[NLP 학습] 2주차 : BERT / 논문 리뷰 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding


이전 포스트에서 다룬 Transformer의 개념을 바탕으로 BERT에 대해 학습해본다. BERT와 관련된 논문 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"를 리뷰한다.
1. BERT
2. 논문 리뷰
1. BERT
- Google에서 2018년 발표한 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" 논문에서 제안된 모델
- Bidirctional Encoder Representations form Transformers
- 다양한 NLP task에서 혁신적인 성능 향상을 가져옴
1) BERT 등장 배경
- 기존의 PLM(Pre-trained Language Model)에서 사용하던 pre-training 모델은 left-to-right architecture
- 현재 토큰을 예측하는데 이전 토큰들의 정보만 사용하는
unidirectional language models을 pre-training 모델로 사용
- 이러한 단방향 문맥 이해는 양방향 context를 모두 반영하지 못한다는 문제
➡️ BERT
= deep bidirectional Transformer를 pre-training 모델로 사용하여
deep bidirectional representations를 학습
= 문장 내 토큰들의 양방향 문맥을 모두 이해할 수 있는 pre-training 모델을 사용
==> bidirectional pre-training을 통해 양방향 문맥을 모두 이해하도록 사전학습함으로써
복잡한 자연어 구조와 의미를 더 정확하게 파악하는 모델
BERT 논문의 의의
- bidirectional pre-training을 통한 양방향 문맥 이해의 중요성을 강조
- pre-training objectives로 2가지 task(MLM, NSP)를 제안
2) BERT의 구조
- multi-layer bidirectional Transformer encoder
- Transformer encoder를 여러 layer 쌓아올린 구조
input representation → embedding layer
→ 모든 encoder layer에서
multi-head self-attention → Residual connection + Layer Normalization
→ feed forward → Residual connection + Layer Normalization
→ ouput embedding = contextual embedding

Step 1. input representation = Token embedding + Segment embedding + Position embedding

① Token embedding : WordPiece embeddings
- BPE와 유사한 subword-based tokenization
: 텍스트를 단어가 아닌 subword 단위로 분할, 빈도가 높은 단어일수록 분할되지 않고 그 자체로 vocabulary 추가되고 빈도가 작은 단어일수록 subword로 분할되어 vocabulary에 추가됨
- BPE는 텍스트에서 가장 빈번한 문자쌍을 반복적으로 병합하는 단순 빈도 기반 방식
- WordPiece는 언어 모델의 성능 향상을 최대화하는 방향으로 문자쌍을 결합하는 방식
언어 모델과 연관되어 더 정교하게 subword를 선택할 수 있음
- WordPiece embedding 벡터 종류 = vocabulary의 크기
② Segment embedding
- 여러 sentence를 연결하여 입력값으로 사용하는 경우, 두 sentence 사이에 구분 토큰 [SEP] 추가
- [SEP] 토큰을 기준으로 각 토큰이 어떤 sentence에 속하는지에 알려주는 embedding
- 입력의 첫 번째 [SEP]까지는 Segment embedding A (보통 0),
그 이후부터 다음 [SEP]까지는 Segment embedding B (보통 1)로 설정
- Segment embedding 벡터 종류 = 문장의 최대 개수인 2개
③ Position embedding
- transformer encoder에서 self-attention을 사용하기 때문에 추가해주는 위치 정보 embedding
- sin/cos 함수가 아닌, 모델이 학습과정에서 최적화하는 각 위치별 고유한 벡터값을 사용
- Position embedding 벡터 종류 = 512개
BERT에서는 문장의 최대 길이를 512로 하고 있어 512개의 서로 다른 위치가 존재하게 됨
Step 2. pre-training
① Masked Language Model, MLM
- 입력에서 무작위하게 15%의 토큰을 골라 마스킹(Masking)하고 주변 단어를 사용해 마스킹된 토큰을 예측
- BERT가 단어의 양방향 문맥, 단어 간 관계, 문법이나 문장 구조 등을 학습
- 마스킹된 15%의 단어들은 아래와 같이 구성
- 80% : 토큰을 [MASK] 토큰으로 변경
Ex) My dog is cute. he likes playing → My [MASK] is cute. he likes playing - 10% : 토큰을 랜덤하게 다른 토큰으로 변경
Ex) My dog is cute. he likes playing → My dog is cute. King likes playing - 10% : 동일한 토큰으로 그대로 남겨둠
Ex) My dog is cute. he likes playing → My dog is cute. he likes playing

