

working_helen
[NLP 학습] 2주차 : GPT-1 / 논문 리뷰 : Improving Language Understanding by Generative Pre-Training 본문
[NLP 학습] 2주차 : GPT-1 / 논문 리뷰 : Improving Language Understanding by Generative Pre-Training
HaeWon_Seo 2024. 8. 13. 11:38

이전 포스트에서 다룬 Transformer의 개념을 바탕으로 GPT-1에 대해 학습해본다. GPT-1과 관련된 논문 "Improving Language Understanding by Generative Pre-Training"를 리뷰한다.
1. GPT-1
2. 논문 리뷰
1. GPT-1
- OpenAI에서 2018년에 발표한 “Improving Language understanding by Generative Pre-Training" 논문에서 제안된 모델
- Generative Pre Training of a language model
- 자연어 처리 분야에서 전이 학습의 가능성을 처음으로 입증한 모델 중 하나
- 이후 GPT-2, GPT-3, GPT-4와 같은 후속 모델들로 이어짐
1) GPT-1 등장 배경
- 기존의 NLP 모델은 대부분 supervised learning 방식을 사용했지만,
NLP task에서 labeled data를 충분히 확보하기 쉽지 않고 사람의 labeling은 비효율적
- 이와 달리 unlabeled data는 대규모로 존재하지만 효과적으로 활용할 수 있는 방법이 부재
- 또한 각각의 NLP 모델은 특정한 task에 맞춰서 설계되었기 때문에
서로 다른 task에 대해서 새로운 모델을 학습시켜야하는 문제
➡️ GPT-1
= unsupervised learning으로 generative pre-training 모델을 먼저 학습,
→ supervised learning으로 각각의 task에 specific한 discriminative 모델로 fine-tuning
= 대규모 unlabeled data에서 학습한 Transformer 기반의 generative pre-training 모델
→ 비교적 적은 labeled data에서 학습한 downstream task discriminative 모델
= 대규모 unlabeled data를 활용함으로써 모델의 성능을 높이는 동시에
전이학습을 도입함으로써 약간의 변형만 가지고도 다양한 NLP tasks로 transfer할 수 있음
==> unlabeled data에서 학습된 generative pre-training 모델을 전이학습함으로써
다양한 자연어 처리 작업에서, 적은 양의 labeled data로도 높은 성능을 달성할 수 있는 모델
GPT-1 논문의 의의
- 대규모 unlabeled data를 활용할 수 있는 모델
- NLP 분야에 전이학습을 도입
2) GPT-1 의 구조
- multi-layer Transformer decoder 구조
= Transformer에서 encoder는 제외하고 decoder만을 가져온 구조
- tokens embedding(W_e)→ potision encoding(W_p)
→ n개의 decoder layer를 통과
→ masked multi-head self-attention → Residual connection + Layer Normalization
→ feed forward → Residual connection + Layer Normalization
→ linear + softmax layer → output probabilities

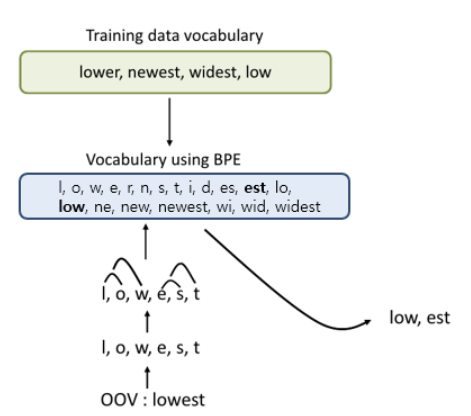
① BPE(Byte-pair encoding)
- subword-based tokenization, subword segmentation
- 텍스트를 단어가 아닌 subword 단위로 분할, 하나의 단어를 여러 서브워드로 분리하여 encoding
(예: birthday = birth + day로 분리)
- OOV(Out-Of-Vocabulary) 문제를 완화할 수 있음
- 가장 많이 등장한 글자의 쌍을 찾아 병합하는 과정을 연속적으로 진행
step 1. 훈련 데이터에 있는 단어들을 문자 단위로 분리해 vocabulary 구성

step 2. vocabulary 문자들로 연결된 문자쌍 각각의 빈도수를 계산
step 3. 빈도수가 가장 높은 문자쌍을 병합하여 vocabulary에 추가
(빈도수가 9로 가장 높은 (e, s) 쌍을 es로 병합하여 vocabulary에 추가)

step 4. 원하는 vocabulary 크기에 도달할 때까지 문자쌍을 추가하는 과정을 반복
(빈도수가 9로 가장 높은 (es, t) 쌍을 est로 병합하여 vocabulary에 추가)

