

working_helen
[코테 연습] Leetcode 코딩테스트 연습 MySQL Easy (2) 본문
Leetcode 코딩테스트 연습 MySQL Easy
1965. Employees With Missing Information
: report the IDs of all the employees with missing information. The information of an employee is missing if: The employee's name is missing, or The employee's salary is missing.
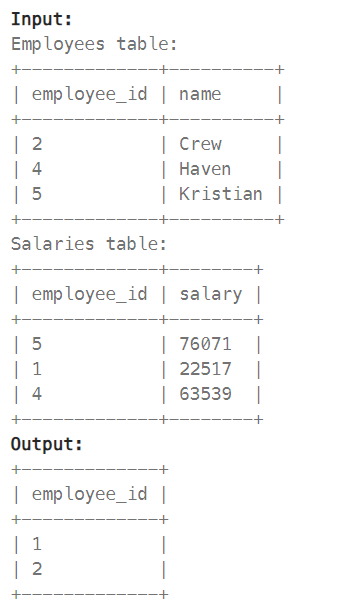
> FULL OUTER JOIN 결과 = (LEFT OUTER JOIN) UNION (RIGHT OUTER JOIN) 결과
풀이 1 : FULL OUTER JOIN
select employee_id
from Employees full outer join Salaries using(employee_id)
where name is null or salary is null
order by 1
풀이 2 : (LEFT OUTER JOIN) UNION (RIGHT OUTER JOIN)
- 주의! UNION 이후 ORDER BY 절 사용, 각 SELECT문에 따로 사용 불가능
(select employee_id
from Employees left outer join Salaries using(employee_id)
where name is null or salary is null)
union
(select employee_id
from Employees right outer join Salaries using(employee_id)
where name is null or salary is null)
order by 1
1789. Primary Department for Each Employee
: report all the employees with their primary department. For employees who belong to one department, report their only department

> 여러 조건이 중첩되어 있는 경우
풀이 1 : or로 여러 조건 연결
select employee_id, department_id
from Employee
where primary_flag = 'Y' or
employee_id in (select employee_id
from Employee
group by employee_id
having count(*) = 1)
풀이 2 : 각 조건별로 SELECT한 이후 UNION
(select employee_id, department_id
from Employee
where primary_flag = 'Y')
union
(select employee_id, min(department_id)
from Employee
group by employee_id
having count(*) = 1)
607. Sales Person
: find the names of all the salespersons who did not have any orders related to the company with the name "RED"
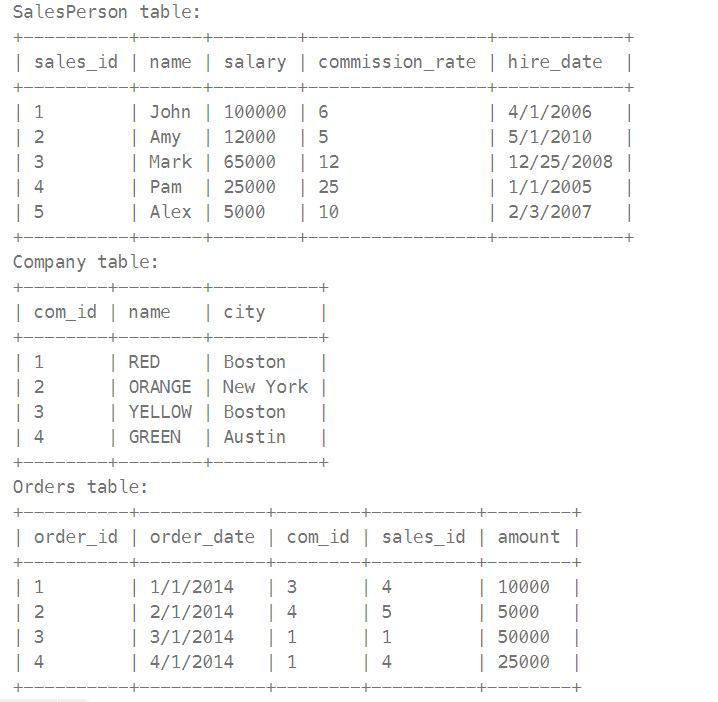
풀이 1 : NOT IN 함수 사용
- WHERE절 연관 서브쿼리
- JOIN으로 인해 서브쿼리 결과에는 NULL이 없으므로 'NOT IN (NULL, ...)' 문제 없음
select name
from SalesPerson
where sales_id not in (select distinct O.sales_id
from Orders O join Company C using (com_id)
where C.name = 'RED')
풀이 2 : NOT EXISTS 함수 사용
- WHERE절 연관 서브쿼리
- SELECT 1로 존재하면 1 반환하는 전략
select distinct S.name
from SalesPerson S
where not exists (select 1
from Orders O join Company C using (com_id)
where C.name = 'RED' and O.sales_id = S.sales_id)
풀이 3 : 집합 연산자 사용, MINUS(차집합)
select distinct name from SalesPerson
minus
select distinct S.name
from SalesPerson S left outer join Orders O using(sales_id)
left outer join Company C using (com_id)
where C.name = 'RED'
1661. Average Time of Process per Machine
: find the average time each machine takes to complete a process. The average time is calculated by the total time to complete every process on the machine divided by the number of processes that were run.
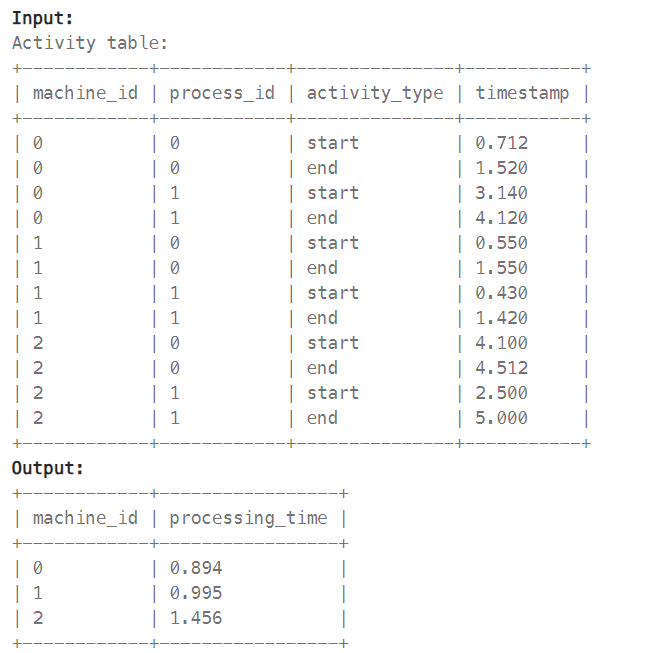
풀이 1 : WINDOW 함수 사용
- 'end', 'start' 순으로 정렬 → 'end'에서 'start'의 timestamp 값을 빼기 위해 LEAD 사용
| LAG(col) | 이전 행의 값을 가져옴 |
| LEAD(col) | 다음 행의 값을 가져옴 |
select machine_id, round(avg(total), 3) as processing_time
from (select machine_id, process_id,
timestamp-LEAD(timestamp)
over (partition by machine_id, process_id order by activity_type) as total
from Activity) A
group by machine_id
풀이 2 : self join 사용
- self join을 사용해 한 열에 있는 값을 여러 열로 분리 (Pivot과 유사하게)
- 부등호 이용해서 중복 제거
select A1.machine_id, round(avg(A2.timestamp - A1.timestamp), 3) as processing_time
from Activity A1 join Activity A2
on A1.machine_id = A2.machine_id AND A1.process_id = A2.process_id
where A1.timestamp < A2.timestamp
group by A1.machine_id
풀이 3 : PIVOT 사용
- PIVOT 결과를 새로운 테이블로 사용하는 경우
pivot 전 테이블에 대해서 서브쿼리로 묶어서 from 절에 사용
select *
from (select * from Activity)
pivot (min(timestamp) for activity_type in ('start' as start_ts, 'end' as end_ts))
- activity_type 열에 있던 값들을 새로운 열 이름으로 사용
- 각 열 이름은 activity_type열에 있던 값들로 정해지는데, 이때 이름을 as로 재정의
- 셀 값은 min(tinestamp)로 채움, min은 집계함수 사용 조건 때문에 억지로 넣은 것
select machine_id, round(avg(end_ts-start_ts), 3) as processing_time
from (select *
from (select machine_id, process_id, activity_type, timestamp
from Activity)
pivot (min(timestamp) for activity_type in ('start' as start_ts, 'end' as end_ts)
)
)
group by machine_id
586. Customer Placing the Largest Number of Orders
: find the customer_number for the customer who has placed the largest number of orders.

