
working_helen
[데이터 전처리] Encoding 인코딩 본문
데이터 전치리 과정에서 학습한 내용 중 첫 번째로 Encoding 인코딩 방법에 대해 공부해본다.
1. 인코딩이란?
2. One-Hot Encoding 원 핫 인코딩
3. Binary Encoding 바이너리 인코딩
4. Label Encoding 라벨 인코딩
5. Ordinal Encoding 오디널 인코딩
1. 인코딩이란?
인코딩 = 자연어 or 범주형 데이터를 수치적 데이터로 변환해주는 작업
: 기계는 수치형 데이터만을 처리할 수 있기 때문에 자연어나 범주형 데이터를 처리하기 위해선 이를 수치형 데이터로 변환시켜주는 작업이 필요하다.
- 다양한 인코딩 방법 중 데이터의 특성에 맞춰 정보의 손실을 최소화할 수 있는 적합한 방법을 적용하는 것이 중요
- category_encoders은 범주형 데이터(Categorical data)을 인코딩하는 함수를 제공
1) 범주형 데이터의 종류
명목형 데이터 (Nominal) : 항목 간 순서가 없는 데이터 (예. 성별 남/여)
순서형 데이터 (Ordinal) : 항목 간 순서가 있는 데이터 (예. 학점 A/B/C/D/F)

2) 인코딩 방법의 종류
- One-Hot Encoding
- Binary Encoding
- Label Encoding
- Ordinal Encoding
- Helmert Encoding
- Frequency Encoding
- Mean Encoding
- Weight of Evidence Encoding
- Probability Ratio Encoding
3) Embedding 임베딩 vs 인코딩 Encoding
- 임베딩이란 자연어와 이미지처럼 수치화되어 있지 않는 데이터를 특징 추출을 통해 컴퓨터가 처리할 수 있는 벡터 형태로 수치화해주는 방법
- 임베딩을 통해 단어를 벡터화 => 인코딩을 통해 단어 벡터를 수치화
- 인코딩을 임베딩 과정에 활용할 수 있다. 대표적으로 짧은 문장들에 대해선 One-hot Encoding을 사용한 임베딩이 자주 사용된다.
※ 참고 : train data와 test data에서 encoding 차이
- train data에서 fit을 통해 인코딩 사전을 만들고, transform으로 변형까지 진행
- test data에서는 train에서 만든 인코딩 사전을 이용해 transform만 진행한다.
# 인코더 생성
encoder = OneHotEncoder()
# train data : 인코딩 사전 학습 (대응 관계 생성)
train = encoder.fit_transform(train)
# test data : 이미 만든 인코더를 그대로 적용
test = encoder.transform(test)
2. One-Hot Encoding 원 핫 인코딩
- 0과 1을 사용해 주어진 데이터가 범주의 어떤 항목에 속하는지 표현한다. 데이터가 속하는 항목인 경우 1을, 그렇지 않은 항목인 경우 0을 성분으로 두어 어떤 항목에 속하는지 표현한다.
- 항목의 개수와 같은 크기의 벡터를 사용한다. 즉 범주형 변수의 항목이 N개라면 1개의 변수가 N개의 변수로 전환된다.
- 가장 널리 사용되는 인코딩 기법으로, 예를 들어 회귀분석에서 범주형 종속 변수를 수치화할 때 사용되는 것이 있다.
- 단점 : 범주가 너무 넓거나 복잡한 경우 0이 대부분인 매우 sparse한 형태의 고차원 벡터로 표현되기 때문에 메모리 낭비 및 계산 복잡도가 커져 성능이 저해다.
(참고 post : 2023.08.01 - [deep daiv./추천시스템 스터디] - [추천시스템 스터디] 1주차 : 콘텐츠 기반 필터링)
- OneHotEncoder 클래스를 사용하거나 pd.get_dummies를 사용해 구현할 수 있다.
# 방법 1 : OneHotEncoder 클래스 이용
from category_encoders import OneHotEncoder
OneHot = OneHotEncoder(cols='행정동명', use_cat_names=True)
OneHot_df = OneHot.fit_transform(df)
# 방법 2 : pd.get_dummies method 이용
OneHot_df_3 = pd.get_dummies(df, columns = ['행정동명'], dtype=int)
OneHot_df_3
3. Binary Encoding 바이너리 인코딩
- 범주형 변수의 항목들을 이진법으로 구분할 수 있도록 변환해주는 인코딩 방법이다.
