference
https://aws.amazon.com/ko/what-is/prompt-engineering/
https://www.samsungsds.com/kr/insights/prompt-engineering.html
https://rfriend.tistory.com/843
https://taeyuplab.tistory.com/15
https://basicdl.tistory.com/entry/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Chain-of-Thought-Prompting-Elicits-Reasoning-in-Large-Language-Models



