
working_helen
[NLP 학습] 3주차 : RAG model / 논문 리뷰 : Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 본문
[NLP 학습] 3주차 : RAG model / 논문 리뷰 : Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
HaeWon_Seo 2024. 8. 24. 14:41이전 포스트에서 다룬 언어모델에 대한 이해를 바탕으로 RAG model에 대해 학습해본다. RAG model과 관련된 논문 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"를 리뷰한다.
1. RAG model
2. 논문 리뷰
1. RAG model
- Facebook AI Research(FAIR) 팀에서 2020년에 발표한 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" 논문에서 제안된 모델
1) RAG 등장 배경
- 기존의 LLM은 학습 시점에 제공되는 데이터로부터 정보를 추출하여 파라미터에 저장하는 방식을 사용하기 때문에 학습 시 제공하지 않은 데이터에 대해서는 정보를 얻지 못함
- 모델이 어떤 정보를 사용하여 결과를 출력했는지에 대한 근거를 명확히 찾기 어려움
- Hallucination 환각 문제 : 학습 데이터의 패턴을 바탕으로 실제로는 사실이 아닌 정보를 생성하는 경우가 존재
➡️ RAG
= LLM이 결과를 출력할 때 신뢰할 수 있는 외부 데이터베이스를 참조할 수 있게 만드는 기술
= LLM이 기억된 정보에만 의존하는 대신
실시간으로 외부 데이터베이스에서 정보를 검색하고 활용할 수 있도록 만든 기술
= 이미 LLM이 파라미터에 가지고 있는 지식 + 외부에서 검색한 최신 지식을 모두 사용
==> LLM이 학습 데이터로 제시되는 정보뿐만 아니라
새로운 지식을 실시간으로 업데이트 받아 더 정확한 최신의 결과를 출력 가능
- 학습 시점에 포함되지 않았던 최신 데이터도 활용 가능
시간에 따라 정보가 바뀌어도 이를 반영해 학습 가능
- 검색된 지식을 근거로 한 출력으로 Hallucination 문제 해소
2) RAG의 원리
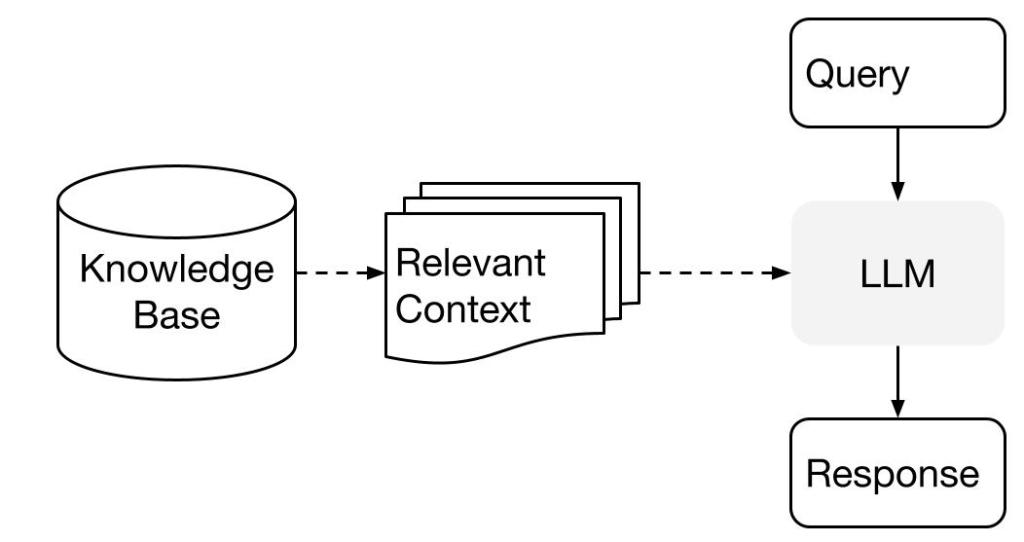
① Retrieval 검색
- 외부 데이터베이스에 접근하여 입력받은 Query와 관련된 정보를 검색
- Query와 가장 관련성이 높은 상위 k개의 documents를 검색
② Augmentation 증강
- 검색해온 정보를 LLM의 추가적인 입력값으로 사용
- 검색된 정보를 이용해 입력값 증강
③ Generation 생성
- 증강된 입력값을 바탕으로 LLM이 최종 결과를 출력
* RAG vs fine-tuning
- fine-tuning 모델은 특정 시점까지의 데이터만 사용
→ 실시간으로 외부 데이터에 접근해야하거나 데이터가 역동적으로 변하는 경우 RAG가 효과적
- fine-tuning은 supervised learning
→ labeled data가 확보하기 어려운 경우엔 RAG가 효과적
- fine-tuning은 주어진 데이터만 기반으로 하지만, RAG는 매 질문마다 외부 근거를 기반
→ RAG가 Hallucination 방지에 더 유리하며 해석 가능성도 더 높음
- RAG는 모델이 활용할 수 있는 추가적인 정보만 불러오는 방식
→ 모델의 근본적인 동작 스타일(어조) 혹은 도메인 전문성(전문 용어) 등을 변화시키려면 fine-tuning이 더 효과적
∴ 역동적으로 변화하는 데이터에 실시간으로 접근한 후 이 데이터를 근거로 판단하는 모델을 만들고 싶다면 RAG, 체계적으로 labeling된 데이터를 이용해 특정 task에 더 특화된 모델을 만들고 싶다면 fine-tuning
2. 논문 리뷰
논문명 : Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
저자명 : Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
https://arxiv.org/abs/2005.11401
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still lim
arxiv.org