- 원핫 인코딩과 유사하게 1과 0으로만 값을 표현하지만, 1 자체가 해당 항목에 속한다는 의미를 가지진 않는다. encoding 결과의 이진법 표현이 같은 경우, 기존 범주형 변수에서 같은 항목에 속했던 데이터라고 해석할 수 있다.
- 1개의 encoding 변수 추가는 표현가능한 항목 수의 수를 2배로 늘려준다.
(예 : 4개의 encoding 변수로 변환하면 최대 16개 항목을 구분하여 표현할 수 있다.)
- 원핫 인코딩의 단점 개선 : 인코딩 과정에서 새롭게 생성되는 변수가 적어 학습 속도가 더 빠르다.
- BinaryEncoder 클래스를 사용해 구현할 수 있다.
from category_encoders import BinaryEncoder
Binary = BinaryEncoder(cols='행정동명')
Binary_df = Binary.fit_transform(df)
4. Label Encoding 라벨 인코딩
- 문자열 데이터의 각 항목을 정수에 대응시켜 수치형으로 인코딩하는 방법
- 문자열 변수의 항목이 N개일 때, 각 항목에 0~N-1의 숫자를 부여하는 인코딩 방식이다.
- 영어는 알파벳 순으로, 한글은 ㄱㄴㄷ 순으로 0부터 대응시킨다.
- 단점 : 실제로는 범주간 순서관계가 없더라도 컴퓨터가 순서관계가 있는 것으로 인식할 수 있다. 예를 들어, 2가 1의 2배라고 생각하는 등 부여된 숫자들 사이에서는 관계성이 자동적으로 부여될 수 있다.
- sklearn의 LabelEncoder 클래스를 이용해 구현할 수 있다.
from sklearn.preprocessing import LabelEncoder
Label = LabelEncoder()
df["행정동명_인코딩"] = Label.fit_transform(Label_df["행정동명"])
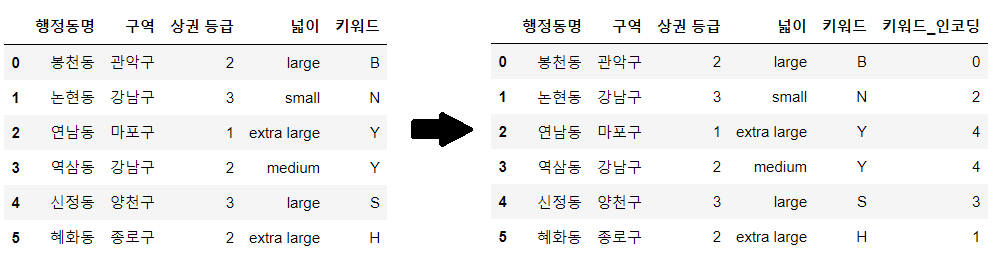
5. Ordinal Encoding 오디널 인코딩
- 순서형 변수를 1~N의 숫자로 인코딩 하는 방법이다.
- 적용되는 범주가 명확하고 자연스러운 순서를 갖는다고 가정한다.
- 라벨 인코딩과 유사하게 각 범주에 1~N의 숫자를 부여하는데, 이때 순서 정보를 포함한다는 차이점이 있다.
- 하나의 인코딩 변수로만 대체되기 때문에 원핫 인코딩에 비해 요구되는 메모리나 계산 복잡도가 적다.
- 단점 : 순서형 변수가 아닌 경우에도 컴퓨터가 인코딩 결과 변수에 자동적으로 (강제적으로) 순서 관계를 부여하여 인식하기 때문에 이로 인한 오류나 성능 저하가 나타날 수 있다. 따라서 데이터에 의미 있는 순서가 없는 경우 적합하지 않다.
- OrdinalEncoder 클래스 혹은 map 함수를 사용해 구현할 수 있다.
- mapping 속성 : mapping을 사용하지 않으면 인코더가 임의로 순서를 부여한다. (보통 먼저 나온 항목부터 오름차순으로 값을 부여한다) 정확한 순서 부여를 위해 mapping 조건을 설정하여 사용하는 것이 좋다.