- 다른 토큰으로 변경된 10%와 그대로 남겨둔 10% 모두 모델은 원래 단어가 무엇인지에 대해 예측
그대로 남겨둔 10%에 대해서도 모델은 다른 토큰으로 변경된 것인지 혹은 원래 단어인지 알 수 없기 때문에
- [MASK]는 fine-tuning에서는 사용되지 않는 토큰 = 실제 데이터셋에서는 나타나는 않는 토큰
따라서 모델이 [MASK] 토큰에 대해서만 잘 예측하도록 학습시키는 것이 아니라 실제 단어들에 대해서도 잘 예측하도록 만들기 위해선 [MASK] 토큰이 아닌 실제 단어에서의 예측을 학습시켜야 함. 일부 마스킹 단어를 [MASK] 토큰으로 대체하지 않는 위와 같은 방식을 사용함으로써 모델이 [MASK] 토큰뿐만 아니라 입력으로 들어온 모든 토큰에 대해서 원본이 맞는지 확인하게 만듬. pre-training과 fine-tuning 간 입력 토큰의 불일치 문제를 해결하면서 모델의 언어 이해력을 더 향상시킴
② Next Sentence Prediction, NSP
- 두 문장 A, B에 대하여 이어지는 문장인지 아닌지를 예측
- BERT가 sentence relationships를 학습
- 문장쌍 학습 데이터셋을 아래와 같이 구성
- 50% : A와 B가 관련된 문장, A뒤에 B가 따라오는 문장, 'IsNext'라고 labeling
- 50% : A와 B가 관련없는 문장, 무작위 선택, 'NotNext'라고 labeling

- [CLS] token의 final hidden vector C를 이용해 이진 분류
- C를 feed-forward network → softmax 순서로 통과시켜 isNext와 NotNext에 대한 확률값 계산
Step 3. fine-tuning
- 사전학습된 BERT를 각각의 NLP task에 맞춰 조정하는 과정
- BERT의 가중치를 기반으로, task-specific layer나 파라미터를 추가하여 labeled data에서 전이학습

✅ GPT vs BERT
| GPT | BERT | |
| 모델의 목표 | 자연어 생성 (NLG) : 뛰어난 성능으로 다음 단어를 예측하여 자연스러운 언어 생성이 가능한 모델 |
자연어 이해 (NLU) : 단어의 양방향 정보를 모두 사용해 문맥을 정확하게 이해하는 모델 |
| 모델의 구조 | multi-layer unidirectional Transformer decoder | multi-layer bidirectional Transformer encoder |
| pre-training objectives | Language Modeling | Masked Language Modeling (MLM) + Next Sentence Prediction (NSP) |
| 학습 방식 | 다음 단어를 예측하는 단방향(left-to-right) 학습 | 앞뒤 문맥을 이해하여 특정 단어를 예측하는 양방향(bidirectional) 학습 |
| 모델의 규모 | - 수백억 개의 파라미터를 갖는 대규모 모델, 문장 생성에서 품질과 성능을 높이기 위해 |
- GPT에 비해 상대적으로 작은 크기의 모델 |
| 주요 적용 task | 텍스트를 생성하는 task (대화형 시스템(챗봇), 텍스트 생성 및 요약 등) | 텍스트를 이해하여 정리 및 분류하는 task (질의응답, 감정분석, 문장분류 등) |
| 장점 | - 단방향 예측으로 자연스러운 문장 생성 - 더 큰 데이터셋과 파라미터 수를 사용함으로써 (모델의 규모를 키움으로써) 성능 향상 가능 |
- 양방향 학습으로 문맥을 더 정교하게 이해 - 확장성이 높아 다양한 변형 모델로 발전 |
| 단점 | - 단방향 예측은 문맥을 한 방향으로만 처리하기 때문에 전체 문맥을 고려하는데 한계 | - 문맥 이해와 예측이 주요 목적이기 때문에 생성 모델로는 적합하지 않음 |
* BERT는 GPT에 비해 scale이 작은 이유
- BERT는 다양한 task에서 사용될 수 있도록 만든 모델 → GPT에 비해 BERT는 변형 모델이 매우 많음
- 학습에 전체 데이터의 15%만 사용 → scale을 높여도 계산량 대비 학습 효율이 높지 않음
- 반면 GPT는 생성모델이기 때문에 데이터를 많이 사용할수록 더 정확한 예측이 가능함