✏️ 논문 내용 정리
- RAG model 고안 배경
: 기존의 LLM은 pre-training으로 데이터로부터 얻은 정보를 파리미터에 저장함으로써 지식을 학습하지만, 지식의 업데이트가 어렵고 출력 결과에 대한 근거를 직접적으로 제시해주지 않는 문제
=> knowledge-intensive NLP tasks(인간이 외부 지식없이 수행하기 어려운 task)에서 성능이 좋지 않음
- RAG model과 이전 모델의 차이점
: parametric memory + non-parametric memory hybrid
" 기존의 pre-trained parametric-memory generation models
+ non-parametric memory에 접근하는 pre-trained neural retriever "
파라미터를 사용하는 기존의 생성 모델 + 외부 메모리에 접근하는 검색 모델
기존의 파라미터 기반 생성모델에서 외부 지식을 검색할 수 있도록 보완한 모델
- RAG model의 구조
① Generator : p_θ(y_i|x,z,y_(1:i−1))
- parametric memory를 학습하여 language generation
- encoder-decoder 구조의 pre-trained seq2seq transformer
이 논문에선 BART_large 400M 이용
② Retriever : p_η(z|x)
- non-parametric memory에 접근하여 input과 관련된 지식(documents)을 검색함
- Query Encoder-Document Index 구조의 pre-trained neural retriever
이 논문에선 DPR의 pre-trained bi-encoder 이용
- 검색 방법에 따라 2가지 Retriever 모델
RAG-Sequence Model : 각각의 출력 토큰에 대해서 동일한 documents를 참조
RAG-Token Model : 각각의 출력 토큰마다 서로 다른 documents를 참조
③ 모델 학습 과정
- retriever는 non-parametric memory로 접근하여 input과 관련된 top-K latent documents를 검색
→ generator는 이 latent documents와 input을 모두 사용해서 output 생성
- generator와 retriever를 동시에 pre-training
→ 모든 sequence-to-sequencen task로 fine-tuning
- 논문에서 보인 모델 특성
① knowledge-intensive NLP tasks에서 좋은 성능을 보임
② 모델을 재학습시킬 필요 없이 documents index를 바꿔주는 방식으로 새로운 지식을 업데이트 가능
③ open domain QA taks에서 새로운 sota를 달성했고, language generation tasks에선 매우 구체적이고 사실적인 결과물을 생성함
▶ 0. Abstract
- LLM은 pre-train으로 지식을 파라미터에 저장하고 fine-tuning하는 방식으로 여러 downstream task에서 sota를 달성
- 지식에 접근하여 정확하게 조작하는 능력은 여전히 제한적이므로 knowledge-intensive tasks에서는 성능이 떨어짐
- 또한 출력 결과에 대한 근거를 제시해주지 않고, 새로운 지식을 모델에 업데이트하는 것이 어려움
- language generation를 위해서 pre-trained parametric memory와 non-parametric memory를 결합한 새로운 모델 RAG(retrieval-augmented generation)를 제안
- parametric memory는 pre-trained seq2seq 모델, non-parametric memory는 dense vector index of Wikipedi를 사용하며, pre-trained neural retriever를 이용해 접근함
- 다양한 knowledge-intensive NLP tasks에 대해 fine-tuning을 진행한 결과, 3가지 open domain QA taks에서 새로운 sota를 달성했고 language generation tasks에선 parametric-only seq2seq sota 모델보다 더 구체적이고 사실적인 결과물을 생성한다는 것을 확인함