# 방법 1. OrdinalEncoder 이용
from category_encoders import OrdinalEncoder
size_mapping = [{
"col":"넓이",
"mapping": {
'small': 1,
'medium': 2,
'large': 3,
'extra large' : 4,
'NA': np.nan
}}]
Ordinal = ce.OrdinalEncoder(mapping = size_mapping, return_df=True)
Ordinal_df = Ordinal.fit_transform(df)
# 방법 2. map 함수 이용
size_dict = {'small': 1, 'medium': 2, 'large': 3, 'extra large' : 4}
Ordinal_df["넓이_인코딩"] = df['넓이'].map(size_dict)
Jupyter Notebook
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import plotly.express as px
from plotly.subplots import make_subplots
plt.rc('font', family='NanumBarunGothic')
import warnings
warnings.filterwarnings(action='ignore')
final = pd.read_csv(path+'/데이터 전처리/찐찐최종.csv', encoding = 'cp949')
final.head(3)
| Unnamed: 0.1 | Unnamed: 0 | 상호명 | 시군구명 | 행정동명 | 도로명주소 | 위도 | 경도 | 폐업여부 | 소득분위 | ... | 반경500_대학개수 | 반경1000_대학개수 | index | 상권활성화지수등급 | 상권활성화지수 | 매출지수 | 인프라지수 | 가맹점지수 | 인구지수 | 금융지수 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | (주)도피오커피서남병원인 | 양천구 | 신정3동 | 서울특별시 양천구 신정이펜1로 20(신정동, 서남병원) | 37.511895 | 126.833157 | y | 7 | ... | 0 | 0 | 24 | 9.26 | 1 | 3.00 | 6.45 | 0.36 | 12.50 | 2.51 |
| 1 | 1 | 1 | 커피나무 | 강남구 | 논현2동 | 서울특별시 강남구 언주로148길 14(논현동,2층) | 37.520407 | 127.036095 | y | 8 | ... | 0 | 0 | 415 | 26.56 | 10 | 10.82 | 14.35 | 2.04 | 17.63 | 8.70 |
| 2 | 2 | 2 | (주)프라빈 | 강남구 | 역삼1동 | 서울특별시 강남구 테헤란로22길 11(지상9층 역삼동) | 37.499232 | 127.035300 | y | 7 | ... | 0 | 0 | 423 | 31.32 | 10 | 14.21 | 17.25 | 4.66 | 21.81 | 8.82 |
3 rows × 35 columns
final.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20886 entries, 0 to 20885
Data columns (total 35 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0.1 20886 non-null int64
1 Unnamed: 0 20886 non-null int64
2 상호명 20886 non-null object
3 시군구명 20886 non-null object
4 행정동명 20886 non-null object
5 도로명주소 20886 non-null object
6 위도 20886 non-null float64
7 경도 20886 non-null float64
8 폐업여부 20886 non-null object
9 소득분위 20886 non-null int64
10 가구수 20886 non-null int64
11 1년 생존율 20886 non-null float64
12 3년 생존율 20886 non-null float64
13 5년 생존율 20886 non-null float64
14 최근 10년 기준 평균영업기간 20886 non-null float64
15 최근 30년 기준 평균영업기간 20886 non-null float64
16 임대시세 20886 non-null float64
17 유동인구 20886 non-null int64
18 주거인구 20886 non-null int64
19 직장인구 20886 non-null int64
20 방범지수 20886 non-null int64
21 반경500_카페개수 20886 non-null int64
22 반경500_지하철역개수 20886 non-null int64
23 반경500_정류장개수 20886 non-null int64
24 반경500_공공기관개수 20886 non-null int64
25 반경500_대학개수 20886 non-null int64
26 반경1000_대학개수 20886 non-null int64
27 index 20886 non-null int64
28 상권활성화지수등급 20886 non-null float64
29 상권활성화지수 20886 non-null int64
30 매출지수 20886 non-null float64
31 인프라지수 20886 non-null float64
32 가맹점지수 20886 non-null float64
33 인구지수 20886 non-null float64
34 금융지수 20886 non-null float64
dtypes: float64(14), int64(16), object(5)
memory usage: 5.6+ MB
1. 행정동명 encoding
"행정동명" 범주형 열 > 8가지의 더미변수로 표현하는 행정동 encoder로 변환¶
#!pip install category_encoders
import category_encoders as ce
encoder = ce.BinaryEncoder(cols=["행정동명"])
df_binary = encoder.fit_transform(final["행정동명"])
final = pd.concat([final, df_binary], axis=1)
encoder
BinaryEncoder(cols=['행정동명'],
mapping=[{'col': '행정동명',
'mapping': 행정동명_0 행정동명_1 행정동명_2 행정동명_3 행정동명_4 행정동명_5 행정동명_6 행정동명_7 행정동명_8
1 0 0 0 0 0 0 0 0 1
2 0 0 0 0 0 0 0 1 0
3 0 0 0 0 0 0 0 1 1
4 0 0 0 0 0 0 1 0 0
5 0 0 0 0 0 0 1 0 1
... ... ... ... ... ... ... ... ... ...