==> 기존에 없던 단어 ' lowest'가 입력되었을때 이를 <UNK> 처리하는 것이 아니라
vocabulary에 있는 'low'와 'est'로 구분하여 encoding
* OOV(Out-Of-Vocabulary) 문제
언어 모델은 자신이 모르는 단어가 등장하면 이를 <UNK>로 인식하는데, 이때 모델이 모르는 단어가 너무 많아져 문제 해결에 어려움을 겪는 것을 OOV 문제라고 한다.
② unsupervised pre-training
- 대규모 unlabeled data를 사용, Next Word Prediction task 수행
- standard language modeling objective 이용
➡️ 일반적인 언어 구조, 문맥, 패턴 등을 학습
③ supervised fine-tuning
- 적은 수의 labeled data를 사용, 각각의 specific task 수행
- auxiliary objective = target task objective + auxiliary unsupervised training objective 이용
- pre-training에서 학습한 모델을 초기 파라미터로 이용
- 각각의 task에서 사용되는 dataset의 형태를
pre-training한 Transformer 모델의 input 형태로 변환해주는 과정 필요
➡️ 전이학습으로 specific task에서 높은 성능 달성
2. 논문 리뷰
논문명 : Improving Language Understanding by Generative Pre-Training
저자명 : Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever
https://openai.com/index/language-unsupervised/
✏️ 논문 내용 정리
- GPT-1 모델 고안 배경
: NLP의 다양한 task에서 unlabeled data는 풍부하게 존재하지만,
supervised learning에 필요한 labeled data는 매우 부족하다는 문제점
- GPT-1 모델과 이전 모델의 차이점
" using a combination of unsupervised pre-training and supervised fine-tuning "
: 대규모 unlabeled data를 사용해 language modeling task를 수행하는 unsupervised pre-training 모델을 먼저 학습한 후, labeled data를 사용해 이를 각각의 task에 specific하게 fine-tuning
- GPT-1 의 구조
= multi-layer Transformer decoder
= 기존의 Transformer 구조에서 decoder만을 가져와 사용
① Unsupervised Pre-Training : standard language modeling objective
② Supervised Fine-Tuning : auxiliary objective
= target task objective + auxiliary unsupervised training objective
- 논문에서 보인 모델 특성
① 12개의 NLP task dataset 중 9개 데이터 세트에서 새로운 sota 달성
② pre-trained 모델의 layer를 많이 사용할수록 fine-tuning 모델도 성능이 좋아짐
③ pre-training을 많이 진행할수록 fine-tuning 이후의 성능이 좋아짐
▶ 0. Abstract
- unlabeled text data는 풍부한 것에 비해, NLP 모델 학습에 필요한 labeled data는 부족
- 이 논문에선 언어모델을 대규모 unlabeled text data를 기반으로 generative pre-training한 후 각각의 특정한 task에 대하여 discriminative fine-tuning하는 방식이 매우 유용함을 보임
- fine-tuning 과정에서 각각의 task마다 적합한 입력 형태로 task-aware input transformations하는 과정을 사용함으로써 모델 아키텍처를 최소한으로 변경하면서도 효과적으로 transfer
- 실험 결과 새롭게 제안한 general task-agnostic model은 각 task에 대하여 discriminatively trained models보다 더 성능이 뛰어남
▶ 1. Introduction
1) unsupervised learning 모델의 필요성
- NLP 분야에는 labeled data가 부족하기 때문에 supervised learning에 대한 의존성을 완화하기 위해선 raw text를 학습할 수 있는 능력이 매우 중요
- 하지만 대부분의 딥러닝에서 사람이 직접 라벨링한 labeled data를 사용하기 때문에 labeled data가 부족한 많은 도메인에 적용이 어려움
- 이를 해결하기 위해 unlabeled data의 정보를 활용할 수 있는 모델이 필요
- unsupervised learning으로 좋은 representation을 학습하는 것은 상당한 성능 향상에도 기여