▶ 1. Introduction
1) 기존 모델의 한계
- pre-trained 모델은 외부 메모리에 접근하지 않고, 데이터로부터 얻은 정보를 파리미터에 저장함으로써 상당한 양의 심층 지식을 학습
- 메모리 수정 및 확장이 쉽지 않고, 예측에 대한 직접적인 통찰을 제공해주지 않는다는 단점
- parametric memory와 non-parametric memory를 모두 사용하는 hybrid model은 지식을 직접 수정 및 확장 가능하고 해석할 수 있음
- 하지만 이때까진 hybrid model를 open-domain extractive question answering task에서만 사용
2) RAG (retrieval-augmented generation)
- hybrid parametric and non-parametric memory를 seq2seq models에 적용
- pre-trained parametric-memory generation models + non-parametric memory
➡️ 파라미터를 사용하는 생성 모델 + 외부 메모리 기반 검색 모델
기존의 파라미터 기반 생성모델에서 외부 지식을 검색할 수 있도록 보완한 모델
- Generator = parametric memory : BART, pre-trained seq2seq transformer 구조
- Retriever : DPR (Dense Passage Retriever), Query Encoder + Document Index 구조,
non-parametric memory에 접근하는 pre-trained neural retriever - non-parametric memory : dense vector index of Wikipedia
- retriever는 input에 따라 외부 메모리로에서 top-K latent documents를 검색
→ generator는 이 latent documents와 input을 모두 사용해서 output 생성
- generator와 retriever는 모두 pre-train되며, 동시에 학습됨
- RAG는 모든 sequence-to-sequencen task에 fine-tuning될 수 있음
- parametric memory와 non-parametric memory를 결합한 모델은 지식 집약적인 task(인간이 외부 지식없이 수행하기 어려운 task)에 좋음
- 다양한 NLP task에서 새로운 sota 달성
* BART(Bidirectional and Auto-Regressive Transformers)
: BERT와 GPT의 장점을 결합하여 만든 모델
- Bidirectional Encoder : BERT와 유사하게 양방향 인코더를 사용해 양방향 context를 이해
- Auto-Regressive Decoder : GPT와 유사하게 디코더는 이전에 생성된 단어들을 기반으로 각 단어를 순차적으로 예측(생성)
- Noise-Corrupted Text : BART는 텍스트를 노이즈가 있는 상태로 변형한 후, 원래 텍스트를 예측하는(복원하는) 방식으로 학습
▶ 2. Methods
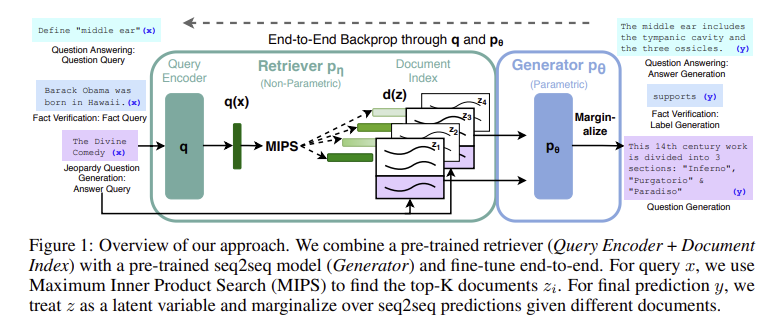
- x : input sequence
- z : retrieved text documents
- y : target sequence to generate
- p_η(z|x) : retriever
query x에 대하여 text passages의 distributions을 리턴 - p_θ(y_i|x,z,y_(1:i−1)) : generator
이전 토큰 y_(1:i-1), input x, retrieved passage z를 이용해서 현재 토큰 y_i를 예측
- retriever와 generator를 학습하기 위해 retrieved document를 latent variable로 설정
- latent documents를 marginalize하는 방식을 다르게 한 2가지 모델을 제안
- RAG-Sequence : 각각의 target 토큰을 예측하는데 동일한 document를 사용
- RAG-Token : 각각의 target 토큰을 예측할때마다 서로 다른 document를 사용