2. 논문 리뷰
논문명 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
저자명 : Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
✏️ 논문 내용 정리
- BERT 고안 배경
: 이때까지의 PLM은 unidirectional language models을 pre-train 모델로 사용, 단방향 구조의 pre-trained 모델은 양방향 context가 모두 중요한 task에서 좋은 성능을 보이지 못함
- BERT와 이전 모델의 차이점
" BERT uses masked language models to enable pre-trained deep bidirectional representations "
: deep bidirectional Transformer를 pre-training함으로써 양방향 context를 모두 고려하는 deep bidirectional representations를 학습할 수 있음
- BERT의 구조
= multi-layer bidirectional Transformer encoder
① pre-training : pre-train BERT using two unsupervised tasks
- Masked LM (MLM) : input 토큰들 중 일정 비율의 토큰을 무작위하게 mask한 후 예측
- Next Sentence Prediction (NSP) : setence A 뒤에 sentence B가 올 수 있는지 없는지 예측
② fine-tuning : task-specific labeled data를 이용해 pre-trained BERT 모델의 파라미터 fine-tuning
- 논문에서 보인 모델 특성
① BERT를 11가지 NLP task에서 fine-tuning한 실험 결과 모두 이전 모델들에 비해 성능이 좋음
② pre-training objectives MLM과 NSP을 사용하는 것이 BERT 성능 향상에 큰 영향을 미침
③ pre-trained 모델의 크기가 커질수록 fine-tuning의 정확도가 향상
모델이 충분히 사전학습 된다면 labeled data의 수가 적은 downstream tasks에서도 좋은 성능을 보임
▶ 0. Abstract
- 이전 모델들과 달리, pre-train deep bidirectional representations을 학습
- 모든 layers에서 left와 right context를 모두 고려하는 방식
- pre-trained BERT 모델에 하나의 추가적인 output layer만 추가함으써 fine-tuning이 가능
- 실질적인 아키텍처 수정없이도 광범위한 NLP task에서 sota 모델을 학습시킬 수 있음
- 11개의 자연어 처리 작업에서 새로운 sota 결과를 달성
▶ 1. Introduction
1) 기존 fine-tuning 방식과 한계
- PLM(Pre-trained Language Model)은 많은 NLP task에서 성능 향상에 효과적임
- pre-trained language representations를 downstream task로 transfer하는 2가지 방법
- feature-based approach
: pre-trained representations(word embedding)을 task-specific 아키텍처의 추가적인 feature로 사용하는 방법 - fine-tuning approach
: pre-trained 모델의 모든 파라미터를 사용하고 task-specific 파라미터는 최소한으로 사용하여 fine-tuning하는 방법으로, GPT가 이 접근방식에 해당 - 2가지 방식 모두 pre-train에서 동일한 objective를 사용하며
representations를 학습하기 위해 unidirectional language model을 사용
- unidirectional standard language models이 pre-trained representations의 효과를 제한
- 이전 데이터들만 사용하여 학습하는 단방향 구조의 pre-trained 모델은 양방향 context가 모두 중요한 token-level task에서 좋은 성능을 보이지 못하게 됨
- 예) GPT는 Transformer attention layer에서 이전 stage의 정보만 사용할 수 있는 left-to-right architecture
2) BERT : Bidirectional Encoder Representations from Transformers
" BERT uses masked language models to enable pre-trained deep bidirectional representations "
= masked language model(MLM)을 pre-training objective로 사용함으로써
deep bidirectional Transformer를 pre-training할 수 있게 만든 모델
= 양방향 context를 모두 고려하는 deep bidirectional representations를 학습할 수 있는 모델
= unidirectional pre-trained representations의 한계를 해결
- masked language model(MLM)
: 입력에서 일부 토큰을 무작위로 masking한 후
주변 context만을 사용해서 masked word의 원래 단어를 예측
→ left + right context를 모두 고려하는 representations을 학습
- MLM과 함께 next sentence prediction(NSP) task도 사용하여 text-pair representation을 pre-training
3) 논문의 의의
- language representations을 위한 bidirectional pre-training의 중요성을 보임
- pre-trained representations가 task-specific 아키텍처를 고도로 엔지니어링할 필요성을 낮춤
▶ 2. Related Work
2.1 Unsupervised Feature-based Approaches
- pre-trained word embedding parameters from unlabeled text
- left-to-right language modeling objectives로 word embeddings를 사전학습하는 방식
- ELMo : left-to-right LM과 right-to-left LM에서 각각 left-to-right representations와 right-to-left representations를 추출한 후 두 representations를 결합하여 context-sensitive features를 얻음
2.2 Unsupervised Fine-tuning Approaches
- pre-trained encoders which produce contextual token representations from unlabeled text
- contextual representations을 생성해주는 encoder를 사전학습하는 방식
- 파라미터 수가 적다는 장점, GPT는 이 접근 방식으로 sota를 달성
2.3 Transfer Learning from Supervised Data
- NLI(Natural Language Inference)나 MT(Machine Translation)과 같이 대규모 데이터셋을 이용한 지도학습에서 전이학습이 효과적임을 보여주는 이전 연구가 존재
▶ 3. BERT
1) BERT 학습 과정
pre-training :
the model is trained on unlabeled data over different pre-training tasks
fine-tuning :
the BERT model is first initialized with the pre-trained parameters,
and all of the parameters are fine-tuned using labeled data from the downstream tasks
- 각각의 downstream task마다 서로 다른 fine-tuned models 학습
- BERT는 unified architecture → pre-trained model과 fine-tuned downstream model 큰 구조적 차이가 없음
2) Model Architecture
- multi-layer bidirectional Transformer encoder
- L : the number of layers
- H : the hidden size
- A : the number of self-attention heads
- BERT_BASE : L=12, H=768, A=12, Total Parameters=110M
(OpenAI GPT와 비교하기 위해 동일한 model size로 설정) - BERT_LARGE : L=24, H=1024, A=16, Total Parameters=340M
3) Input/Output Representations
- WordPiece embeddings, 30,000 token vocabulary 이용
- Sentence = Span of contiguous Text = Single Sentence이거나 Sentence 쌍을 하나로 묶은 형태
- sentence 쌍을 하나로 묶는 경우 두 sentence를 구분하기 위해
① 두 문장 사이에 [SEP] 토큰을 추가하고
② 모든 토큰에 문장 A에 속하는지 문장 B에 속하는지를 나타내는 임베딩을 추가