2) unsupervised learning의 문제
- 어떤 유형의 optimization objectives가 다양한 tasks로 transfer하기에 유용한 representations을 학습하는 데 가장 효과적인지 불분명, tasks에 따라 가장 성능이 좋은 optimization objectives가 달라짐
- 학습된 representations을 task로 transfer하는 가장 효과적인 방법에 대해 정해진 바가 없음
- 이러한 불확실성에 의해 기존 모델에선 semi-supervised learning 방식을 적용하기 어려움
- 다량의 unlabeled data를 제대로 학습하는 모델을 생성하기 어려움
3) 새로운 모델 제안
" semi-supervised approach for language understanding tasks
using a combination of unsupervised pre-training and supervised fine-tuning "
- unsupervised pre-training + supervised fine-tuning 2단계로 학습하는 언어모델
- language modeling objective를 사용한 unsupervised learning으로 모델의 초기 파라미터 학습
- target task의 objective를 사용한 supervised learning으로 학습한 초기 피라미터를 각 task에 적용
① unsupervised pre-training
- 대규모 unlabeled text data 사용
- unsupervised learning으로 language modeling task(다음 단어를 예측하는 task) 언어 모델 학습
- 문장의 일반적인 구조, 문맥, 어휘 등에 대한 정보를 먼저 학습
② supervised fine-tuning
- 수동적으로 라벨링된 labeled text data 사용
(pre-training에 사용된 데이터와 같은 도메인일 필요 없음)
- pre-training한 모델을 supervised learning으로 구체적인 target task에 맞추어 추가 학습
- 여러 NLP task에서 작은 규모의 labeled data로도 높은 성능을 달성할 수 있게 됨
➡️ 대규모 unlabeled data를 활용하여 약간의 변형만 가지고도 다양한 NLP tasks로 transfer할 수 있는 universal representation을 학습하는 언어모델 생성
➡️ 모델 아키텍처로 Transformer를 사용하여 long-term dependencies를 제어함으로써 pre-training된 모델을 각 task로 안정적으로 transfer
※ Transfer Learning = pre-training + fine-tuning
① pre-training 사전학습
- 모델의 초기 파라미터를 다른 task에서 학습시킨 가중치들로 설정하는 방법
- 모델을 현재 task에 대해 학습시키기 위해 다른 task에서 먼저 학습시켜 얻은 파라미터를 사용
② fine-tuning 미세조정
- pre-training한 모델을 특정 task에 맞추어 추가로 학습시키는 과정
- pre-training한 모델을 기반으로 새로운 데이터셋에 맞춰 모델을 조정하는 방식
- pre-training으로 이미 학습한 능력을 바탕으로 특정 task에 더 정교하게 학습
(참고 링크) https://velog.io/@soyoun9798/Pre-training-fine-tuning
▶ 2. Related Work
● Semi-supervised learning
- unlabeled data로부터 단어 수준 이상의 의미를 학습하는 연구가 진행되어옴
- unlabeled data로부터 학습된 구문 혹은 문장 수준의 embedding은 text를 다양한 task에 적합한 representation으로 인코딩하는 데 사용되고 있음
● Unsupervised pre-training
- 좋은 initial representation를 찾기 위한 semi-supervised learning
- DNN 모델의 일반화 성능을 높이는데 기여
- Transformer에선 pre-training 단계로 긴 범위의 언어 정보를 포착하는 것이 가능함
● Auxiliary training objectives
- supervised fine-tuning하는 과정에서 target task objective에다가 auxiliary(보조적인) unsupervised training objectives를 추가하여 사용함
▶ 3. Framework
① unsupervised pre-training : 대규모 text corpus에서 언어모델 학습
② supervised fine-tuning : 언어 모델을 각각의 task에 적용시킴
GPT-1 = multi-layer Transformer decoder
= Transformer에서 encoder는 제외하고 decoder만을 가져와 사용