* marginalize : 여러 latent documents의 가능성을 바탕으로 정보를 통합하여 하나의 최종 출력을 계산하는 과정, 각각의 documents가 query x에 대해 답하는데 얼마나 중요한지 평가하고 중요도를 바탕으로 documents를 통합하여 최종 출력을 생성
▶ 2.1 Models
① RAG-Sequence Model
- use same retrieved document to generate the complete sequence
sequence내의 각 target token을 예측할 때 같은 documents를 사용
- generator가 각 z마다 전체 sequence y에 대한 p(y|x, z)를 계산하고 더함

→ retriever가 공통된 top K documents를 검색
→ 각각의 document z에 대해서 p(y|x, z) 확률 계산
p(y|x, z) = x, z, y_(i-1)가 주어졌을때 다음 토큰이 y_i일 확률의 i=1~N 곱
→ p(y|x) = p(x|z)와 p(y|x, z)를 곱한 값을 모든 z에 대해서 더함
➡️ 각각의 z를 기준으로 p(x|z) * p(y|x, z) 계산한 후 더하는 marginalized
② RAG-Token Model
- use a different latent document for each target token and marginalize accordingly
sequence내의 각 target token을 예측할 때 서로 다른 documents를 사용
- generator가 각 토큰 y_i마다 서로 다른 z를 이용해 p(y_i|x, y_(i-1))를 계산하고 곱함

→ retriever가 각 토큰마다 top K documents를 검색
→ 각 토큰마다 각각의 document z에 대해서 p(y_i|x, z, y_(1:i-1)) 확률 계산
p(y_i|x, z, y_(1:i-1)) = x, z, y_(1:i-1)가 주어졌을때 다음 토큰이 y_i일 확률
→ p(y_i|x, y_(1:i-1)) = p(x|z)와 p(y_i|x, z, y_(1:i-1))를 곱한 값을 모든 z에 대해서 더함
→ p(y|x) = 모든 토큰의 p(y_i|x, y_(1:i-1)) 값을 곱함
➡️ 각각의 y_i를 기준으로 p(y_i|x, y_(1:i-1)) 계산한 후 곱하는 marginalized
p(y_i|x, y_(i-1))를 계산할 때 각각의 z를 기준으로 p(x|z)*p(y_i|x, z, y_(i-1)) 계산한 후 더함
▶ 2.2 Retriever: DPR
p_η(z|x) : retriever component
- input x에 대한 document z의 prior probability
- DPR의 pre-trained bi-encoder를 사용하여 retriever를 초기화
- DPR의 bi-encoder architecture
- d(z) : BERT_BASE document encoder에 의해 생성되는 document z의 dense representation
- q(x) : BERT_BASE query encoder에 의해 생성되는 query x의 representation

- p_η(z|x) : retriever, input x에 대한 document z의 prior probability
- d(z)와 q(x)를 내적한 값이 큰 top-k documents를 검색하는 방식
- 각 document index = non-parametric memory
▶ 2.3 Generator: BART
p_θ(y_i|x, z, y_(1:i−1)) : generator component
- input x, document z, 이전 토큰들 y_(1:i-1)이 주어졌을때 현재 토큰 y_i의 조건부확률
- encoder-decoder 구조의 어떤 모델을 사용해서든 학습 가능
- 이 논문에선 BART_large 400M 이용
▶ 2.4 Training
- retriever/generator를 동시에 훈련
- 어떤 document가 retrieve 되어야 하는지 직접적인 supervision를 주지않고,
Adam을 이용한 SGD로 negative marginal log-likelihood(NLL)를 최소화하도록 학습