420 1 1 0 1 0 0 1 0 0
421 1 1 0 1 0 0 1 0 1
422 1 1 0 1 0 0 1 1 0
-1 0 0 0 0 0 0 0 0 0
-2 0 0 0 0 0 0 0 0 0
[424 rows x 9 columns]}])On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
BinaryEncoder(cols=['행정동명'],
mapping=[{'col': '행정동명',
'mapping': 행정동명_0 행정동명_1 행정동명_2 행정동명_3 행정동명_4 행정동명_5 행정동명_6 행정동명_7 행정동명_8
1 0 0 0 0 0 0 0 0 1
2 0 0 0 0 0 0 0 1 0
3 0 0 0 0 0 0 0 1 1
4 0 0 0 0 0 0 1 0 0
5 0 0 0 0 0 0 1 0 1
... ... ... ... ... ... ... ... ... ...
420 1 1 0 1 0 0 1 0 0
421 1 1 0 1 0 0 1 0 1
422 1 1 0 1 0 0 1 1 0
-1 0 0 0 0 0 0 0 0 0
-2 0 0 0 0 0 0 0 0 0
[424 rows x 9 columns]}])df_binary
| 행정동명_0 | 행정동명_1 | 행정동명_2 | 행정동명_3 | 행정동명_4 | 행정동명_5 | 행정동명_6 | 행정동명_7 | 행정동명_8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20881 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 |
| 20882 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| 20883 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 20884 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
| 20885 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
20886 rows × 9 columns
final에 행정동 encoder 8가지 열이 추가되었다.
final.head(3)
| Unnamed: 0.1 | Unnamed: 0 | 상호명 | 시군구명 | 행정동명 | 도로명주소 | 위도 | 경도 | 폐업여부 | 소득분위 | ... | 금융지수 | 행정동명_0 | 행정동명_1 | 행정동명_2 | 행정동명_3 | 행정동명_4 | 행정동명_5 | 행정동명_6 | 행정동명_7 | 행정동명_8 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | (주)도피오커피서남병원인 | 양천구 | 신정3동 | 서울특별시 양천구 신정이펜1로 20(신정동, 서남병원) | 37.511895 | 126.833157 | y | 7 | ... | 2.51 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 1 | 1 | 커피나무 | 강남구 | 논현2동 | 서울특별시 강남구 언주로148길 14(논현동,2층) | 37.520407 | 127.036095 | y | 8 | ... | 8.70 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 2 | 2 | (주)프라빈 | 강남구 | 역삼1동 | 서울특별시 강남구 테헤란로22길 11(지상9층 역삼동) | 37.499232 | 127.035300 | y | 7 | ... | 8.82 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
3 rows × 44 columns
DF 정리 : 학습용 칼럼만 남기고 정리
기초 EDA를 통해 선정한 모델에 포함시키지 않을 변수를 삭제
final : 변수 미삭제 상태
final1 : 변수 삭제 상태
final.drop(['Unnamed: 0.1','Unnamed: 0','index','상호명','시군구명','행정동명','도로명주소','위도','경도'],axis=1,inplace=True)
# 상권 활성화 관련 지표 칼럼명 병경
final.rename(columns={'상권활성화지수등급' : 'tmp'}, inplace=True)
final.rename(columns={'상권활성화지수' : '상권활성화지수등급'}, inplace=True)
final.rename(columns={'tmp' : '상권활성화지수'}, inplace=True)
최종 final Datraframe
final.head(3)
| 폐업여부 | 소득분위 | 가구수 | 1년 생존율 | 3년 생존율 | 5년 생존율 | 최근 10년 기준 평균영업기간 | 최근 30년 기준 평균영업기간 | 임대시세 | 유동인구 | ... | 금융지수 | 행정동명_0 | 행정동명_1 | 행정동명_2 | 행정동명_3 | 행정동명_4 | 행정동명_5 | 행정동명_6 | 행정동명_7 | 행정동명_8 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | y | 7 | 16957 | 75.0 | 75.0 | 25.0 | 2.8 | 3.3 | 167322.0 | 33003 | ... | 2.51 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | y | 8 | 11676 | 72.3 | 29.8 | 21.3 | 2.6 | 3.9 | 166981.0 | 80595 | ... | 8.70 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | y | 7 | 23983 | 67.6 | 42.6 | 33.3 | 2.7 | 4.0 | 182473.0 | 72621 | ... | 8.82 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