▶ 3.1 Unsupervised Pre-Training

- W_e : token embedding matrix
- W_p : potision embedding matrix
- n : number of decoder layers
- tokens embedding(W_e)→ potision encoding(W_p)
→ n개의 decoder layer를 통과 → linear + softmax layer → output probabilities
- 각 decoder layer에선
→ masked multi-head self-attention → Residual connection + Layer Normalization
→ feed forward → Residual connection + Layer Normalization
- encoder가 없기 때문에 encoder-decoder attention layer는 제거
- objective = standard language modeling objective

- U = {u_1 , . . . , u_n} : unsupervised corpus of tokens
- k : size of the context window
- Θ : neural network parameters
▶ 3.2 Supervised Fine-Tuning

- C : labeled dataset
- {x_1 , . . . , x_m} : input tokens / y : label
- W_y : embeddings for delimiter tokens
- h_ml : final transformer block’s activation
- input을 pre-trained model에 통과시킴
→ final transformer block’s activation h_ml
→ linear + softmax layer → output probabilities
- objective = auxiliary objective
= target task objective(L_2) + auxiliary unsupervised training objective(L_1)
- L_2에 L_1을 추가하는 것이 supervised model의 일반화 성능을 높이는데 기여

- λ : Pre-Training Loss L_1의 가중치
▶ 3.3 Task-Specific Input Transformations
- pre-trained 모델의 input은 ordered text sequence 형태
- pre-trained 모델을 각각의 task에 적용하기 위해 입력 데이터를 ordered text sequence 형태로 변환하는 과정을 진행
- 이처럼 GPT-1을 사용하면 task에 따라 input의 형태만 바꾸고 fine-tuning함으로써 각 task마다 아키텍쳐를 급격하게 변화시켜 사용해야하는 문제를 피할 수 있음
- Text Classification : 분류하려는 문장 sequence를 directly하게 input으로 사용
- Textual entailment : 두 문장 간 관계를 분류하는 문제, premise(전제)와 hypothesis(가설)를 사이에 중간 구분 문자 $를 두고 연결한 sequence를 input으로 사용
- Similarity : 두 문장의 유사성 비교하는 문제, 특별한 순서 관계가 없기 때문에 [text1, text2]와 [text2, text1] 2개의 연결 sequence를 각각 input으로 사용한 후 마지막 linear layer에 들어가기 전 모델 출력 결과를 element-wise로 합함
- Question Answering and Commonsense Reasoning : context document(지문) z, question(질문) q, set of possible answers(답변 리스트) {a_k}로 구성, [z; q; $; ak] k개의 연결 sequence를 각각 input으로 사용한 후 softmax를 통해 정규화되어 가능한 답변에 대한 출력 분포를 생성
▶ 4. Experiments
▶ 4.1 Setup
- Unsupervised pre-training
- BooksCorpus dataset : 다양한 장르의 7,000개 이상의 책 데이터셋
-모델이 long-range 정보를 학습하도록 만들 수 있는 긴 텍스트가 포함 - Model specifications
- 12-layer decoder-only transformer with masked self-attention heads
- 12개의 attention heads
- position-wise feed-forward network : 3072차원의 은닉층
- Adam optimization, max learning rate = 2.5e-4
- Batch size = 64 / epochs = 100
- token length = 512
- Gaussian Error Linear Unit (GELU) activation function
- learned position embeddings
- ftfy library, spaCy tokenizer - Fine-tuning details
- reuse the hyperparameter settings from unsupervised pre-training
- add dropout with a rate of 0.1
- learning rate = 6.25e-5
- Batch size = 32 / epochs = 3
- λ = 0.5
▶ 4.2 Supervised fine-tuning
- 다양한 supervised NLP task에서 실험, evaluation metric = accuracy
- 12개 task dataset 중 9개 데이터 세트에서 새로운 sota 달성
1) natural language inference (NLI)

- 문장 한 쌍을 읽고 문장 간의 관계를 판단
- 5가지 dataset : image captions (SNLI), transcribed speech, popular fiction, government reports (MNLI), Wikipedia articles (QNLI), science exams (SciTail), news articles (RTE)
- 5가지 중 4가지 dataset에서 sota 달성
- 제안된 모델이 여러 문장에 대해 추론 하고 언어적 모호성의 측면을 처리하는데 더 효과적임
2) Question answering and commonsense reasoning

- 단일 및 다중 문장에서 추론, long-range 맥락 처리
- 2가지 dataset : RACE, Story Cloze Tes
- 2가지 dataset 모두에서 sota 달성
- 제안된 모델이long-range 맥락을 효과적으로 처리하는데 더 효과적임
3) Semantic Similarity
- 두 문장이 의미론적으로 동일한지 여부를 예측
- 3가지 dataset : Microsoft Paraphrase corpus (MRPC), Quora Question Pairs (QQP), Semantic Textual Similarity benchmark (STS-B)
- 3가지 중 2가지 dataset에서 sota 달성
4) Classification
- 2가지 dataset : Corpus of Linguistic Acceptability (CoLA), Stanford Sentiment Treebank (SST-2)
- CoLA에선 sota 달성, SST-2에선 sota와 견줄만한 성능을 보임