> 집계함수 결과가 최대/최소인 행 출력하기
풀이 1, 2
- WINDOW function, RANK / ROW_NUMBER 함수
- WINDOW 함수의 OVER절 내에서 집계함수를 직접적으로 사용할 수 없음
OVER절 내에서 집계함수 사용하려면 전체 쿼리에 GROUP BY 해주어야 함
# GROUP BY 없이 사용은 불가능
select customer_number,
rank() over(order by count(*) desc) as ranking
from Orders
# 반드시 GROUP BY 사용해주어야 함
select customer_number,
rank() over(order by count(*) desc) as ranking
from Orders
group by customer_numberselect customer_number
from (select customer_number,
rank() over(order by count(*) desc) as ranking
from Orders
group by customer_number
) A
where ranking = 1
select customer_number
from (select customer_number,
row_number() over(order by count(*) desc) as rnum
from Orders
group by customer_number
) A
where rnum = 1
풀이 3 : ROWNUM
- 출력된 데이터 기준으로 가상의 행 번호 부여
- 가상의 행 번호를 가지고 연산을 할 순 없지만, < 와 함께 사용해 출력되는 행 조절 가능
- ORDER BY 정렬 순서에 영향을 받음, WHERE절이 ORDER BY 절보다 먼저 수행되므로 서브쿼리를 사용해 ORDER BY를 먼저 실행한 후 WHERE ROWNUM으로 출력할 행 조절
# 서브쿼리로 전달하지 않으면 order by 전 테이블 상태에서 상위 3개 행 출력
select id
from person
where rownum < 3
order by heigt
# 서브쿼리로 전달해야 order by가 진행된 후 테이블 상태에서 상위 3개 행 출력
select id
from (select *
from person
order by height) A
where rownum < 3select customer_number
from (select customer_number
from Orders
group by customer_number
order by count(*) desc
) A
where rownum < 2
'외부 수업 > SQL 스터디' 카테고리의 다른 글
| [SQL 개념 정리] Database / Phase of DB design / ER model / Relational Model / SQL (0) | 2025.05.05 |
|---|---|
| [코테 연습] Leetcode 코딩테스트 연습 MySQL Easy (3) (1) | 2025.04.28 |
| [코테 연습] Leetcode 코딩테스트 연습 MySQL Easy (0) | 2025.04.14 |
| [코테 연습] 프로그래머스 코딩테스트 연습 Lv4 (3) | 2025.04.07 |
| [코테 연습] 프로그래머스 코딩테스트 연습 Lv3 (0) | 2025.03.31 |