- [CLS] : 모든 sequence의 시작에 추가되는 토큰
- [SEP] : 연결된 sentence pairs 사이를 구분하는 토큰
- E : input embedding
- C : the final hidden vector of the special [CLS] token
- T_i : the final hidden vector for the i-th input token
∴ BERT input representation
= Token embedding + Segment embedding + Position embedding
- Token embedding : 각 token에 대한 embedding
- Segment embedding : 해당 token이 어느 sentence에 포함되어있는지 알려주는 embedding
- Position embedding : Transformer 구조에서 사용되는, 위치 정보를 담고 있는 embedding

▶ 3.1 Pre-training BERT
- pre-train BERT using two unsupervised tasks
- pre-training corpus : BooksCorpus (800M words), Wikipedia (2,500M words)
1) Task #1: Masked LM
- input 토큰들 중 일정 비율의 토큰을 무작위하게 mask한 후 mask된 토큰을 예측하는 과정
- mask 토큰에 대응하는 final hidden vectors를 softmax에 적용해 가장 확률이 높은 토큰으로 예측
- 이 논문에선 각 문장에 있는 WordPiece tokens을 15% 비율로 무작위 mask
- 이때 pre-training에서 사용한 [MASK] token이 fine-tuning에는 존재하지 않아 불일치 문제 발생
- 15%의 mask token들을 3가지 방법으로 사용 (모두 예측의 대상임)
- 80% : [MASK] 토큰으로 변경
- 10% : 임의의 다른 토큰으로 대체
- 10% : 기존의 토큰을 그대로 사용
- 예시 : my dog is hairy 문장에서 'hairy'를 mask
→ my dog is <MASK> / my dog is apple / my dog is hairy
2) Task #2: Next Sentence Prediction (NSP)
- setence A 뒤에 sentence B가 올 수 있는지 없는지 예측하는 binary next sentence-prediction
- 모델이 sentence relationships를 학습하기 위해 진행
- pre-training example에서 두 sentences A와 B 선택
- 50% : A와 B가 관련된 문장, A뒤에 B가 따라오는 문장, 'IsNext'라고 labeling
- 50% : A와 B가 관련없는 문장, 무작위 선택, 'NotNext'라고 labeling
→ [CLS] A [SEP] B 형태로 이어 붙혀 input sequence로 사용
→ [CLS] token의 final hidden vector C를 feed-forward network에 통과시키고
softmax에 넣어 isNext와 NotNext에 대한 확률 값 계산
* [CLS] token의 final hidden vector C
: 문장의 전체 의미를 요약하는 벡터, sequence의 결합된 의미를 가지는 역할
▶ 3.2 Fine-tuning BERT
- pre-trained BERT 모델에 task-specific labeled data를 넣어 파라미터를 fine-tuning
- classification tasks : [CLS] token의 final hidden vector C를 output layer에 입력하여 fine-tuning
Natural Language Inference, sentiment analysis - token-level tasks : final layer의 token representations를 output layer에 입력하여 fine-tuning
sequence tagging, question answering)

▶ 4. Experiments