- retriever의 BERTd(document encoder)는 학습 비용이 크기 때문에 이는 고정시키고,
retriever의 BERTq(query encoder)와 generator의 BART만 fine-tuning
▶ 2.5 Decoding
① RAG-Sequence

- 각각의 z를 기준으로 p(x|z) * p(y|x, z) 계산한 후 더하는 marginalized
- 각 z마다 전체 sequence y에 대하여 p(y|x, z)를 계산
- document마다 따로 beam search를 진행해야 함
document별로 p(y|x, z)값이 가장 높은 beam size b개의 hypothesis 선택
→ hypothesis y_1~y_5가 선택됨
→ 이젠 각각의 hypothesis y에 대해서 모든 document z에서의 조건부확률을 더함
이전 beam search에서 계산되지 않은 조건부확률 값은 0으로 설정 (Fast Decoding)
→ 조건부확률 합이 가장 높은 hypothesis를 최종 선택

② RAG-Token

- 각 y_i를 기준으로 p(y_i|x, y_(1:i-1)) 계산한 후 곱하는 marginalize
- 각 y_i마다 각각의 z에서의 조건부확률을 더하여 최종 조건부확률 p'_θ(y_i|x, y_(1:i-1))를 계산
- 토큰을 따라 순차적으로 standard beam search 하면 됨
▶ 3. Experiments & 4. Results
- 다양한 knowledge-intensive task에 대해 RAG model을 실험
- non-parametric memory = 2018년 12월 Wikipedia dump
- k ∈ {5, 10}
▶ 3.1 & 4.1 Open-domain Question Answering
- task : Natural Questions, TriviaQA, WebQuestions, CuratedTrec
- (x, y) = (question, answer)
- RAG : answer 예측의 NLL loss를 최소화하는 방식으로 학습
- 이전의 extractive QA paradigm : 주어진 지문 내에서 answer를 추출하는 방식
Closed-Book QA approaches : 외부 정보를 사용하지 않고 파라미터만 가지고 answer 예측
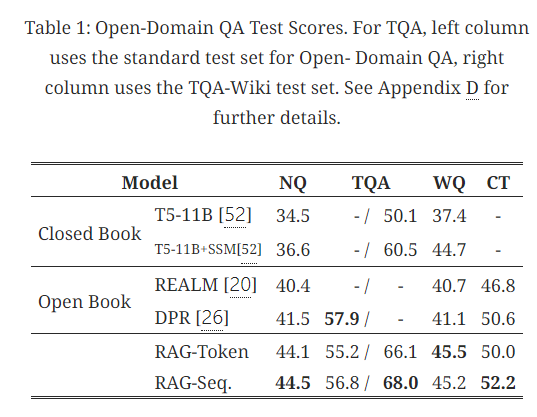
- 4가지 open-domain QA task에서 RAG가 새로운 sota 달성
- 단순히 document에 있는 answer를 추출하는 모델들과 달리, RAG는 검색된 documents에 직접적으로 정답이 없는 경우에도 정답에 대한 단서들을 사용해 정답을 생성할 수 있었음
- RAG = closed-book 방식의 유연성 + open-book 방식의 성능
▶ 3.2 & 4.2 Abstractive Question Answering
- QA 상황에서 RAG의 generation 능력을 평가
- task : MSMARCO NLG task v2.1
- task는 questions, 질문에 대해 검색엔진으로 찾은 10개의 gold passages, passages에 annotate되어 있는 answers로 구성
- passages는 사용하지 않고 questions/answers만 사용함으로써 Open-domain Question Answering처럼 만듬
- 하지만 passages 없이 Wikipedia만으로 풀 수 없는 문제가 있기 때문에 성능이 저하될 수 있음

- RAG가 Open MS-MARCO NLG task에서 BART의 성능을 넘음
- BART보다 올바른 텍스트를 더 자주 생성한다는 것을 발견
▶ 3.3 & 4.3 Jeopardy Question Generation
- non-QA 상황에서 RAG의 generation 능력을 평가
- task : answer entity에 대하여 Jeopardy questions을 생성하는 문제
answer entity가 주어지면 알맞은 question을 생성하는 knowledge-intensive generation task
- SQuAD-tuned Q-BLEU-1 metric + human evaluation을 사용하여 평가