▶ 5. Analysis

1) Impact of number of layers transferred
- unsupervised pre-training 모델을 supervised target task으로 transfer할때 transfer layer의 개수가 미치는 영향을 측정
- 사용한 transfer Layer의 개수가 많을수록 성능이 좋아짐
- pre-trained 모델의 정보를 많이 사용할수록 fine-tuning 모델도 성능이 좋아짐
- pre-trained 모델의 각 layer가 target task를 해결하는데 유용한 기능을 가지고 있음
2) Zero-shot Behaviors
- 왜 pre-training이 모델 성능 향상에 도움을 주는가?
- underlying generative model이 얼마나 pre-training 되었는지에 따른 모델 성능 측정
- pre-training을 많이 진행할수록 fine-tuning 이후의 성능이 좋아짐
- underlying generative model이 pre-training을 통해 다양한 task를 수행하는데 필요한 많은 부분을 이미 학습한다는 것을 의미
- 또한 Transformer 구조가 LSTM보다 underlying generative model의 구조로 더 적합함
3) Ablation studies
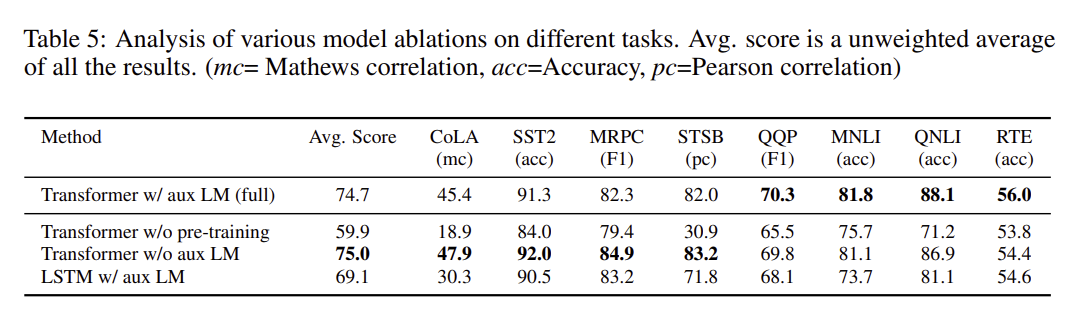
① fine-tuning에서 auxiliary LM objective을 포함하지 않는 모델의 성능
- auxiliary objective는 NLI과 QQP task에서 유용함
- dataset이 클수록 auxiliary objective의 이득을 더 받음
② Transformer vs single layer 2048 unit LSTM
- Transformer 대신 LSTM을 사용하면 평균 score가 5.6% 하락
- MRPC에 대해서만 LSTM이 더 좋은 성능을 보임
③ pre-training하지 않은 모델과 비교
- 모든 task에 있어서 pre-training을 하지 않고 바로 모델링한 경우 성능이 저하
- 평균 score가 14.8% 하락
▶ 6. Conclusion
- generative pre-training와 discriminative fine-tuning를 통해 하나의 task에만 국한되지 않는 강력한 자연어 이해 모델 제안
- 다양한 긴 문장으로부터 pre-training한 모델은 상당한 지식과 long-range dependencies를 처리할 수 있는 능력을 갖춤으로써 각각의 discriminative task로 성공적으로 transfer됨
- question answering, semantic similarity assessment, entailment determination, text classification 등 NLP task에 대한 12개의 dataset 중 9개에서 새로운 sota를 달성
- unsupervised (pre-)training을 통한 상당한 성능 향상을 실현
- 자연어 이해 및 다른 영역 모두에 대한 unsupervised learning에 대한 새로운 연구를 촉발
Reference
https://wikidocs.net/22592
https://actionpower.medium.com/%EC%95%A1%EC%85%98%ED%8C%8C%EC%9B%8Clab-gpt-1-generative-pre-training-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0-f63f18efa625
https://da2so.tistory.com/76
https://ffighting.net/deep-learning-paper-review/language-model/gpt-1/
https://lcyking.tistory.com/entry/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-GPT-1Improving-Language-Understandingby-Generative-Pre-Training%EC%9D%98-%EC%9D%B4%ED%95%B4