- BERT를 11가지 NLP task에서 fine-tuning한 실험 결과
▶ 4.1 GLUE
- GLUE task를 이용해 fine-tuning 된 BERT model의 성능 평가
- 8개 task : MNLI, QQP, QNLI, STS-B, MRPC, RTE, SST-2, CoLA
- classification task에서만 label의 개수에 따른 layer weights 파라미터 추가
- batch size = 32 / epochs = 3
- learning rate = [5e-5, 4e-5, 3e-5, 2e-5]

- BERT_LARGE와 BERT_BASE 모두 GLUE의 모든 task에서 기존 모델보다 좋은 성능을 보이며 새로운 sota 달성
- BERT_LARGE가 BERT_BASE에 비해 훨씬 더 좋은 성능을 보였으며, 특히 학습 데이터의 크기가 작은 경우 BERT_LARGE 성능이 더 좋음
* GLUE(General Language Understanding Evaluation) benchmark
: 인간의 언어 능력을 인공지능이 얼마나 따라왔는지 정량적 성능지표를 만들어 NLP task의 평가체계를 표준화한 것이다. 총 9개의 NLP task로 언어모델의 성능을 평가한다.
- The Corpus of Linguistic Acceptability(CoLA) : '언어학적으로 수용 가능한 문장인지' 판별 The Stanford Sentiment
- Treebank(SST-2) : 감성 분석을 통하여 문장의 긍정/부정 분류
- The Microsoft Research Paraphrase Corpus(MRPC) : 문장 쌍이 의미론적으로 동일한지 분류
- The Quora Question Pairs dataset(QQP) : 두 개의 질문이 의미론적으로 동일한지 이진분류
- The Semantic Textual Similarity Benchmark(STS-B) : 문장 쌍에 대한 유사도를 1~5로 사람이 라벨링한 데이터를 이용해 자연어 모델이 유사도 예측
- The Multi-Genre Natural Language Corpus(MNLI) : 전제(premise)와 가설(hypothesis) 간의 관계를 3가지(entailment, contradiction, neutral)로 예측
- The Stanford Question Answering Dataset(QNLI) : context sentence이 질문에 대한 답을 담고 있는지 분류
- The Recognizaing Textual Entailment(RTE) : MNLI에서 neutral과 contradiction을 모두 not-entailment 라벨로 만들어 이진분류로 변형
- Winograd NLI(WNLI) : 대명사가 포함된 문장을 읽고 대명사가 가리키는 대상을 리스트에서 고르는 문제
(참고 링크) https://velog.io/@raqoon886/GLUE#1-what-is-glue
▶ 4.2 SQuAD v1.1
- SQuAD를 이용한 Question Answering task로 fine-tuning 된 BERT model의 성능 평가
- SQuAD(Stanford Question Answering Dataset) : 100,000개의 question/answer 쌍 데이터셋
- 'question + answer가 포함되어 있는 passage'가 주어지면 passage에서 어디부터 어디까지가 answer에 해당하는지 예측하는 모델을 학습
- S : start vector / E : end vector
- i : answer의 시작이 될 확률이 가장 높은 토큰의 index
j : answer의 끝이 될 확률이 가장 높은 토큰의 index
question(A)과 passage(B) 두 sentence를 하나의 sequence로 연결
→ passage 내의 token이 answer의 시작/끝 token이 될 확률을 구함
- token이 answer의 시작이 될 확률 = softmax(token T_i와 S의 내적)
- token이 answer의 끝이 될 확률 = softmax( token T_i와 S의 내적)