* Jepordy questions : entity에 대한 팩트를 통해 entity를 추측하는 것
예) 1986년에 맥시코가 이 국제적 스포츠 경기를 두 번째로 개최한 나라가 되었다 → entity = 월드컵

- RAG가 Q-BLEU-1에서 BART보다 성능이 우수
- 특히 RAG-Token이 RAG-Sequence보다 성능이 좋았음. 이는 Jepordy questions 종종 별개의 두 정보를 포함하는데 RAG-Token은 여러 문서의 내용을 결합한 응답을 생성할 수 있기 때문인 것으로 해석됨
- non-parametric component는 parametric memory에 특정한 정보가 저장되도록 만듬
▶ 3.4 & 4.4 Fact Verification
- RAG의 classification 능력을 평가
- task : FEVER dataset을 사용해 자연어 claim이 wikipedia에 의해 support 되는지, refute 되는지, 혹은 wikipedia에 충분한 정보가 없는지를 판별하는 task
- claim과 관련된 정보를 wikipedia에서 검색 + 분류를 하기 위해 추론
- 3-way classification FVR3 : class labels = {supports, refutes, not enough info}
2-way classification FVR2 : class labels = {supports, refutes}

- RAG가 새로운 sota를 달성하지는 못했지만
복잡한 구조와 domain-specific architecture를 가지는 sota model에 근접하는 성능을 보임
▶ 4.5 Additional Results
① Generation Diversity
: generations n그램의 다양성 측면에서 두 RAG model 모두 BART보다 훨씬 다양했으며,
특히 RAG-Sequence의 generations이 RAG-Token보다 다양성이 높음
② Retrieval Ablations
: 검색(retriever) 메커니즘의 효과를 평가하기 위해 훈련 중에 검색을 사용하지 않는 경우(retriever를 freeze하는 경우)를 실험한 결과, retriever는 모든 task에서 성능을 향상
③ Index hot-swapping
: RAG가 사용하는 index를 변화시키는 실험을 진행한 결과 질문과 더 관련된 index를 사용했을때 성능이 더 뛰어남, 즉 non-parametric memory를 적절히 대체하는 것만으로도 RAG의 지식을 업데이트할 수 있음
④ Effect of Retrieving more documents
: 검색되는 latent documents의 수를 5와 10으로 두고 실험한 결과 RAG 성능에 큰 차이를 보이지 않았음, task에 따라 k에 따른 성능 변화가 다르게 관찰됨
▶ 6. Discussion
- parametric와 non-parametric memory를 모두 사용하는 hybrid generation 모델 RAG를 제안
- RAG는 open-domain QA에서 새로운 sota 달성
- RAG는 BART보다 더 사실적이고 구체적인 generation이 가능
- RAG에서 검색 메커니즘을 사용하는 것이 모델 성능에 효과적임을 보임
- RAG에선 재교육 없이 검색할 index를 바꿈으로써 모델을 업데이트할 수 있음
- Broader Impact : Wikipedia와 같은 실제 지식을 기반으로 하기 때문에 더 사실적이고 신뢰할 수 있으며, 더 많은 통제성과 해석 가능성을 부여함
- 단점으로는 사용하는 외부 정보가 사실이 아니거나 편향되어 있을 가능성 존재
Reference
https://brunch.co.kr/@acc9b16b9f0f430/73
https://brunch.co.kr/@delight412/620
https://www.skelterlabs.com/blog/rag-vs-finetuning
https://gbdai.tistory.com/67
https://everyday-log.tistory.com/entry/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Retrieval-Augmented-Generation-for-Knowledge-Intensive-NLP-Tasks