3 rows × 35 columns
최종 final1 Datraframe
final1 = final.drop(['1년 생존율','5년 생존율','최근 30년 기준 평균영업기간', '주거인구','직장인구',
'반경500_대학개수','상권활성화지수등급','매출지수','인프라지수','가맹점지수','인구지수','금융지수'],axis=1)
final1.head(3)
| 폐업여부 | 소득분위 | 가구수 | 3년 생존율 | 최근 10년 기준 평균영업기간 | 임대시세 | 유동인구 | 방범지수 | 반경500_카페개수 | 반경500_지하철역개수 | ... | 상권활성화지수 | 행정동명_0 | 행정동명_1 | 행정동명_2 | 행정동명_3 | 행정동명_4 | 행정동명_5 | 행정동명_6 | 행정동명_7 | 행정동명_8 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | y | 7 | 16957 | 75.0 | 2.8 | 167322.0 | 33003 | 2 | 10 | 0 | ... | 9.26 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | y | 8 | 11676 | 29.8 | 2.6 | 166981.0 | 80595 | 3 | 79 | 0 | ... | 26.56 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | y | 7 | 23983 | 42.6 | 2.7 | 182473.0 | 72621 | 4 | 140 | 1 | ... | 31.32 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
3 rows × 23 columns
범주형 변수 / 수치형 변수 구분
x_cat_cols = final[['소득분위','상권활성화지수등급']].columns
x_num_cols = final.drop(final[x_cat_cols], axis=1).columns
x1_cat_cols = final1[['소득분위']].columns
x1_num_cols = final1.drop(final1[x1_cat_cols], axis=1).columns
표준화 Scaling
from sklearn.preprocessing import StandardScaler
# final version
x = final.drop(['폐업여부'],axis=1)
x_scaler = StandardScaler().fit_transform(x) #표준화
x_scaled = pd.DataFrame(data=x_scaler, index=x.index, columns = x.columns)
# final1 version
x1 = final1.drop(['폐업여부'],axis=1)
x1_scaler = StandardScaler().fit_transform(x1)
x1_scaled = pd.DataFrame(data=x1_scaler, index=x1.index, columns = x1.columns)
#폐업여부 "y"를 1로 변환
y = final['폐업여부'].eq('y').mul(1)
Reference
https://conanmoon.medium.com/%EB%8D%B0%EC%9D%B4%ED%84%B0%EA%B3%BC%ED%95%99-%EC%9C%A0%EB%A7%9D%EC%A3%BC%EC%9D%98-%EB%A7%A4%EC%9D%BC-%EA%B8%80%EC%93%B0%EA%B8%B0-%EC%9D%BC%EA%B3%B1%EB%B2%88%EC%A7%B8-%EC%9D%BC%EC%9A%94%EC%9D%BC-7a40e7de39d4
https://dacon.io/codeshare/4525
https://beausty23.tistory.com/223
https://dkfl8151.tistory.com/12
https://velog.io/@73syjs/Categorical-Feature-Encoing-Methods
https://contrib.scikit-learn.org/category_encoders/index.html
https://velog.io/@jiazzang/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%A0%84%EC%B2%98%EB%A6%AC-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%9D%B8%EC%BD%94%EB%94%A9Label-encoding-One-Hot-encoding
https://machinelearningmastery.com/one-hot-encoding-for-categorical-data/
https://leochoi146.medium.com/how-and-when-to-use-ordinal-encoder-d8b0ef90c28c
https://www.projectpro.io/recipes/encode-ordinal-categorical-features-in-python
'TAVE > 뿌스팅 project' 카테고리의 다른 글
| [모델링] 예측 모델 모델링 및 성능 평가 (0) | 2023.08.07 |
|---|---|
| [데이터 전처리] 설명변수 PCA (0) | 2023.08.07 |
| [데이터 전처리] EDA 및 변수 선택 (0) | 2023.08.07 |
| [데이터 수집] 데이터 수집 Workflow (0) | 2023.08.07 |
| [데이터 수집] 위도/경도 기반 지도 반경 내 데이터 (0) | 2023.08.07 |