→ 시작/끝 token이 될 확률이 가장 높은 토큰의 index i/j 계산
→ span score = S⋅T_i + E⋅T_j
→ 가장 높은 score를 가진 span을 최종 prediction으로 출력
- batch size = 32 / epochs = 3 / learning rate = 5e-5
- objective = correct start and end position의 log-likelihood의 합
- 학습 결과 BERT가 sota 점수를 달성함

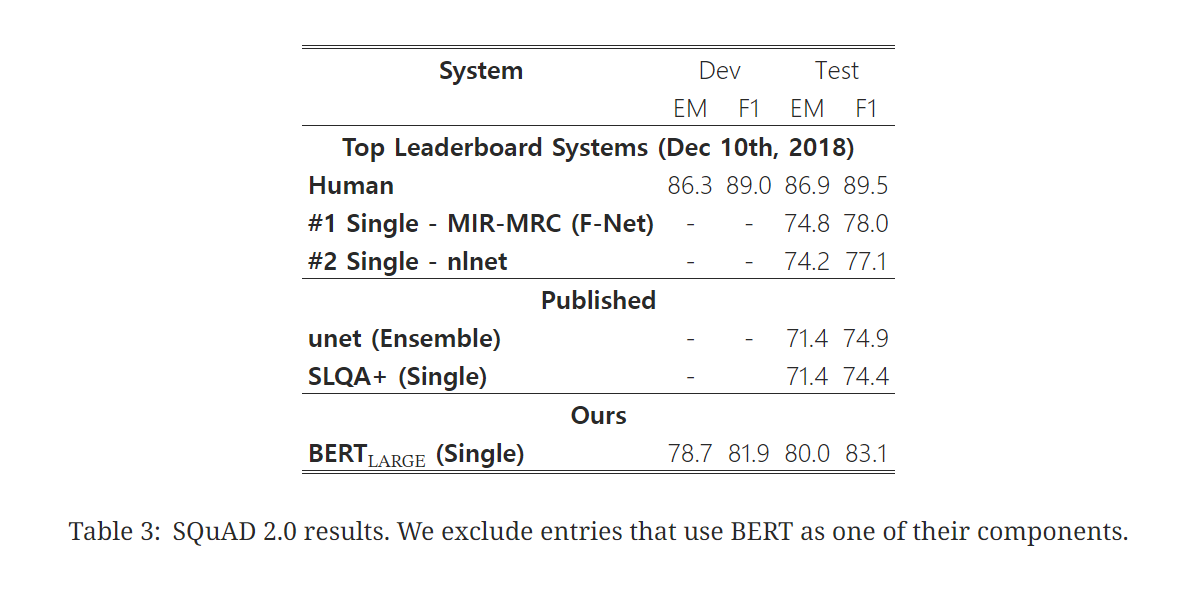
▶ 4.3 SQuAD v2.0
- 주어진 passage에 answer이 존재하지 않을 가능성을 추가하여 SQuAD v1.1를 확장한 task
- SQuAD v1.1 BERT model에 answer가 존재하는지에 대한 여부를 고려하는 과정을 추가
- answer가 존재하지 않는 것 = [CLS] 토큰으로 시작하고 끝나는 answer span
- no-answer span의 score와 best non-null span의 score를 비교

- 학습 결과 확장된 버전의 task에서도 BERT의 성능이 가장 높음
▶ 4.4 SWAG
- The Situations With Adversarial Generations (SWAG) dataset
: 근거 있는 추론을 평가할 수 있는 113,000개의 문장쌍 데이터셋
- 문장이 주어졌을 때, 보기로 주어진 4개의 문장 중 가장 잘 어울리는 문장을 찾는 task
- 보기 문장 4가지를 각각 B로 사용해 주어진 문장(A)와 연결함으로써 4개의 input sequence를 생성
- batch size = 16 / epochs = 3 / learning rate = 2e-5
- 학습 결과 BERT의 성능이 매우 좋음

▶ 5. Ablation Studies
▶5.1 Effect of Pre-training Tasks
- BERT의 2가지 pre-training objectives MLM과 NSP의 중요성을 평가함으로써
BERT의 deep bidirectionality의 중요성을 보임
- No NSP : MLM은 사용, NSP 미사용
LTR & No NSP : MLM 대신 left-to-right LM 사용, NSP 미사용
- NSP를 미사용한 경우, NSP를 미사용하고 MLM 대신 LTR을 사용하는 경우 모두 모든 task에서 성능 하락

▶ 5.2 Effect of Model Size
- 모델의 크기가 fine-tuning의 정확도에 미치는 영향을 확인
- number of layers(L), hidden units size(H), number of attention heads(A) 값에 변화를 줌

- 실험 결과 모든 task에 대해 model size가 커질수록, 성능도 함께 향상
- downstream task의 dataset 크기가 매우 작고 pre-training task와 상당히 다른 형태인 task(MRPC)에 대해서도 크기가 큰 모델이 더 좋은 성능을 보임
- 모델이 충분히 사전학습 된다면, 매우 크기가 큰 모델로 확장하는 것이 작은 규모의 task에서 큰 개선으로 이어질 수 있음을 보여줌
- 모델이 downstream tasks에 directly하게 fine-tuning되고 매우 적은 수의 추가적인 파라미터만 사용할 때, 데이터 규모가 매우 적은 downstream tasks에서도 표현력이 뛰어난 pre-trained representations를 얻을 수 있다는 가설 제시
▶ 5.3 Feature-based Approach with BERT
- 논문에서 BERT는 fine-tuning approach를 사용하고 있으나 feature-based approach를 사용한 경우에도 장점이 있음
- transformer encoder로 표현하기 힘들어 task-specific architecure가 추가되어야하는 task인 경우
- computational benefit : pre-trained된 features를 고정적으로 사용하면서 연산량을 줄일 수 있음
- NER(Named Entity Recognition) task에 대해서 feature-based approach를 적용하여 두 approach 방식의 성능 비교
- feature-based approach는 fine-tuning을 거치지 않고, BERT의 output을 bidirectional LSTM의 input embedding으로 바로 사용
- 실험 결과 fine-tuning approach의 성능이 더 좋긴 하지만, feature-based approach와의 차이가 적음
- BERT는 fine-tuning approach와 feature-based approach 모두에서 효과적임

▶ 6. Conclusion
- 언어모델에서 unsupervised pre-training와 transfer learning 매우 중요
- 이 논문은 deep unidirectional 아키텍처를 사용함을써 동일한 pre-trained 모델이 광범위한 NLP task를 더 성공적으로 처리할 수 있도록 하는데 기여
Reference
https://wikidocs.net/115055
https://happy-obok.tistory.com/23
https://velog.io/@mertyn88/BERT%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C#bert-%EB%93%B1%EC%9E%A5%EB%B0%B0%EA%B2%BD
https://brunch.co.kr/@harryban0917/280
https://gbdai.tistory.com/50
https://m.blog.naver.com/kisooofficial/223056178545
https://velog.io/@pre_f_86/BERT-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0#3-bert